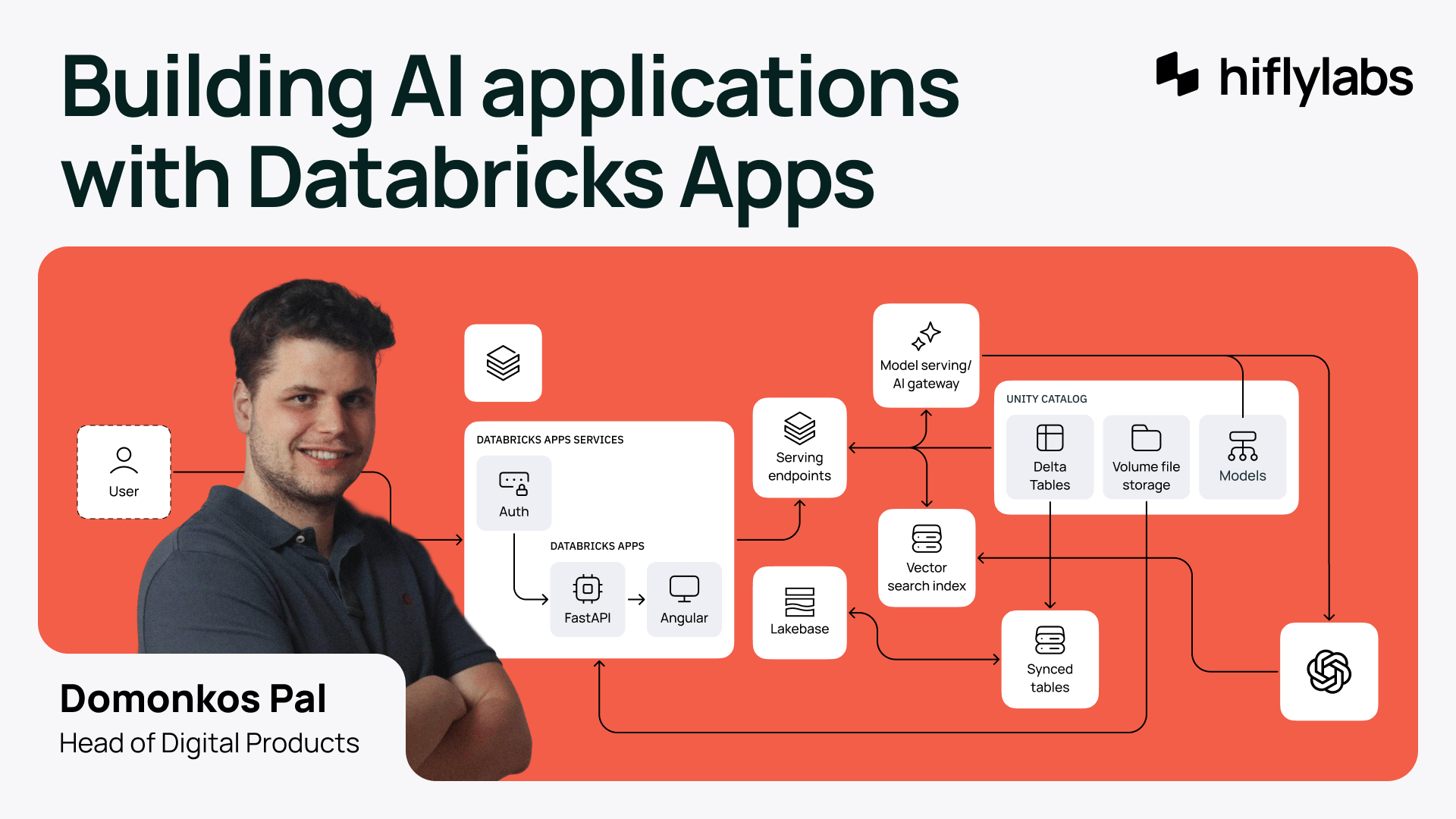
Building an AI Application with Databricks Apps in 30 Days
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.



For decades, the foundation for business intelligence and data storage rested on data warehouses. However, as new business needs emerged, data lakes became another popular option for storing big data. To spice things up, modern data warehouses and data lakes are starting to resemble one another, serving as a spark for the trending “data lake vs data warehouse” conversation.
Therefore, the big question we’re asking today is: do companies still need to include a data warehouse in their data landscape, or is a data lake the better option? Or should they use both?
Let’s find out!
When it comes to storing large amounts of data, the two most popular options today are data lakes and data warehouses. In order to answer our big question outlined above, first we need to discuss the differences between data lakes and data warehouses in seven key areas.
You must be familiar with the fact that the data lake and data warehouse architectures differ in various aspects.
While data warehouses can only store data that has been structured, data lakes store all types of data, irrespective of the source and its structure.
Both kinds of data repositories can handle hot and cold data, but cold data is usually best stored in data lakes, where latency isn’t an issue.
Data lakes retain not only the data that is in use but also data that one might use in the future. Since data is kept for all time, data experts can easily go back in time and do an analysis.
Regarding the data warehouse development process, significant time is spent on analyzing various data sources since data warehouses are much more selective on what data they ingest and store.
Compared to data lakes, data warehouses can cost a lot, especially if the volume of data is large. Higher costs are both due to the much higher cost (per bit stored) of relational databases that form the basis of most traditional data warehouses and due to much higher upfront development costs of properly structuring and storing data. It makes data access much easier and cheaper, though.
Data lakes are much cheaper on the data integration (“ingest”) side: they store the data as is without much regard to what a “blob”’s actual content is. They incur costs on processing: both interpretation-related and infrastructure-related. If a data set is queried often, and especially if not queried by the same “slicing pattern” (so called “partitioning”) as it was stored - well, that can be quite expensive and may take fairly long on each run.
Before loading data into a data warehouse, one has to give it some shape and structure which of course takes a lot of time. However, due to their cleansed and structured form, data warehouses offer insights into predefined questions for predefined data types.
A data lake, on the other hand, accepts data in its raw form, meaning that you only have to give it some shape and structure when you need to use the data. This empowers users to access data before it has been transformed, cleansed and structured. Consequently, compared to the traditional data warehouse, a data lake allows power users to get to their results more quickly.
Data lakes and data warehouses are suited for different users.
A data lake is ideal for users who indulge in deep analysis (which are often ad-hoc). Such users include data scientists and data developers who need advanced analytical tools with capabilities such as predictive modeling and statistical analysis.
Data warehouses on the other hand are used mostly in the business industry by business professionals who need well structured, easy to use, and understand data for preparing reports (often on a schedule) and analyzing key performance metrics.
Compared to a data lake, a data warehouse is a highly structured and stable, but also slow and rigid data bank with a fixed configuration and little agility. Changing its structure is relatively time-consuming due to the fact that all the business processes are already tied to the warehouse.
Since a data lake lacks structure, it’s extremely agile when it comes to the configuration and reconfiguration of data models, queries, and applications. This lack of structure, however, keeps non-experts away which also explains why the primary users of data lakes are data scientists - and not business analysts.
Since data warehouse technologies have been around and in use for decades, it’s safe to say that they are mature and secure to use.
Big data technologies such as data lakes on the other hand are relatively new. Consequently, the ability to secure data in a data lake is immature, though, data security is maturing rapidly.
Regarding the above characteristics and benefits of data lakes, the question may arise: can a data lake replace a data warehouse?
If we want to be honest, in most of the cases, no. But why?
Let’s dig into the reasons!
Data lake architecture has evolved in recent years to better meet the demands of data-driven enterprises as data volumes continue to rise. However, those who dream of data lakes providing the same capabilities as an enterprise data warehouse but at a cheaper cost have to be cautious!
Data lakes are not free of drawbacks and shortcomings. New technology often comes with challenges and data lakes are no exception.
For instance, since data lakes allow you to store anything without questioning whether you need all the data or how the data is beneficial or if it meets any quality standards at all, users will have a difficult time once they try to extract value from the “data swamp”. This lack of data prioritization increases the cost of data lakes (when compared to data warehouses) and creates confusion around what data is required. Since data in data lakes are in raw form, analysts must be extremely careful to derive the same complex aggregates in the same standard way on every assignment - else they will be inconsistent across the board. This might result in a slower analytical process.
Furthermore, since data lakes need someone to model the data so it makes sense to business users, any lag in obtaining data will affect your analysis. This latency in data slows interactive responses. Additionally, since data lakes do not have rules overseeing what they can take in, they might expose your company to a host of regulatory risks. Not exactly, what you are looking for, right?
If all you have is a hammer, everything looks like a nail. Similarly, if organizations strive for data lakes for their own sake without taking a closer look at the “whys” behind their decisions, in most cases they end up with solutions that do not meet their business requirements.
Even though data lakes and data warehouses are technically capable of doing similar jobs (especially when viewed from a distance), they, in fact, serve different purposes and require a different approach to be properly optimized.
Therefore, when determining if your company needs a data lake or a data warehouse, or both, you should keep a string of factors in mind. Namely:
In this sense, a traditional relational data warehouse should be viewed as just one more data source available to a user, enabling him or her to swiftly run certain queries. And a data lake should be viewed as another data source for the right type of people and purpose.
Based on the above, a data lake should not be blocked from all users, since data lakes offer a rich source of data for data scientists and power users. However, not all data and information workers want to become power users. The majority of business analysts continue to need well-integrated, systematically cleansed, easy-to-access relational data.
Regarding this matter, a federated data architecture is an excellent solution since it allows power users or data scientists to access data quickly via a data lake while allowing all the other users to access data in a data warehouse, making self-service BI a reality.
No matter what type of storage repository you are using, if you don’t pay attention to the design and continuous adjustment of your data architecture so that it is always tailored to your specific business needs, you won’t be able to optimally extract value from your data.
Therefore, efficient metadata management and data governance solutions are inevitable for success! In order to craft the best strategy, it is highly recommended to ask the help of business intelligence experts who help you solve even the most complex problems!
The emergence of new business needs and technologies did not extinguish the need for data warehouses, since the majority of end-users still need the data in a relational data warehouse for self-service reporting.
The answer to the “data lake vs data warehouse” dilemma incorporates opting for an approach that enables the optimization of value to be extracted from data. In this sense, a data lake should not be viewed as a replacement for a data warehouse, but rather as a system that augments and complements it.
We are curious about your opinion: what aspects do you consider when deciding about using a data lake or a data warehouse (or both) for storing big data?
Author:
András Zimmer - CTO
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.

dbt Labs recently announced dbt Fusion, a complete overhaul of the dbt Core engine built in Rust. It promises to significantly improve the developer experience. In this article, we test its core features and share our hands-on experience with the public beta, exploring what works, what doesn't, and what potential it holds for the future of dbt development.

From more guardrails by developers to the UX challenge of showcasing sources in a non-deterministic system, the industry is still finding its grip on the whole process. We looked into the nitty-gritty details at our recent meetup on UX in the age of AI agents—check out the recording below!