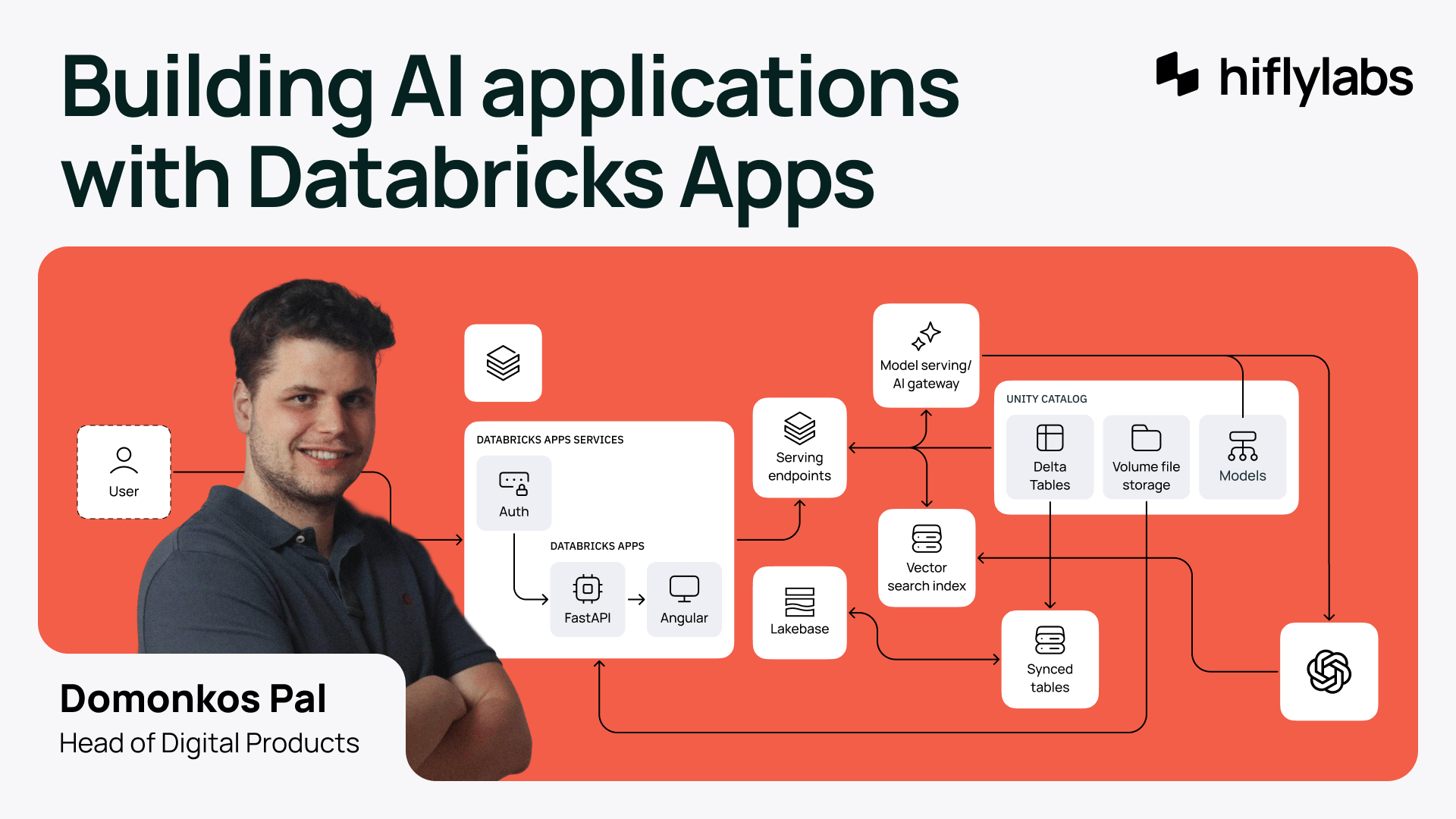
Building an AI Application with Databricks Apps in 30 Days
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.



How much effort is worth putting into performance optimizations? Why should you care about inefficiencies and how to get started? What are the best ways to avoid the traps of AI-lapses?
At Hiflylabs, we have been using dbt and Snowflake on several assignments, and we have learned a ton. In this two-part blog series I’d like to share some of our findings, and perhaps start some discussion on the topic in general.
So, let’s dive in.
Most analytics engineering projects start out “small”, and only some grow really large over time. Therefore initially not much effort is spent on thinking about, and even much less on actually implementing, performance optimizations. It is only natural: at the beginning usually there is little data, not much processing, and there are simpler questions to answer. And the analytical cloud database engines, Snowflake among them, are truly mighty beasts; their capacity easily covers up for inefficiencies in early stage initiatives.
As projects mature, though, there often comes a period when user demands overwhelm “sane” sized cloud engines. How big “sane” is, of course, depends on a lot of factors. But seasoned data engineers and greybeard data architects do have a good sense of what “should be” enough. In most cases it is possible to push on with resizing the engine and/or having longer load windows. This, however, is usually a short-term band-aid only.

Responsible technical personnel should, and do, raise the performance issue “smell” and suggest investigation to the project team. And, in sync, wise product owners keep a healthy balance between feature development and less visible, but equally important, “housekeeping” tasks (usually all shoveled into the “tech debt” bucket).
That’s how we looked into several projects’ performance issues. How much effort is worth putting into performance optimizations mostly depends on how much you’re spending on Snowflake: not much if your budget is $100 per month, however when a daily run exceeds $1000, a couple engineer-days to cut it by 30% has a decent ROI :).
We found that some practices are good (“best” :)) when projects operate under certain constraints (e.g. when they are small and extremely dynamic) but tend to break down as some of these constraints change. We also found some tools, Snowflake included, to be very smart (often in situations when we hadn’t expected) but that’s not always the case. And sometimes these “AI-lapses” can be very costly. However, they usually only surface when there is significant load — otherwise Snowflake’s sheer power hides them.
The first step towards performance control we do on our assignments (once they grow a tad bit larger) is to instrument some performance-related monitoring. It doesn’t have to be very elaborate initially, and it doesn’t even take that much time to set up. There are many out-of-the box components that help us and the client start to have a feel for the general performance characteristics of the system. (E.g. how much processing is required, what the large models are, etc.)
Snowflake has an official Looker Snowflake dashboard that’s a pinch to install. It’s also pretty easy to have it send the report weekly to a Slack channel. This is a low effort first step, and a reasonable one if you also follow some conventions (e.g. using separate warehouses for separate processes / uses). The data there is not actionably detailed, though: it helps you detect that you may want to investigate further but does not help you much in determining where to look.
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.

dbt Labs recently announced dbt Fusion, a complete overhaul of the dbt Core engine built in Rust. It promises to significantly improve the developer experience. In this article, we test its core features and share our hands-on experience with the public beta, exploring what works, what doesn't, and what potential it holds for the future of dbt development.

From more guardrails by developers to the UX challenge of showcasing sources in a non-deterministic system, the industry is still finding its grip on the whole process. We looked into the nitty-gritty details at our recent meetup on UX in the age of AI agents—check out the recording below!