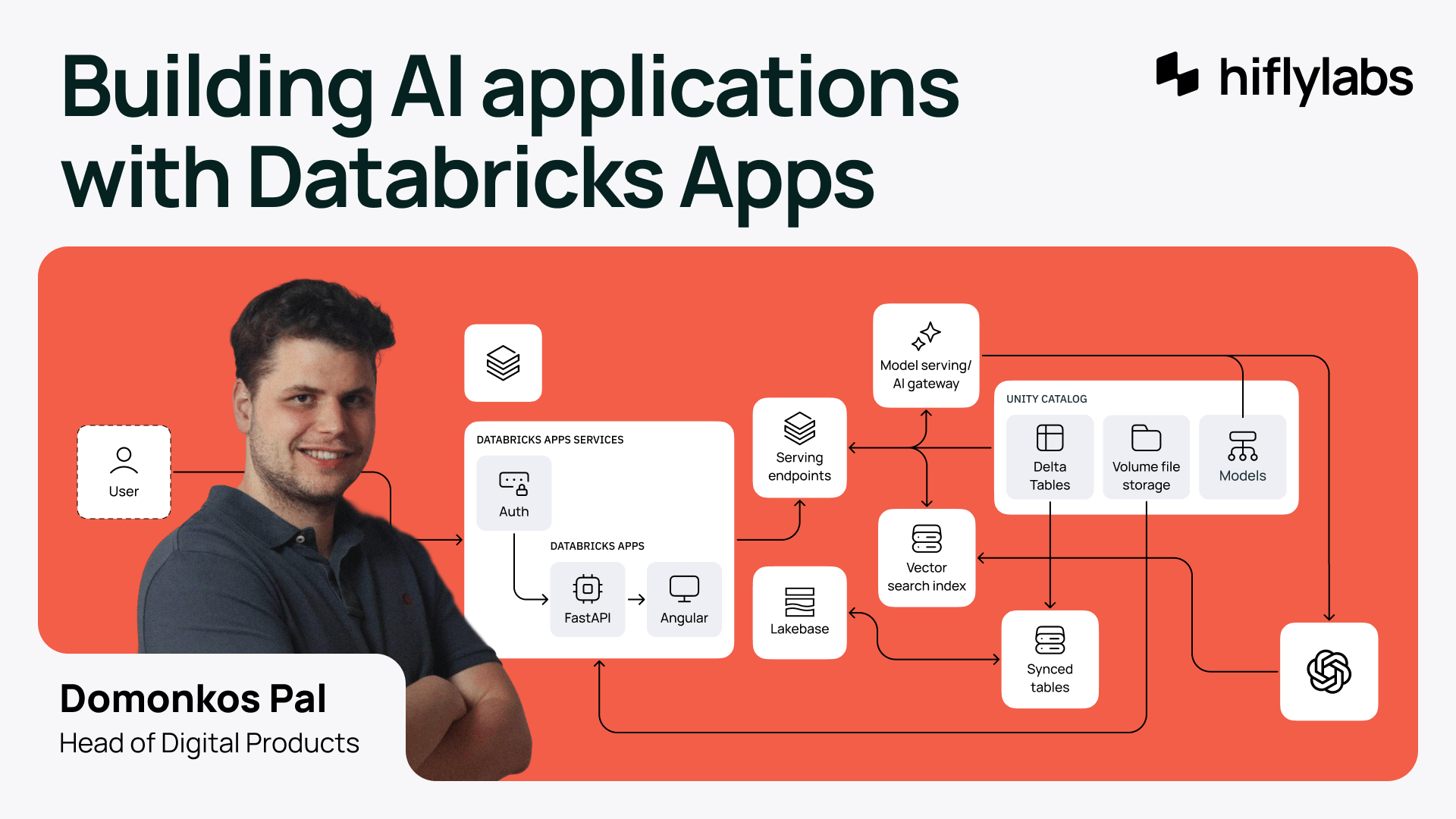
Building an AI Application with Databricks Apps in 30 Days
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.



Sunk cost in the data space.
Let’s be honest, 2022 was a good year for data and a lot of companies moved closer to working with data (kinda induced by the pandemic). Also, you probably saw a lot more job openings on LinkedIn to kickstart an analytics engineering team. There is still a lot to explore, but more and more companies start to realize how valuable data is in the first place and how dbt shortens the learning curve.
This also means that they probably got slapped with a big chunk of the budget as an investment into digitalization. What do you do when you have money? You SPEND, right?!

Improvements in data analytics in the last decade spoilt us in a way. Extremely cheap storage decoupled from compute completely turned the notion of “scalability” upside down. On-demand pricing instead of hefty license fees back in the OracImprovements in data analytics in the last decade spoilt us in a way. Extremely cheap storage decoupled from compute completely gave the notion of “scalability” a different meaning and boundaries. On-demand pricing instead of hefty license fees back in the Oracle days gave us flexibility to only pay for what you use. You can always use more resources and increase our capacities to fit our scale. However, economies of scale are different. You can’t keep up with the exponentially increasing costs as a function of data growth.
“Sit back, enjoy the ride! We will pay the bills at the end of the month.” — Our inner devil
As the data grows along with the business requirements, you start to see bills getting into a region where it needs to be seriously addressed. Boards are pulled together and Bill asks
“Hmm why is there a big spike in Snowflake costs, Joe?” — Bill
The team starts to nervously dig into parts of the code where you can cut costs, but oftentimes it seems like they are navigating unknown waters.

*does not use warehouse for information schema queries (row count, size, table type, etc) + cached queries.

One tool to rule them all, one tool to bring them all — Me

So what else happened in 2022? The global economy got hit seriously and many tech companies overstaffed, and overestimated their productivity, so they started to do mass lay-offs. No, this is not a “good sign” by any means, but it really brought us back to reality to appreciate the cost limiting features of cloud data warehouses.
If you abide to these laws, you can scale better as a team and have a better ROI to “recover” the sunk costs.
Btw, Our CTO, Andras has already written a handy article about cutting costs in Snowflake.
Do we have to care more about cloud cost optimization ourselves and do our research, or is it fair to expect a better query optimization, and these advanced tools to identify our bottlenecks?
Either way, my prediction for 2023 is that cloud costs are going to be an even more sensitive topic when these vendors go Either way, my prediction for 2023 is that cloud costs are going to be a counterpoint topic when these vendors go head-to-head, and we are going to see more companies on focusing pushing down the monthly bill.
If cost optimization is a concern for your company, don’t miss our next Snowflake webinar!
On the 8th of February 2023, Andras Zimmer, Head of Analytics Engineering at Hiflylabs is going to walk you through multiple real-life applicable tips & tricks that can help your Snowflake costs plummet.
Book your seat here!
Discover how to build a production-ready AI application on Databricks Apps in just under a month. Learn from our journey, challenges, and architectural choices.

dbt Labs recently announced dbt Fusion, a complete overhaul of the dbt Core engine built in Rust. It promises to significantly improve the developer experience. In this article, we test its core features and share our hands-on experience with the public beta, exploring what works, what doesn't, and what potential it holds for the future of dbt development.

From more guardrails by developers to the UX challenge of showcasing sources in a non-deterministic system, the industry is still finding its grip on the whole process. We looked into the nitty-gritty details at our recent meetup on UX in the age of AI agents—check out the recording below!