


Table of Contents
- What’s an ontology?
- Organizational ontology
- Core capabilities of ontology
- How ontologies work
- Real-world examples
- Update: a new way to match ontologies
- In summary
What’s an ontology?
Philosophically, ontology means the study of being. Does ‘nothing’ exist? Does ‘God’ exist? Do ‘I’ exist? To articulate metaphysical questions like these in a formal way, philosophers came up with a structure of rules and categories they can group entities into.
In data science and AI, ontologies are similarly formal and explicit specifications of concepts (like a vocabulary) and their relationships within a specific domain (like a network or blueprint).
Specifically, an ontology should have these three nailed down to ensure logical consistency for AI agents:
- Domain-specific vocabulary of concepts
- Core relationships between them
- Immutable axioms (rules)
These definitions help algorithms understand the real-world environment they operate in, and make multi-agent communication more effective.
What makes an ontology powerful compared to a traditional database is how it formally models the relationships between entities and the actions they can perform. This unified model creates a “digital twin” of an organization that can provide insights, execute tasks, then update itself based on the results.
The main utility is in replacing siloed systems with a single, intelligent operational layer on top of an organization.
Organizational ontology
Let's take two examples from different industries, a General Hospital and a Supply Chain scenario:
1. The What: Defining a digital twin
- Hospital: The ontology would define objects like Patient, Doctor, Nurse, Bed, OperatingRoom, Medication, Diagnosis, MedicalImage, LabResult. Relationships would include: Patient has_Diagnosis, Doctor treats_Patient, OperatingRoom has_Schedule.
- Supply Chain: Objects could be Product, Supplier, Warehouse, Shipment, CustomerOrder, BillOfLading, InventoryLevel. Relationships: Supplier provides_Product, Shipment contains_Product, Warehouse stores_InventoryLevel.
2. The How: Modeling actions & processes
- Hospital: This layer would model actions and processes like AdmitPatient, ScheduleSurgery, DischargePatient, AdministerMedication. A workflow for "Patient Admission" might involve checking Bed availability, assigning a Doctor, and ordering initial LabResults.
- Supply Chain: Actions include PlaceOrder, FulfillOrder, DispatchShipment, ReceiveShipment, UpdateInventory. A process for "Order Fulfillment" would link these actions, triggered by a CustomerOrder.
3. The Why: A live, interactive system
- Hospital: A new LabResult (data event) for a Patient updates the patient's object in the ontology. If the LabResult indicates a critical condition, this could trigger an alert (action) to the assigned Doctor through an application built on the ontology. When a Patient is discharged (action), the status of their assigned Bed (object) changes from "occupied" to "available" in real-time, updating dashboards for bed management teams. The system can track how long Patients with a certain Diagnosis typically stay, and if a Patient deviates, it might flag it for review. This is capturing decisions/outcomes for learning.
- Supply Chain: A Shipment (object) being delayed (event) updates its ETA. This delay dynamically recalculates the potential impact on CustomerOrder fulfillment and InventoryLevel at the destination Warehouse. The system can then recalculate its impact on fulfillment and alert a manager, who can then take corrective action. The results of this action are fed back into the system, creating a closed-loop process for handling disruptions.
Core capabilities of ontology
The main goal of ontology is to become the central nervous system of an enterprise, providing:
- A shared, semantic understanding of all relevant business entities and their relationships.
- A way to model actions and processes of the organization.
- A dynamic, real-time representation that allows for immediate response and closed-loop learning.
These capabilities are also the main value proposition of the ontology for any organization.
In practice, this means that:
- Data engineers focus on connecting and ensuring the quality of data flowing into the ontology.
- Developers and data scientists build and deploy models that leverage the rich, contextualized data within the ontology, and whose outputs can become new properties or trigger actions within it.
- End users, like operational and business teams, interact with applications that query the ontology to provide insights, recommend actions, or automate processes based on the live state of the ontology. Decisions made and their effects are then fed back into the system, improving it over time.
Let's break down how this works
How is the ontology represented and implemented?
We need a concrete, machine-readable set of files and databases. Not a diagram on a whiteboard. Not just a system prompt.
Formal language
It's defined using standard languages from the Semantic Web stack, primarily OWL (Web Ontology Language) and RDF (Resource Description Framework). These are W3C standards designed for this exact purpose.
- RDF provides the basic structure of subject-predicate-object "triples" to create statements (e.g., ex:Car_123 ex:hasColor "Blue").
- OWL builds on RDF to add much richer semantics. It allows you to define complex class hierarchies (A_Sedan is a type of Car), define properties (e.g., the hasColor property can only be applied to a Vehicle), and set rules and constraints (e.g., a Car can only have one Owner at a time).
Implementation as a knowledge graph
In practice, the ontology (the schema/model) and the instance data (the actual things in your world, like "Car_789") are stored together in a knowledge graph. This is most often housed in a specialized database called a graph database (e.g. Neo4j, Amazon Neptune, Stardog, AllegroGraph). These databases are optimized for storing and querying the complex relationships defined by the ontology.
How do AI agents interact with the ontology?
The agents interact with the ontology through APIs and tools. They don't get a 50-page PDF explaining it.
Method 1: Tool-use and API calls (most common)
This is the primary mechanism. Each agent in a multi-agent system is given a set of "tools" it can use. Several of these tools are specifically designed to interact with the knowledge graph.
Querying the graph
The agent can call a tool like query_kg(query). The agent's task is to formulate the right query in a language like SPARQL (for RDF databases) or Cypher (for Neo4j).
Example: An "Inventory Management Agent" needs to know which parts are running low. It would formulate a SPARQL query like:
PREFIX ont: <http://mycompany.com/ontology#>
SELECT ?part ?stockLevel
WHERE {
?part a ont:Component .
?part ont:hasStockLevel ?stockLevel .
FILTER(?stockLevel < 10)
}
The agent's LLM brain is instructed to generate this query based on the natural language request, "Find all components with stock levels below 10."
Updating the graph (the closed loop)
The agent can also use a tool to write back to the ontology. This is essential for a dynamic system where actions and results are recorded in real time. Example:
Example: A "Procurement Agent" is tasked with ordering more of a specific part. After successfully placing an order via an API call to a purchasing system, it uses a tool like update_kg(update_statement) to add new information:
PREFIX ont: <http://mycompany.com/ontology#>
INSERT DATA {
ont:PurchaseOrder_987 a ont:PurchaseOrder .
ont:PurchaseOrder_987 ont:forComponent ont:Part_ABC .
ont:PurchaseOrder_987 ont:hasStatus "Placed" .
}
Now, all other agents can see that this part is on order.
Method 2: Ontology-informed system prompts & context
While the entire ontology isn't stuffed into the prompt, a relevant subset of it is.
Agent role and capabilities
An agent's system prompt will absolutely define its role in the context of the ontology. For example, the "Logistics Agent" prompt would state:
"You are a Logistics Orchestration Agent. Your goal is to ensure the timely delivery of Shipments. You can interact with objects like Shipment, Warehouse, Carrier, and Route. Your available tools are get_shipment_status(shipment_id), calculate_optimal_route(origin, destination), and update_shipment_eta(shipment_id, new_eta)."
Grounding
The ontology provides the "nouns" and "verbs" the agent can use. When a user asks, "What's the status of the shipment to Chicago?", the agent's LLM knows that "shipment" is a formal Shipment object in its world model and that it can use its tools to query information about it.
Method 3: Embedding and RAG (Retrieval Augmented Generation)
For very large ontologies, the relevant parts of the schema (the definitions of objects and relationships) can be embedded into vector space. When an agent has a query, it first does a similarity search on the ontology's documentation to find the relevant classes and properties. This retrieved context is then added to its prompt to help it formulate the correct API call or graph query. This is how it connects to a "knowledge base" representing the whole structure.
How do agents know their place on the “map”?
The ontology itself is the map. An agent understands its position by knowing its:
- Identity: What type of agent it is (e.g., LogisticsAgent, which is a concept in the ontology).
- Permissions: Which parts of the ontology (classes of objects, types of relationships) it is allowed to read from and write to. This is often managed by an overarching orchestration layer or API gateway that checks permissions before executing a tool.
- Inputs & Outputs: The orchestrator assigns it tasks that reference specific instances in the knowledge graph (e.g., "Process CustomerOrder_456"). The agent's job is to update that object and related objects according to its programmed logic.
Wait, isn’t this compatible with the Data Vault?
Yeah, the operational layer needs to be fed by a reliable source of data. Because ontologies are highly complementary to modern data methodologies like the Data Vault, we should take a quick look how they’re seated in the architecture compared to each other:
- Data Vault: A scalable, auditable data warehouse foundation
- Ontology: An actionable, semantic operating layer
| Data Vault | Ontology | |
| Primary goal | Store and integrate historical data. | Activate data for real-time operations. |
| Layer | System of Record / Integration Layer. | System of Engagement / Decision Layer. |
| Time focus | Historical, point-in-time, auditable. | Real-time, current state, dynamic. |
| Core question | "What was true?" | "What is true now, and what should we do?" |
| Technology | Typically relational databases (Snowflake, BigQuery). | Typically graph databases (Neo4j, Neptune). |
| Represents | Raw, integrated facts with history. | High-level, semantic business concepts. |
| Use case | Agentic Business Intelligence (BI), reporting, analytics. | AI-driven automation, operational apps, semantic search. |
So, while the Data Vault archives the complete historical truth, the ontology can be used to activate the relevant parts of that truth for immediate action.
Real-world examples
While many companies using these systems are secretive, there are some tangible examples.
Airbus Skywise
How it works
Skywise integrates data from thousands of aircraft, maintenance logs, and supply chain systems. The ontology defines Aircraft, Engine, ComponentPart, MaintenanceRecord, FlightPlan, and FaultCode.
Agent interaction
A "Predictive Maintenance Agent" could continuously monitor streaming data from an Engine's sensors. When it detects a pattern that matches a known FaultCode profile (defined in the ontology), it can:
- Query the ontology for the maintenance history of that specific ComponentPart.
- Check the global supply chain for the availability of a replacement part.
- Create a MaintenanceAlert object linked to the Aircraft.
- This alert is then picked up by a "Maintenance Scheduling Agent" that automatically schedules hangar time for the aircraft upon landing, minimizing downtime.
Financial services (AML, anti-money laundering)
How it works
The ontology defines Customer, Account, Transaction, Beneficiary, and RiskIndicator. It models complex ownership structures (e.g., shell companies).
Agent interaction
An "Alert Triage Agent" sees a new high-value transaction. It queries the knowledge graph to trace the funds' origin and destination, traversing multiple layers of Customer and Account relationships. If it finds a link to a sanctioned entity (another object in the graph), it escalates the transaction by creating a SuspiciousActivityReport object, which is then assigned to a human compliance officer.
Update: a new way to match ontologies
Paper title: KROMA: Ontology Matching with Knowledge Retrieval and Large Language Models
Arxiv link: https://arxiv.org/pdf/2507.14032
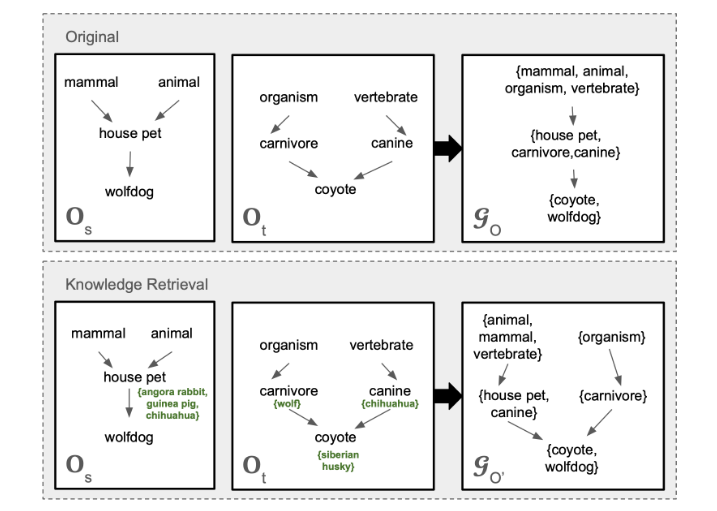
So, what if you have clashing definitions within your processes? What if your main ontology calls it a ‘car’, but one of your databases uses the term ‘automobile’?
Traditionally, you’d need handcrafted rules to sort this out, but those do not generalize well.
That’s why automatic ontology matching is a breakthrough method, enabling you to resolve any and all of these discrepancies, making ontologies themselves much more robust and practically applicable.
In summary
The implementation is a tiered system:
- Data Layer: The foundational system of record, like a data warehouse, which is integrated to access preserved historical, auditable data from all source systems, providing the ultimate source of truth that feeds the layers above.
- Semantic Layer: A formal ontology (OWL/RDF) stored in a graph database (the Knowledge Graph).
- Interaction Layer: A set of APIs or "tools" that allow agents to read (query) and write (update) the knowledge graph.
- Agent Layer: Specialized AI agents with LLM brains and system prompts that define their role and teach them how to use their tools.
- Orchestration Layer: A master controller that assigns tasks to agents and manages the overall workflow, using the knowledge graph as the central state and shared memory.
The ambition is to move beyond siloed data and applications to a truly integrated, intelligent, and responsive operational environment. The success of this model across diverse problems (from healthcare to manufacturing to agentic BI) shows us that actions become really powerful when integrated with deep semantic understanding.


