
Operationalizing AI Ontologies
An operational intelligence layer, the ontology, models relationships of entities and actions, enabling “digital twins” for organizations.



To save you some time in copying examples, all the necessary scripts can be found here. We’ve been using dbt for a while now and we feel that most developer needs are covered with community-developed test suite packages like dbt_utils, dbt-expectations, or custom generic environment testing defined via the mix of Jinja and SQL.
Although, growing business and data requirements demand an automated way of validating our transformations locally. Cherry-picking observations and manually doing regular check-ups on the transformations can increase the technical debt exponentially, especially when the complex procedures leading to the desired outcome are not trivial to the naked eye.
It was our priority to find a way of unit testing our “black boxes”, and make a comparison between the expected output and the output our sets of models have produced with respect to a static input. This way, we can ensure that the business logic is accurately transformed into code.
There are multiple ways of doing this in dbt, but we found that existing solutions neither fully exhibit the end-to-end testing, nor achieve the flexibility to run our tests dependent on the development environment.
So here’s my quick take on those particular ones.
In short, all of the current resources apply great approaches, but our company needed were the following two core features:
Without further ado, this is how we have built our unit testing environment!
Step 1. Create a unit-testing environment
This is the environment we will use when defining our tests specifically for validating the transformation logic. How you configure the profile.yml is entirely up to you, just make sure that you reference this target when testing. You may mirror the development profile or opt for materializing unit test models in their own schema.
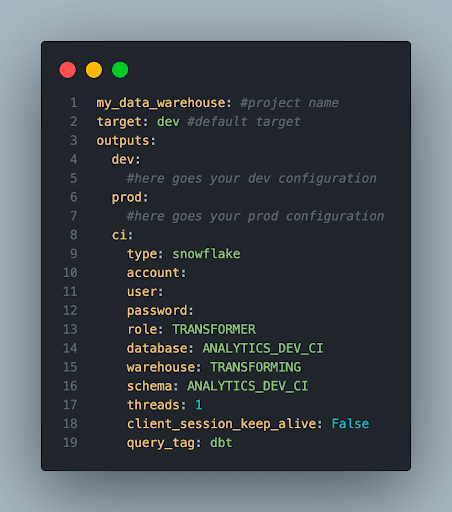
New profiles.yml entry for unit testing
Step 2. Add mock data to the project
Next, we can now add our input which passes through all the transformations as well as an expected output mock data validating the end-product to the data folder (assuming that our project uses the default seed path).
An efficient way of doing a unit test is to assemble a mock input that raises all the possible edge scenarios the model should be able to handle. In other words, we should be able to spot-check every component of the business logic.
What we usually do is pick out a certain entity (account, organization, user, etc.) and manipulate the input accordingly. This way the comparison will be faster and more concise, rather than just feeding the large chunk of the data. The latter scenario also prompts for a larger expected output calculation.
To keep everything organized, we created a unit_testing folder under the seed folder. This way we can easily identify which seed files are there for mock testing, and which are in the traditional dbt sense. This is useful, especially if you do a lot of unit testing during the development making the project a morass of spaghetti. So, for the sake of your fellow developers, keep things tidy!
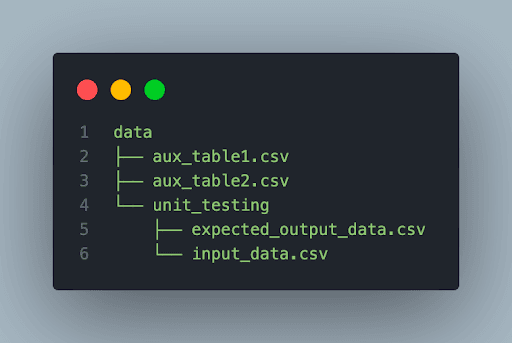
Seed folder structure
Step 3. Seed mock data
Make sure you seed both the input and expected output CSVs to the warehouse, so it will be accessible for the pipeline logic picking up the mock input on the fly and comparing the output to validate your expectations.
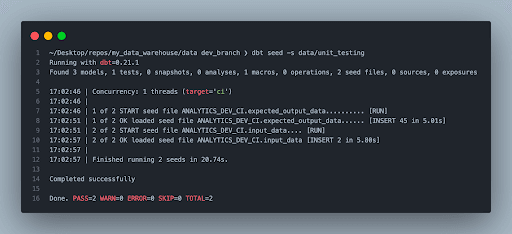
dbt seed
Step 4. Create a reference to the mock input
Here we tell dbt that when we are executing a test in the unit testing environment, then instead of picking up the source we are using throughout the project, take the mock data as the input, otherwise, just proceed with the production staging data.

Create a separate in-model branch for testing
Step 5. Define your test criteria
Next, we have to define the test we are planning to execute on the mock output and the model outcome table. In our instance, we wanted to check whether we got the same for a certain input calculated by a spreadsheet tool and dbt. dbt_utils has an equality check test out-of-the-box but doesn’t let you switch between environments.
Therefore, we had to write a custom test which, in essence, extends the base equality test logic with the possibility of running it only in a given environment. It is very likely that someone has already thought of similar checks (in our case dbt Labs), but there are a couple of things you want to shuffle. As a result, it is worthwhile checking out the source code behind the open-source test suite packages which can be an excellent reference to build upon additional features.
We simply extracted the relevant components of the default equality test macro and added a conditional statement checking the context we are currently testing.
It accomplishes the followings:
We can store our custom tests as macros or generic tests as per the dbt documentation.
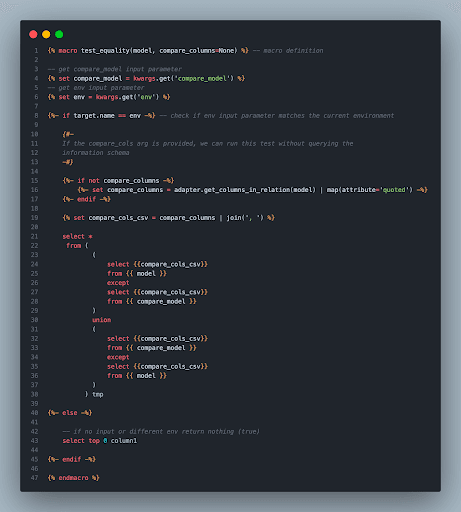
Custom generic test for equality
Step 6. Add custom test to YAML block
Finally, we can use the custom test in our YAML blocks as the sample below:
We must first specify our comparative data as well as the context in which the test will be carried out. We may further reduce the number of columns to check by providing additional arguments.
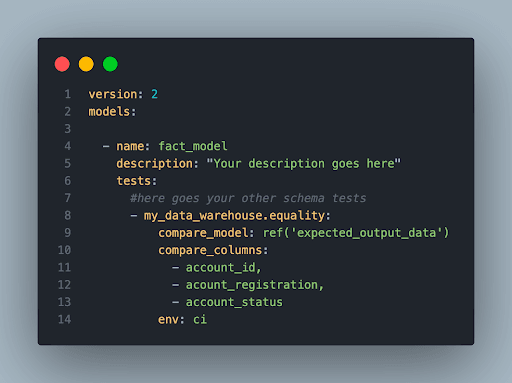
Add custom test to schema.yml
Ideally, we would define unit tests in separate schema YAML files but unfortunately, dbt does not allow us to have multiple model definitions for schema tests.
Step 7. Build and Profit!
Now that we have everything set up to do systematic checks in local development, we can simply run a dbt build command with rerouting the target to the unit test profile.
It will apply the transformation on the mock input dataset and expose that to the expected output. If your checks have, you might want to review the utilized logic, but better safe than sorry when pushing false data into production.
(You might as well want to store test failures in an audit schema to make debugging easier instead of copy-pasting the compiled test)
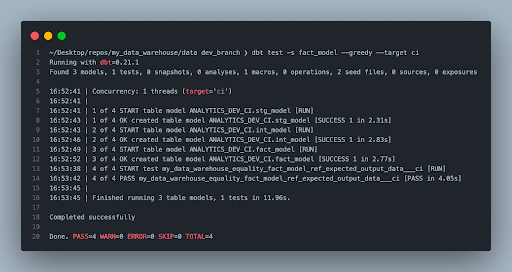
Run your models using mock data and unit test them
Final Remarks
In this walkthrough, we have shown you how to set up an environment for unit testing and gave you an example of how we make sure that the correct business value is delivered to our clients through equality checks. The main takeaways are:
All the necessary scripts used for unit testing is available here.
We hope that you enjoyed this blog post and feel free to share your testing best practices with us! Also, let us know how you would improve our unit testing framework.
Author:
Son N. Nguyen - Data Engineer
You can find our other blog posts here
An operational intelligence layer, the ontology, models relationships of entities and actions, enabling “digital twins” for organizations.

We’ve put together a simple guide on what we believe is a must have security functionality: anonymizing structured data effectively. Let’s ensure your data is both perfectly secure and fully usable for business operations.

Regardless of advances in human-computer interaction, typing at least a part of our commands remains a staple. Now, ChatGPT is pretty much synonymous with AI-human interaction. But are these just remnants of a very strong mental model, or is it the most effective way to interface with computers? It might be both.