Recently, we ran into an interesting performance issue when we used numerous dbt generated window functions in a query. We experienced exponential performance decay, which was too high compared to the pace of warehouse expansion. Our investigation proved that it matters if there are too many equal partitioning values in a window function. But how much does it matter?
Let’s find out!
The original solution
We developed a solution for one of our clients to be able to analyze data collected from their partners. During the developmental process, we tried to simplify the method of processing this data. To achieve this goal, a common data layer was created. In this layer, we built a common data structure, where we could map different client data into a well-defined general table structure. We used dbt for transforming data between raw partner data and the consumption layer.
In order to support the analytical capabilities at the end of the processes, we used pre-aggregations in the integration data layer. It was very useful for business users because they got immediately usable fields on the behaviour of the entities. And last but not least, the consumption layer didn’t waste time and resources for calculating these aggregated values.
The generation of these aggregations happened automatically, many of them with window functions for all the affected fields, performing min, max, and lag calculations on the specified columns.
The following templated dbt code example shows how we calculated datediff on min, max, and lag values for five periods (day, week, month, quarter, year) on 3 fields (user, organization, account) with for loops.
select
*,
-- iterate on the necessary fields
{% for affected_field in ['user', 'organization', 'account'] %}
-- set window function partition clauses
{%- set part_str = ' over (partition by ' ~ affected_field ~ ', partner_id)' -%}
{%- set lag_part_str = ' over (partition by ' ~ affected_field ~ ', partner_id order by event_ts)' -%}
-- iterate on the intervals we want to see the calculations
{% for period in ['day', 'week', 'month', 'quarter', 'year'] %}
-- calculate the min, max and lag values
-- using a macro for handling null values
{{ nullify_unknown(affected_field,
dbt_utils.datediff(
'min(event_ts)' ~ part_str,
'event_ts',
period
)
)}} as {{affected_field}}_{{period}}s_since_first_event,
{{ nullify_unknown(affected_field,
dbt_utils.datediff(
'lag(event_ts,1)' ~ lag_part_str,
'event_ts',
period
)
)}} as {{affected_field}}_{{period}}s_since_previous_event,
{{ nullify_unknown(affected_field,
dbt_utils.datediff(
'max(event_ts)' ~ part_str,
'"CURRENT_TIMESTAMP"',
period
)
)}} as {{affected_field}}_{{period}}s_since_last_event,
{% endfor %}{% if not loop.last %},{% endif %}
{% endfor %}
from
t_events
As you can see in row 15, we have a nullify_unknown macro that handles null values. It was needed because it As you can see in row 15, we have a nullify_unknown macro that handles null values. This was necessary because it often happened that a company didn’t have a full account-organization-user hierarchy, companies only had for example, users. Using this macro, we filter out null values before creating partitions so that we don’t process null values in window functions.
{%- macro nullify_unknown(affected_field_id, field_calc) -%}
case when left({{affected_field_id}}, 7) = 'UNKNOWN'
or {{affected_field_id}} is null then null
else {{field_calc}}
end
{%- endmacro -%}
After compiling the dbt code we got this query ( code snippet ):
select
*,
case when left(user, 7) = 'UNKNOWN' or user is null then null
else datediff(
day,
min(event_ts) over (partition by user, partner_id),
event_ts
)
end as user_days_since_first_event,
…
case when left(organization, 7) = 'UNKNOWN' or organization is null then null
else datediff(
week,
max(event_ts) over (partition by organization, partner_id),
event_ts
)
end as organization_weeks_since_first_event,
…
case when left(account, 7) = 'UNKNOWN' or account is null then null
else datediff(
year,
lag(event_ts) over (partition by account, partner_id),
event_ts
)
end as account_years_since_first_event
…
from
t_events
This was a simple, general code for handling these pre-aggregations.
To our satisfaction, this solution performed quite well on all the partner data. Row counts of the affected tables were only tens of millions. As it is a multi-tenant warehouse (partner data continuously ingested) the processing power consumption increased. Weeks and months have passed…
The bottleneck
One day, a new partner’s data needed to be ingested into this data warehouse. We did the integration steps just like earlier with the other partners’ data and dbt did its job, generating automatically the aggregation columns. We knew that this partner had much more data than the other partners (5 billion vs 100 million rows in this t_events table). But the first run at the first full data load produceed unexpected results. The full data loading time for all the tables in the warehouse was beyond our imagination. The runtime disproportionately increased compared to the increase in data!
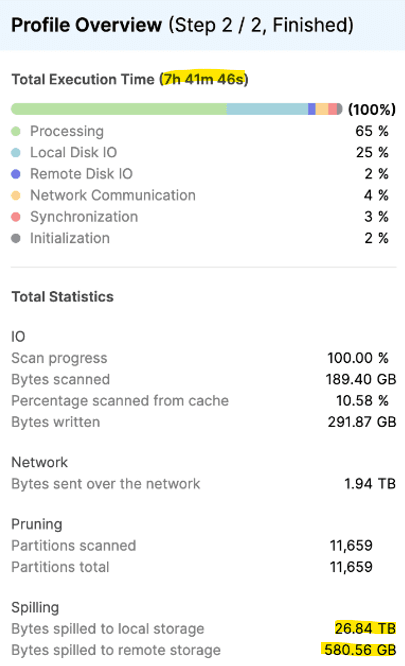
Analyzing the Snowflake history data, we identified the bottleneck. One of the first cases we had to look into was a table with dozens of window functions in it. The query on t_events table data produced an incredible amount of data spilling both on local (26.84 TB) and remote (580.56 GB) storage, resulting in a very long running time (7h 41m):
Original query profile
The analysis
Let’s look into the profile of the query.
First we assumed that the root cause was the large number of window functions and run a few experiments to check. Sure enough, we found that Snowflake is smart enough to only create the partitioned window definition only once even if it is used in many calculations. No dice there.
Going further, excluding suspected causes one by one, we found that turning off a particular data source sped up the process immensely.
We started analyzing the column data and noticed that NULL values in columns used in the partition by clause increased significantly. For example, the organization field is NULL in 95% of the rows in the t_events table. So we thought we had it: the NULLs are the problem! Thus we COALESCE’d them to ‘UNKNOWN’ and re-run the model. To our surprise the result came back in the same long run.
As we could see earlier, NULL values are handled in the select list by a macro. So all the records were examined whether it was null or not and the window functions ran on that null value records too. For example, when the first_value calculation was run for the organization partition, it scanned all records including those where the organization had a null value. This means that a huge partition was created for that NULL values and some smaller for the other data.
Snowflake can correlate the partitioning by different values and the calculations over them, however a huge number of records with the same value, go into one partition. This results in inevitable spilling to disk (local, then remote) which kills performance.
The idea and the solution
As we didn’t need that null values, the idea was that if we could filter them out before running window functions, so they could work smoother on a smaller dataset and we get more evenly distributed partitions.
We moved out each entity to their own CTEs for the 3 fields (user, organization, account)
Filtered out the NULL values in the where clause in the CTEs (i.e. before it ever got to the partitioning part), instead of wrapping the partition clause into a case when block
The window function calculations had to be performed in a narrower table structure, only the identity fields were kept in the query
These separate CTEs were needed to be joined back to the main table
This is not necessarily a solution in every situation — but it was in ours.
The dbt code was refactored as follows:
-- iterate on the necessary fields
{%- for affected_field in ['user', 'organization', 'account'] -%}
{%- set table_str = 't_' ~ affected_field -%}
-- set window function partition clauses
{%- set part_str = ' over (partition by ' ~ affected_field ~ ', partner_id)' -%}
{%- set lag_part_str = ' over (partition by ' ~ affected_field ~ ', partner_id order by event_ts)' %}
-- Creating separate CTEs for calculating window functions only on not null values, filtering null values in the where condition
{{ table_str }} as (
-- need to select the unique identifiers for the final joining
select
{{ affected_field }},
partner_id,
event_ts,
—- iterate on the intervals we want to see the calculations
{%- for period in ['day', 'week', 'month', 'quarter', 'year'] %}
—- calculate the min, max and lag values but we don’t need that nullify macro because of ‘where’ filtering
{{ dbt_utils.datediff(
'min(event_ts)' ~ part_str,
'event_ts',
period
)
}} as {{ ent }}_{{ period }}s_since_first_event,
{{ dbt_utils.datediff(
'lag(event_ts,1)' ~ lag_part_str,
'event_ts',
period
)
}} as {{ ent }}_{{ period }}s_since_previous_event,
{{ dbt_utils.datediff(
'max(event_ts)' ~ part_str,
'"CURRENT_TIMESTAMP"',
period
)
}} as {{ ent }}_{{ period }}s_since_last_event,
{%- endfor %}{% if not loop.last %},{% endif %}
from
t_events
where
—- filtering out null values
left({{ affected_field }}, 7) <> 'UNKNOWN'
and {{ affected_field }} is not null
group by 1,2,3
){% if not loop.last %},{% endif %}
{%- endfor %}
select
t_events.*,
{%- for ent in ['user', 'organization', 'account'] -%}
—- iterate on the intervals we want to display columns
{% for period in ['day', 'week', 'month', 'quarter', 'year'] %}
{{ ent }}_{{ period }}s_since_first_event,
{{ ent }}_{{ period }}s_since_previous_event,
{{ ent }}_{{ period }}s_since_last_event,
{%- endfor %}{% if not loop.last %},{% endif %}
{%- endfor %}
from
t_events
—- joining back the user, organization and the account CTEs to the main table
{%- for ent in ['user', 'organization', 'account'] -%}
{%- set table_str = 't_' ~ affected_field %}
left join {{ table_str }}
on t_events.{{ affected_field }} = {{ table_str }}.{{ affected_field }}
and t_events.partner_id = {{ table_str }}.partner_id
and t_events.event_ts = {{ table_str }}.event_ts
{%- endfor %}
After compiling the dbt code, this query was generated (code snippet):
t_user as (
select
user,
partner_id,
event_ts,
datediff(
day,
min(event_ts) over (partition by user, partner_id),
event_ts
) as user_days_since_first_event,
…
from
t_events
where
left(user, 7) <> 'UNKNOWN'
and user is not null
group by 1,2,3
),
t_organization as (
select
organization,
partner_id,
event_ts,
datediff(
day,
min(event_ts) over (partition by organization, partner_id),
event_ts
) as organization_days_since_first_event,
…
from
t_events
where
left(organization, 7) <> 'UNKNOWN'
and organization is not null
group by 1,2,3
),
t_account as (
select
account,
partner_id,
event_ts,
datediff(
day,
min(event_ts) over (partition by account, partner_id),
event_ts
) as account_days_since_first_event,
from
t_events
where
left(account, 7) <> 'UNKNOWN'
and account is not null
group by 1,2,3
)
select
t_events.*,
user_days_since_first_event,
…
organization_days_since_first_event,
…
account_days_since_first_event,
…
from
t_events
left join t_user
on t_events.user = t_user.user
and t_events.partner_id = t_user.partner_id
and t_events.event_ts = t_user.event_ts
left join t_organization
on t_events.organization = t_organization.organization
and t_events.partner_id = t_organization.partner_id
and t_events.event_ts = t_organization.event_ts
left join t_account
on t_events.account = t_account.account
and t_events.partner_id = t_account.partner_id
and t_events.event_ts = t_account.event_ts
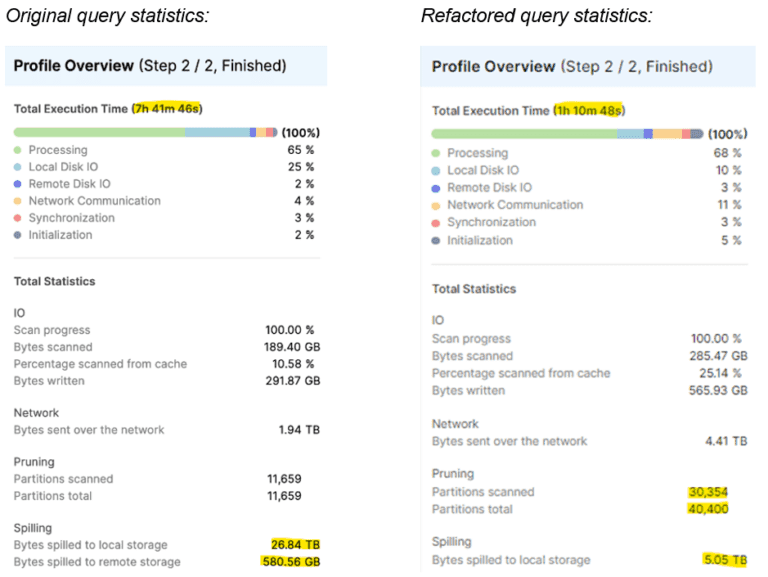
It seems much better, let’s see the run result. It completed in 1h 10m, and the history shows the following statistics:
Before and after comparison
We can see that execution time dramatically decreased as we achieved a speed-up of about seven times. Partition pruning was finally invoked with the initial filter on NULL values, while data spilling on remote storage disappeared and the local spill is definitely smaller than was earlier. For better understanding, notice that the t_events table size is 565,93 GB, while the whole warehouse is 1.69 TB.
This also leads to significant cost savings. In this case, using our warehouse configurations, there was a saving of $346 per run!
The takeaways
The main takeaway, though, is generic: avoid large partitions in Snowflake's window functions.
It is not recommended to wrap the “partition by” clause in “case when”, because it prepares the partition first and only then filters
It’s a good idea to create separate CTEs so that the window functions run only on the affected datasets and they can run parallel
It is worth narrowing the select list in order to use fewer resources
It was worth a try to join back the CTEs to the main query even for large tables. In this case, the benefit exceeded the cost
And another related conclusion, which our further analysis proved, is that Snowflake intelligently creates one kind of partition only once if it appears more than once in the query.
Instead of throwing quick-and-dirty fixes at a declining product, evaluate and plan for the future. This includes introspection as well as thorough market research, and our Product Discovery framework can show you the way.
We’ve put together a simple guide on what we believe is a must have security functionality: anonymizing structured data effectively. Let’s ensure your data is both perfectly secure and fully usable for business operations.
Flying high with Hifly
We want to work with you
Hiflylabs is your partner in building your future. Share your ideas and let’s work together.