

The most frequently asked questions posed to our AI team tend to revolve around safety, accuracy, and well, understanding. How can a computer program possibly know about the world we’re living in, real-life problems we face? The fact that generative AI has an inner ‘world model’ makes it something more than a glorified auto-correct algorithm.
The question with currently available tech is: how can you make AI better understand your own little piece of reality? For example, the context of your relationship or processes at your company?
In this article, we take a look at fine-tuning LLMs and choosing optimization approaches through the lens of a concrete example, first demonstrated by Kristóf Rábay, our very own Lead Data Scientist.
The Math of Memory Optimization
Let’s take a quick detour right off the bat.
Before fine-tuning anything, some optimization might come in handy. This is especially true when working in a resource-constrained environment—whether you’re cooking up a local proof-of-concept without much of a budget or aiming for cost-efficiency in your day-to-day operations.
Firstly, how can you calculate a model's memory requirement?
There are many 7 billion parameter models around nowadays. 1 parameter is about 4 bytes, or 32 bits in other words. So 7B parameters require about 28 GB of RAM. Do we need to store every parameter in 32 bits? And how do we reduce memory requirements?
Through quantization.
Check the HuggingFace website, and if we choose the new Mistral model, we’ll see that its data is stored in only 16 bits. Coincidentally, it doesn't need 7B×4 bytes, and runs on only about 3-4 GB of RAM, which you can read from the memory card in your laptop.
Why didn't they quantize all base models from the start? Because when rounding the numbers, you lose accuracy. But it turns out that you only lose about 10% performance when halving the memory requirement—not a bad tradeoff.
Can you reduce memory requirements in ways other than quantization? Yes, but current alternatives are usually more drastic, like deleting entire layers or entire parameter groups, instead of just rounding things a bit. Or you can always train a base model from the grounds up... So, compared to current alternatives, quantization seems just fine.
What is Fine-tuning, Anyway?
Fine-tuning is a process in machine learning for adapting a pre-trained model for a specific task, improving performance.
How do you fine-tune a LLM with your own data, for your own use cases?
Using model parameters. But not all of them!
Instead of adjusting every parameter, we copy a portion of the parameter matrix and work with just this copy. Then we loop this edited portion back to the original model, resulting in the fine-tuned model as commonly understood.
Which part and how much of the parameters do we copy? It depends on how much we want to change and the base model at hand, how much computational power we possess and how much time we have on our hands.
Be careful not to run into catastrophic forgetting—if you change too much, your AI will start speaking gibberish.
It's not worth meddling with more than 5% of its pre-training knowledge.
Showing a magnitude of around 10,000 examples to the model is usually enough.
But let’s clear something up:
The model doesn't relearn stuff during fine-tuning. Its knowledge comes from the actual pre-training phase, and we are not developing a new base model.
Neither will fine-tuning act as a search engine, the model won’t remember every detail from the process. If you’re looking for specific info from your sources, you need RAG (retrieval augmented generation).
If fine-tuning isn't regular learning, and nor is it helping our AI remember specifics, then just what is it for? To put it simply, we’re making it understand the fine-tuner’s own world model better—familiarizing the LLM with patterns important for the context it needs to operate in. We’re teaching it behavioral patterns, expected outputs—a certain way of communication, rather than allowing it to act like it would based on pre-training.
We present examples it’ll need to mimic in style, length or in any other regard really.
For this, we usually give questions and answers or instructions and completions as examples, because we all interact with LLMs in the form of prompts (the equivalent of questions), to which they provide outputs (the answers).
You don't have to manually write tens of thousands of examples, thankfully. Another LLM can assist with converting your context into Q&A format in an elegant, automated manner. This is called synthetic data generation.
Is It Worth the Hassle?
Luckily, the server costs of fine-tuning even a 7B model is in the $100 range. LLMOps, your cloud provider, the overhead of running a model and all that still cost money, but the whole ordeal is actually quite cheap for the value you’re getting.
The steps in our mock case went like this:
1. Loaded the Mistral base model with quantization to keep memory requirements below 5GB.
2. Set parameters for LORA, our selected fine-tuning approach.
3. Set parameters for deep learning, such as epochs, batch size and learning rate.
4. Started the fine tuning process, continuously pushing to HuggingFace for version control.
5. Leveraged MLflow within Databricks for training monitoring and experiment tracking.
Once done, the customized model had a deep understanding of what to do, especially when encountering the kinds of prompts it had seen in the fine-tuning examples.
Attention is all you need
You can influence how much attention the LLM pays to new info brought in by fine-tuning and how close it stays to the original pre-training knowledge.
But how to adjust the weights, and which layer to intervene in? How much do you need to fiddle with parameters?
The answer will vary for different base models, so ML engineers should definitely be involved at this point.
Of course, there are some easy rules of thumb: like, it's worth intervening into linear layers, less so into the feed-forward.
Why all this intervention?
Non-fine-tuned models don't necessarily know, for example, what length of answer to give.
When you ask ChatGPT a simple question, it tends to output pages worth of unnecessary information. But if you fine-tune it, the model will instantly understand what length, style and depth of answers you prefer depending on the context—without any pre-prompting and during all new sessions.
It will have already identified the end-of-sequence tokens (end of sentence, end of thought, end of context) in the examples you’ve given, and would be able to replicate your preferred format.
There are 4-6 message exchanges per data point, and not just 2 (so not just a single pair of Q&A), to let the model learn more context. This figure means that text consisting of 4-6 message exchanges is about 150-200 tokens, and the longest data point is ~850 tokens. That's why Kristóf limited his model's context to 2048, which was more than enough.
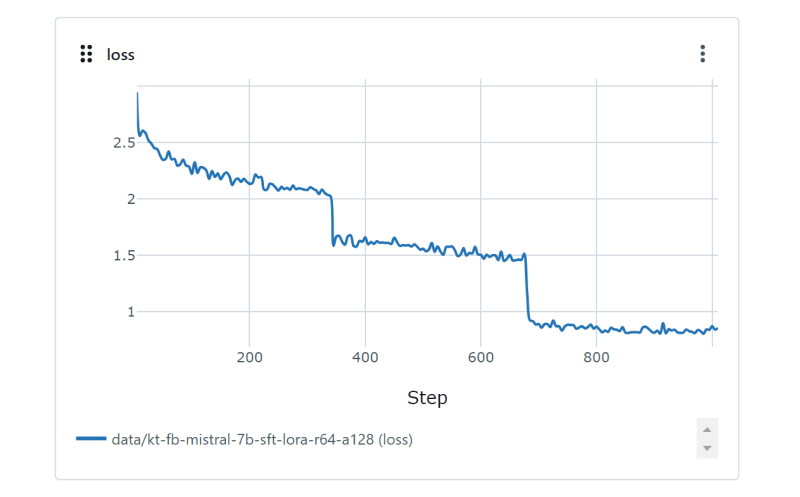
The three distinct plateaus represent three epochs (three passes through the whole dataset).
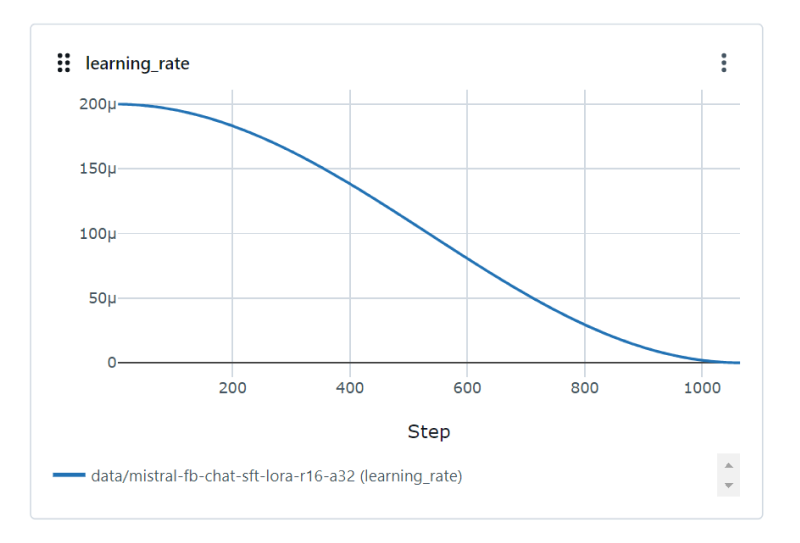
You can also see on the MLflow interface that Kristóf consistently decreased the learning rate to avoid overfitting (decreasing learning on the data over time). There were ~1000 steps for three epochs—the model tuning itself around a 1000 times.
Then, there’s inference. The original base model and the fine tuned parameters are joined, and this final model then applies its learned knowledge to make predictions and generate outputs based on new, unseen data. This is where the fun begins.
Let’s finally see something hands-on.
Practical Applications
So we have our Lead Data Scientist, who fine-tuned a Mistral model with an ethically sourced dataset, just for the sake of our demonstration here.
What’s the dataset? The chat history with his girlfriend, going back six years.
<|KRISTÓF|>
Mit szeretnél holnap csinálni?
<|MISTRAL|>
Hat ha nem lesz rossz ido akkor lehetne kis seta a varosban.
You probably don’t speak Hungarian, so let us translate.
<|KRISTÓF|>
What do you want to do tomorrow?
<|MISTRAL|>
Well we could take a walk in the city if the weather’s nice.
The most interesting part?
Mistral had hardly seen any Hungarian sources during its pre-training, however, it learned to speak Hungarian from only 80.000 messages exchanged between two people, roughly 40k questions and 40k answers.
For what it’s worth, fine-tuning can give hell of a boost to understanding your context.
While a bit more cumbersome than RAG, if it fits the use case, going the extra mile will definitely pay off.
Business Implications
When is this technique applicable in an enterprise setting?
Imagine a data team. They’ll run tons of SQL queries daily, hitting up databases, building dashboards, reports, stuff like that. Now, imagine if you could converse with the company database in plain English, without the data team as a middle-man. And if this AI tool not only used English-to-SQL translations to run queries for you, but also knew the preferred coding and reporting style of your data professionals—wouldn’t that be something?
For a legal department, having an AI assistant who can not only search the code of law, but also be familiar with forms and contract management process frequently used by your firm—wouldn’t that be just great?
These are exactly the types of projects we’ve been working on lately.
But let us add, this isn’t about replacing anyone’s job. We are only eliminating work about work, freeing up time to be more productive in meaningful ways. Less drafting, fewer information silos, no days wasted on legwork. Each move is more impactful. That’s why we love AI.
Fine-tuning has many use cases, and many times you’re better off with other methods. Either way, the new norm in the age of AI will be a democratization of tech, conversing with data in real-time, and more reliable automation.
And we are here to help our partners every step of the way.


