


How I Learned to Stop Worrying and Love the Deployment
“Deterrence is the art of producing, in the mind of the enemy… the fear to attack!” — Dr. Strangelove (1964)
🌀Why all the fuss?
Time and time again, we stumble upon issues not entirely dependent on us, such as missing source data provided by a third-party supplier. This can be either due to server downtime, rebuilding tables, schema/object name changes, missing access rights or expired access tokens given to the service accounts or the analytics team.

So data is not trustworthy after all?
When this happens, it’s a doomsday machine because it’s either garbage in, garbage out, or entire deployments are halted due to missing object references or test failures. Before we get into the specifics of production gatekeepers and source data replication, let’s go over how we got here.
- Benn recently wrote about how data contracts can prevent us from “serving bad food from the kitchen” with a simple technical (within stack) solutions designed for data teams.
- David, advocate of data quality, described an optimal data contract and highlighted important points about the means of communication between parties.
- Tristan wrote briefly about his concerns on the responsibility side when the contracts are made.
By no means, I’m an expert in this topic, but if I had to define the term, I would say that it’s the means needed to bridge the gap between data providers and the data team. Schemas?! Contracts can also be associated with the emerging trend of semantic layer, which would allow us to robustly scale our codebase and centralize business metric definitions. Put simply, elements needed to avoid communication failure and to be on the same page.

Gee, I wish we had one of them doomsday machines! — Gen. Buck
In terms of responsibility, who’s to blame? The committee, or the one who launches the doomsday machine? (And even if we find who to blame, the deployment is blown — and users are mad at us…)
My take on data contracts (agreeing with David) is that it was considered normal for a data engineer to fix a broken pipeline. Information can flow through organizations very slowly, especially when priorities do not align between the data provider and the analytics team. When that happens, we usually implement a “custom fix” to amend the issue temporarily and move on with our life.
Usually what happens when we took our eyes off the backlog for a moment.
This is completely fine if we are a fast-paced team, and we know that fixing the issue takes time. On the flip side, it hurts the core logic of our data model by introducing custom (oftentimes not well documented) logic — to be refactored in the future, slowing down future processes.
For myself, I like tackling the tech debt, but it’s hard to convince management that it is worth the investment…

source: Vincent Déniel
So what can we do? In the last year, we have seen/developed many creative ways to overcome external dependencies and protect our production data on Snowflake and BigQuery from being infected with bad data.
❄️ Snowflake
🟦🟩 Blue/Green Swapping
This is probably the de-facto way for Snowlake and dbt users to deploy to production. Tldr: Blue just becomes green behind the scenes, but nothing about your queries would have to change. I don’t feel like elaborating much on this topic, as the community and folks from Montreal Analytics have already discussed this profoundly:
⚠️ Limitations:
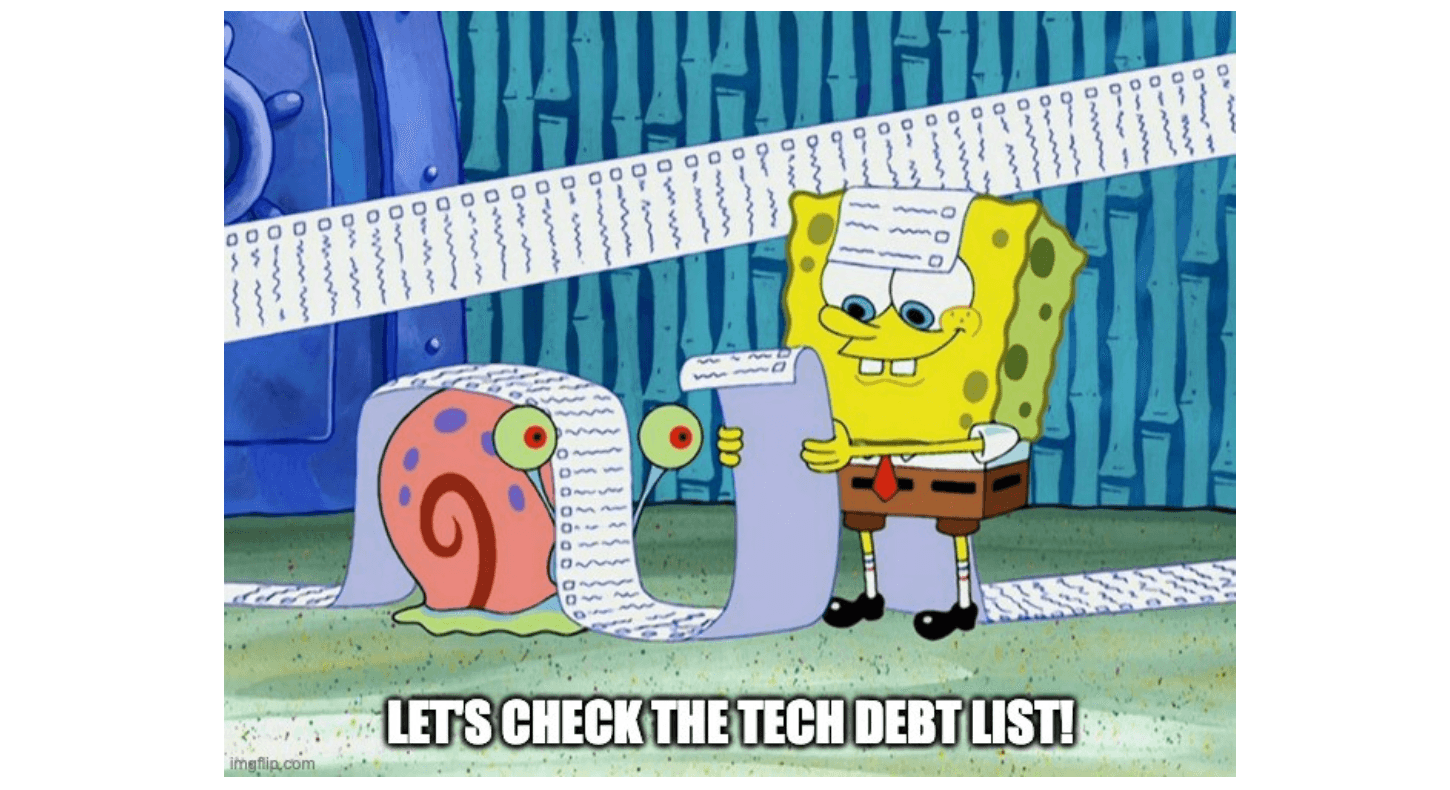
As former productiontables get demoted to stagingvia the swap feature, the next incremental load will build on top of obsolete tables in staging before swapping.
Let me break it down to you:
- T: Imagine that our run fully refreshes the data in staging, then swaps it with the production database in T-1
- T+1: A new production cycle is due, but only certain data sources have to be processed again, so you decide to go with an incremental refresh.
- T+1: You then wonder why all the information we updated in T is missing?
How blue/green fails incremental build
Well, since we built on top of a production data in T-1 before swapping again, the information loss is the difference between staging and production in T!
🧻 Production Rollbacks
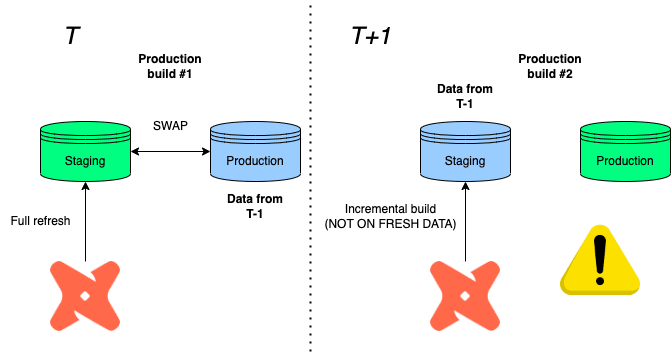
Sean has described another alternative for detecting bad data and restoring the previous version, which then later was demo-ed by Sun. Instead of swapping databases, (1) we copy the previous production data to a staging environment, (2) rebuild the tables under scope, then (3) clone it back to production.
This also works with incremental models, because we always clone back the latest production loading before building on top of it.
Production rollback example
🔍 BigQuery
Unfortunately, swapping is not possible (or cumbersome) on BigQuery, so the idea is to run & test all models before loading it to the production environment instead. BigQuery is not able to rename datasets, therefore, swapping by renaming with subsequent commits is ruled out.
Sometimes we all miss Snowflake (source: dbt slack)
WAP
Folks at Catalogica have proposed a way a while ago to overcome these limitations. Their solution is called WAP (Write-Audit-Publish).
- Builds all in an audit staging dataset
- Re-build only top level models under the activation (BI) layer in prod again (testing is optional here).
- Traffic is stopped if the build failed in the audit environment.
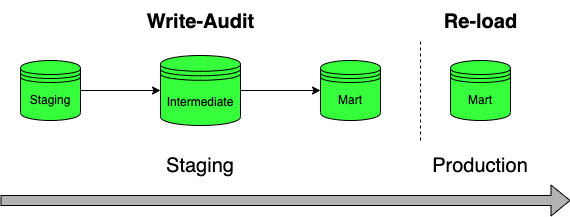
Write-Audit-Publish by Catalogica
WAC
Since BigQuery announced their Table Cloning feature this year, we came up with an extended strategy called WAC (Write-Audit-Clone) — coined by Hiflylabs.
Instead of rebuilding with an additional cost, let’s clone the top-level tables with the mart tag from stagingto production !
Note that the prerequisite of cloning top-level tables is that you have a well-layered project either with tags or clear-cut folder structure.
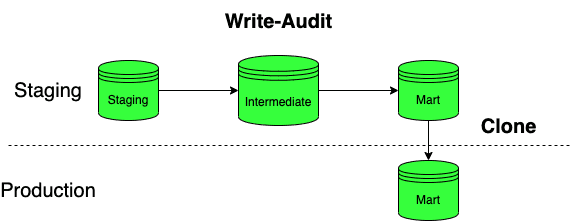
Write-Audit-Clone by Hiflylabs
The full-blown macro below is able to implement this logic by following the steps below.
- Collecting top level tables (
mart,utils) by querying the graph context variable for tags (you can also use relative paths). - Since sets are not supported in Jinja, we need either create a custom macro for finding any intersections between our chosen tags and tags compiled from the
manifest.jsonor check element by element.
Gee, hidden Dr. Strangelove quote, Josh?
3. Finally, we create or replace filtered tables (we can’t clone views!) in mart, utilsby cloning analytics_staging.
Note that there is a custom logic here. First, the macro was written in a way, so it is able to copy between different dataset (=schema) structures.
This has been tested and implemented on projects with advanced custom schema strategies like generate_schema_name_for_env.
If you are using similar building in staging and production with the same custom schemas, feel free to reduce this code to a couple of lines!
{% macro write_audit_clone() %}
{#
EXPECTED BEHAVIOR:
1. Loads every table to a single dataset (this requires using a different target name than 'prod')
2. Gatheres all the model/table names maching with the supplied tags
3. We redistribute the tables to the correct datasets in production depending on the tag (=dataset)
4. Works well with generate_schema_name_for_env macro (!!)
#}
{% if target.name == 'staging' %}
{{ log("Gathering tables to clone from...", info=True) }}
{% set tables = dict() %}
{% set tags_to_clone = var('tags_to_clone', []) %}
-- create empty dictionary for table-tag mapping
{% for model in graph.nodes.values() %}
{% for tag in model.tags %}
{%- if tag in tags_to_clone and model.config.materialized == 'table' %}
{% if tag not in tables.keys() %}
{% do tables.update({tag: []}) %}
{% endif %}
{% do tables[tag].append(model.name) %}
{%- endif %}
{% endfor %}
{% endfor %}
-- log the process
{{ log("Cloning in progress...", info=True) }}
-- iterate through all the tables and clone them over to chosen destination
{% for key, value in tables.items() %}
-- create prod schema if not exists
{% set sql -%}
create schema if not exists {{ key }};
{%- endset %}
{% do run_query(sql) %}
{% for item in value %}
-- log the process
{{ log(target.project ~ '.' ~ target.dataset ~ '.' ~ item ~ ' -> ' ~ target.project ~ '.' ~ key ~ '.' ~ item, info=True) }}
{% call statement(name, fetch_result=true) %}
-- copy from single analytics_staging schema but distribute to different schemas in prod
create or replace table
{{ target.project }}.{{ key }}.{{ item }}
clone {{ target.project }}.{{ target.dataset }}.{{ item }};
{% endcall %}
{% endfor %}
{% endfor %}
{{ log("Tables cloned successfully!", info=True) }}
{% else %}
{{ log("WAC is only supported on staging! Process skipped...", info=True) }}
{% endif %}
{% endmacro %}WAC for generate_schema_name_for_env
Include list of tags to clone in project.yml
vars:
tags_to_clone: ['mart', 'utils']
Then you set the target.name to stagingand call the macro at the end of your production build.
#build it in analytics_staging
dbt seed
dbt snapshot
dbt build#copy marts and utils layer to production
dbt run-operation write_audit_publishVoilà, you have a robust, nearly zero-additional-cost way to deploy safely to production!
⚠️ Limitations:
- We can’t copy views (not usually the case for objects powering the BI layer)
- Additional storage (negligible) cost incurred on the difference between clones and source tables
- More on cloning limitations here
G2K: 🪞Mirror layer
What if we just add another layer to our project that copies the source tables? That means that we are acting as pseudo data providers!
Structurally, the project would be extended with a raw layer just before staging which copies the source tables 1:1:
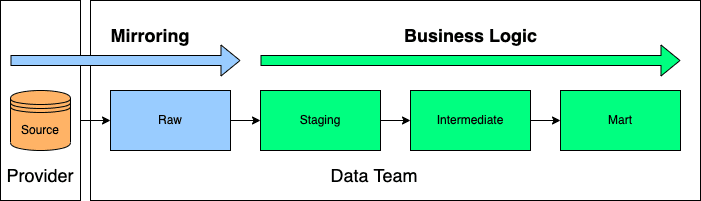
An additional layer bringing through the source data as it is.
In very simple terms, each model would just include a select * from the source and materialize it as a table.
with source as ( select * from {{ source('name', 'table') }}),
This layer then would be separated from the dev/production main build job and refreshed manually when needed. Yes, it doesn’t sound right, and oftentimes are not worthy to implement in cases where the data arrives in micro-batches or through streaming.
A source data refresh job would only build (and test) the source data again:
#assuming that you have project tags
dbt build -s tag:raw
The production job then would build from the staging layer.
#build it from staging
dbt build -s tag:staging+
⚠️ Limitations:
- Reprocessing one additional layer without any change in data → Additional processing and storage costs
- Manual refreshing of source data → loss of automatically provisioned data
- Can only be used on projects where the data is “slowly changing”
💡 Why should you care?
Because, we always find ways to make the dbt experience as smooth as possible.
Using WAC in production is not a mere concept, it was well tested, implemented by our team of analytics engineers and to this day, possibly the closest to blue/green deployment for BigQuery users, as it has no additional storage and compute costs on top of building your production data (*insert Snowflake swapping appreciation*).
Do share your experience with WAC, and don’t hesitate to hit us up if you have any questions! 🥳


