


powered by App Engine and GitHub Actions
Dbt Docs, as a static website, provides an intuitive way to inspect our project documentation outside of dbt Cloud or our local machine.

Photo by Henry & Co. on Unsplash
Introduction
dbt Docs allow us to intuitively inspect our DAG and dbt project documentation. Along with many of its limitations, we often find ourselves wanting to share this knowledge outside dbt Cloud or our local machine.
Suppose we want to share this with our stakeholders. Then, they have to have a Cloud viewer login, which is at least $100 a seat as of today (assuming that you are a relatively small organization), and going through 4–5 steps just to get to the documentation, which is no good.
There should also be a solution for those who are only using dbt-core and handling scheduling and CI/CD with Airflow and co. plus any integration service. There must be something better than paying for an EC2 instance just to keep a static web server there, right?
The official dbt documentation gives you some options, but none of them fits to a GCP* stack, and we still lack the A-Z guide for this.
This walkthrough was created with GCP in mind, but the same could be applied to all other cloud service vendors.
Options
Although it is still an open issue, luckily the community delivered again, and we are able to deploy our docs in a very straightforward way on a static website, where the cost of hosting is actually zero.
There are actually three ways to do this:
- Fast and easy way: Hosting with App Engine
- Slow and more painful, but cleaner way: Hosting a static website from GCS.
- Fastest and easiest, but needs access to repo: GitHub Pages
The cost difference between all these? Close to zero. They are all free if you don’t have a lot of incoming network traffic.
For the rest of this article, I’m going to walk you through the process of deploying to App Engine. Here, we don’t have to register our custom domain, configure an HTTPS load balancer or find alternatives for setting up IAP on backend buckets. All in all, there is no operational cost whatsoever on serverless products.
GitHub Pages is also ruled out in many cases, because if we want to make the documentation private, it’s going to only be accessible for those who also have access to the repository, therefore have GitHub accounts.
Just like with lots of other services, Google offers a free quota for App Engine which you are not likely to use up, given that it is a static website and the deployment is going to happen now and then. Knowing this, GCP allocates the smallest virtual instance to do the light work.
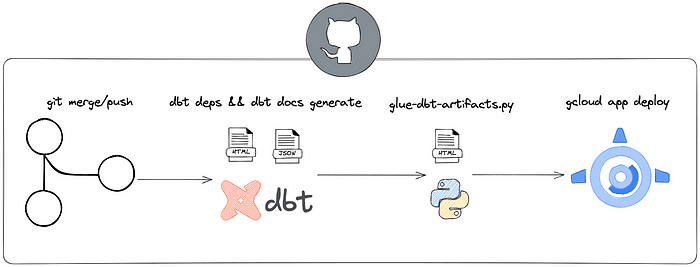
High-level deploy plan
Step 1. Setup App Engine!
Google App Engine is a cloud computing platform as a service for developing and hosting web applications in Google-managed data centers.
Requirements:
- Google Cloud CLI: https://cloud.google.com/sdk/docs/install
- Deploy file
app.ymlin your dbt project’s root directory
service: default
runtime: python311
handlers:
- url: /
static_files: public/index.html
upload: public/index.html
- url: /
static_dir: public
- url: /.*
secure: always
redirect_http_response_code: 301
script: autoTranslating what’s above,
- The deployment uses Python 3.11 in runtime,
- Uploads and serves static
index.htmlfrom the target directory, where you are storing the docs artifacts - Maps the root URL to the docs file.
- The /.* handler matches all other URLs and directs them to your app.
More on app.yml configurations here.
Cost of hosting:
Free tier (static website runs on ‘F’ instance)

App Engine Free Tier
Instance hours are displayed here, which means you are charged for the time it’s active +15 minutes (every time an instance spins up), because it remains active after the last request.
If you have few requests, but they are spaced out evenly, your instance would shut down, and you’ll incur the 15-minute charge the next time the instance spins up again.
After you surpass the free tier limit, the following billing scheme applies per hour (depending on the location).
In our case, there is no outgoing network traffic (egress), so feel free to ignore that part of the billing.
Tldr:
28 hours of instance time per day for free, then a couple of cents per instance hour.
It’s literally free for companies who rarely check the website. However, when queries requests are arriving in a way that we have to restart the instance each time, the quota can be easily surpassed, but let’s be honest the cost is still bearable.
Standalone dbt docs
Huge thanks to Data banana!
If you want the static docs to work locally without running a local web server, you can put the content of the JSON files (manifest, catalog) directly in index.html and remove network loading.
Now, you can:
- Directly open the
index.htmlwithout CORS restriction in local - Upload and host the documentation in some cloud storage, like Google Cloud Storage. As of this moment, this is not the case yet.
- Easily distribute it to your stakeholders via email and co.
import json
import re
import os
PATH_DBT_PROJECT = ""
search_str = 'o=[i("manifest","manifest.json"+t),i("catalog","catalog.json"+t)]'
with open(os.path.join(PATH_DBT_PROJECT, 'target', 'index.html'), 'r') as f:
content_index = f.read()
with open(os.path.join(PATH_DBT_PROJECT, 'target', 'manifest.json'), 'r') as f:
json_manifest = json.loads(f.read())
# In the static website there are 2 more projects inside the documentation: dbt and dbt_bigquery
# This is technical information that we don't want to provide to our final users, so we drop it
# Note: depends on the connector, here we use BigQuery
IGNORE_PROJECTS = ['dbt', 'dbt_bigquery']
for element_type in ['nodes', 'sources', 'macros', 'parent_map', 'child_map']: # navigate into manifest
# We transform to list to not change dict size during iteration, we use default value {} to handle KeyError
for key in list(json_manifest.get(element_type, {}).keys()):
for ignore_project in IGNORE_PROJECTS:
if re.match(fr'^.*\.{ignore_project}\.', key): # match with string that start with '*.<ignore_project>.'
del json_manifest[element_type][key] # delete element
with open(os.path.join(PATH_DBT_PROJECT, 'target', 'catalog.json'), 'r') as f:
json_catalog = json.loads(f.read())
# create single docs file in public folder
with open(os.path.join(PATH_DBT_PROJECT, 'public', 'index.html'), 'w') as f:
new_str = "o=[{label: 'manifest', data: "+json.dumps(json_manifest)+"},{label: 'catalog', data: "+json.dumps(json_catalog)+"}]"
new_content = content_index.replace(search_str, new_str)
f.write(new_content)First Deploy
Now that we have everything set up to make our first deploy manually, let’s see if it works!
You have to make sure that index.html keeps updating in the public/ folder with glue-dbt-artifacts.
Authenticate with gcloud
gcloud auth application-default loginDeploy and inspect
gcloud app deploy --project my-project --quiet
gcloud app browse --project my-project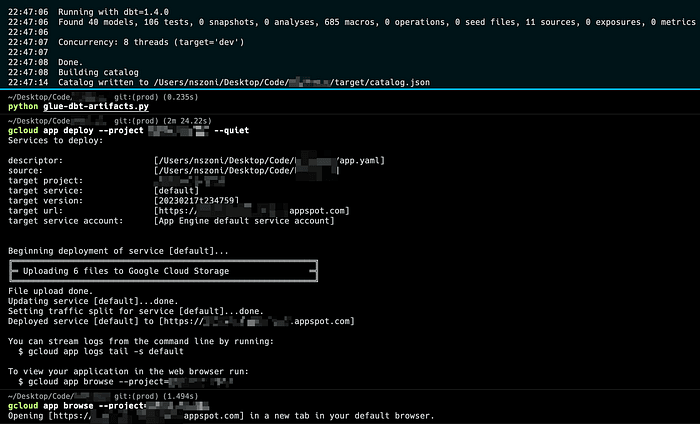
Docs generate > glue artifacts > deploy > browse
You should be prompted to a new browser tab with the dbt Docs which means your docs is live!
You can also set up your custom domain.
Step 2. Manage Access with IAP!
By now, your static website is live, but also open to the public, which is not what we want.
Identity-Aware Proxy intercepts web requests sent to your application, authenticates the user making the request using the Google Identity Service, and only lets the requests through if they come from a user you authorize.
For this, following Step 1. of the codelabs guide should be enough.
This guides you from having a public static website to full access control of Google IAM resources via OAuth.
It’s handy if your organization is Google Suite-first, because it is possible to add groups as well, meaning you can also restrict the access to your company’s domain. This is where Google Cloud Platform really shines.
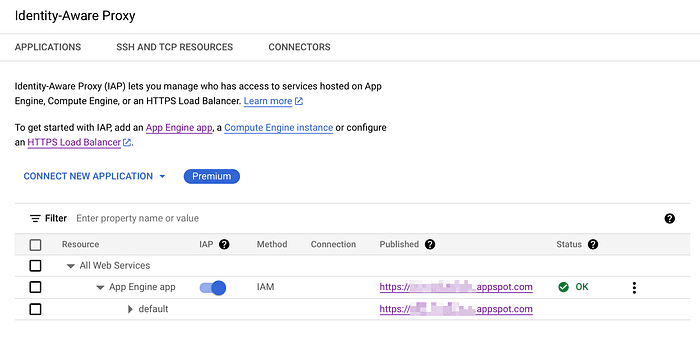
You should see something like this with IAM switch on
Step 3. Deploy with GitHub Actions!
So, there you go, now you have a secured website. What’s next is to find out how to periodically deploy dbt Docs to App Engine. There are a handful of solutions that can work (e.g. scheduled custom script hitting the Cloud and AppEngine API), but some are cumbersome and don’t solve the issue for core-first users.
Github Actions has been here for a while, and it’s free up to 2,000 CI/CD minutes/month (unlimited for public repositories) if your (small) organization is on the Free plan, which should be enough.
More on GitHub Actions billing here
The workflow below.
- Initializes secrets; you can set your secrets on GitHub
- Defines trigger strategy (on merge/push to the
prodbranch) - Use Ubuntu as base image, checkout out the repo, replicate key file for
gcloudCLI - Install Python + dependencies
- Generate dbt docs
- Standalone
index.html - Authenticate and deploy to App Engine
Store this in .github/workflows/<your_workflow_name>
# This is a basic workflow to show using this action
# name of the workflow
name: Deploy dbt docs to Google AppEngine
env:
DBT_PROFILES_DIR: ./.github/
DBT_GOOGLE_PROJECT_PROD: ${{ secrets.DBT_GOOGLE_PROJECT_PROD }}
DBT_GOOGLE_BIGQUERY_DATASET_PROD: ${{ secrets.DBT_GOOGLE_BIGQUERY_DATASET_PROD }}
# The DBT_GOOGLE_BIGQUERY_KEYFILE_PROD secret will be written to a json file below
DBT_GOOGLE_BIGQUERY_KEYFILE_PROD: ./service-account.json
# Controls when the workflow will run
on:
push:
branches: [ prod ]
# Allows you to run this workflow manually from the Actions tab if needed
workflow_dispatch:
jobs:
deploy-docs:
name: Deploy dbt docs to Google AppEngine
runs-on: ubuntu-latest
permissions:
contents: 'read'
id-token: 'write'
steps:
- name: Checkout
uses: actions/checkout@v3
# get dbt service account keyfile
- name: Get SA keyfile
run: 'echo "$KEYFILE" > ./service-account.json'
shell: bash
env:
KEYFILE: ${{ secrets.DBT_GOOGLE_BIGQUERY_KEYFILE_PROD }}
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: '3.10.x'
- name: Install dependencies
run: |
pip install -r requirements.txt
dbt deps
# compile latest version of docs
- name: Generate dbt docs
run: |
dbt docs generate
# glue together index, manifest, catalog and run_results to a standalone html file
- name: Glue dbt docs elements
run: |
python glue-dbt-artifacts.py
# authenticate with appengine service account
- name: Authenticate with SA
uses: 'google-github-actions/auth@v1'
with:
credentials_json: '${{ secrets.GOOGLE_APP_ENGINE_DEPLOY_KEY }}'
- name: Deploy to AppEngine
uses: 'google-github-actions/deploy-appengine@v1'
with:
project_id: 'gcp-project-name'
flags: '--quiet'Step 4. Test Your Workflow!
When it comes to testing GitHub Actions, we can use act to generate test cases (imitate push event). Act spins up a Docker instance of your choice* and runs the actions in a context of what triggers it.
*You have to have Docker installed on your desktop GitHub - nektos/act: Run your GitHub Actions locally 🚀"Think globally, act locally" Run your GitHub Actions locally! Why would you want to do this? Two reasons: Fast…github.com
We can supply GitHub secrets in multiple ways, but I chose to do so with a secret file (defined the same way as a .env file). Note, we have to do this because we are not touching the remote repository, so the secrets you have already set up are not within scope.
Those who are running this on Apple Silicon will likely experience some compatibility issues, so I suggest to spin up an AMD container instance instead.
act — container-architecture linux/amd64 — secret-file ‘my.secret’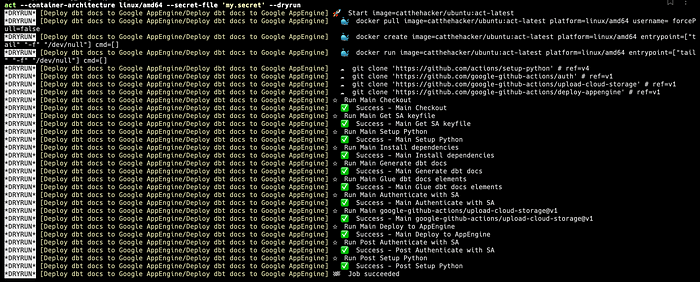
You can also run act — dryrun to see the plan
Limitations of dbt Docs as a Static Website
Live metrics on artifact
Deploying on each push to the main branch, we assumed that the documentation only changes at those events, but it is rarely the case. Table/model metadata evolves over time (rows, size, etc.) without changing anything in dbt inducing a push event.
Displaying sensitive images in docs
I still haven’t found a good way to display sensitive images referenced in dbt docs. I have tried hosting those images on GCS and restricting the access to the same Google group, but it seems that App Engine is not able to extrapolate the authentication.
Conclusion
In a nutshell, I just gave you an A-Z guide on how to host and test your dbt Docs on a GCP stack. It barely costs any money, and keeping the documentation up-to-date is seamless with GitHub Actions. Also, since you have a standalone .html file, you can make all other sorts of distributions within your organization. There are some limitations to it, but I think this is currently the best way to bring data democratization further in the dbt community.


