


Explore the Data Mesh model in layman’s terms: a decentralised strategy for improved management and scalability. Empower each department with control and access to their own data!
Key Takeaways:
- The Data Mesh is a novel architectural concept that decentralizes data management. Instead of a central data warehouse or data lake, we're allocating responsibility to various domain teams, each acting as their own mini-database.
- This model shortens the path between person and necessary information, increasing efficiency and empowering each department with data ownership and control. This simplifies data accessibility, improves data quality, and fosters faster data-driven decision-making.
- Ideal for businesses suffering from data silos, slow delivery, or poor data quality, the implementation of a Data Mesh can greatly improve data infrastructure, provided the organization is ready for autonomy and accountability, with an established culture of ownership and value understanding.
- Implementing this model requires a major shift from central to distributed control, robust governance policies, and high technical maturity. This can lead to difficulties, especially in terms of data literacy, consistent definitions, and compliance risks.
- The mesh model can work for both small to medium-sized enterprises (SMEs) and large corporations. Read on to get the full background:
According to Talend’s 2022 annual report, 99% of companies recognize that data is crucial for success. Despite economic turbulence and a currently slowing market, investment in data-related initiatives continues to soar. Remarkably, a reported 87.8% of organisations amplified their commitments in this sphere during 2022.
Source: Talend Data Health Barometer 2022
Moving towards 2024, about 94% of organisations are planning to crank up their data investments even more. Only about 6% are thinking about trimming their data spending.
However, a formidable challenge lurks within these promising statistics. A concerning 97% of organisations have confessed to encountering difficulties in effectively utilising their data.
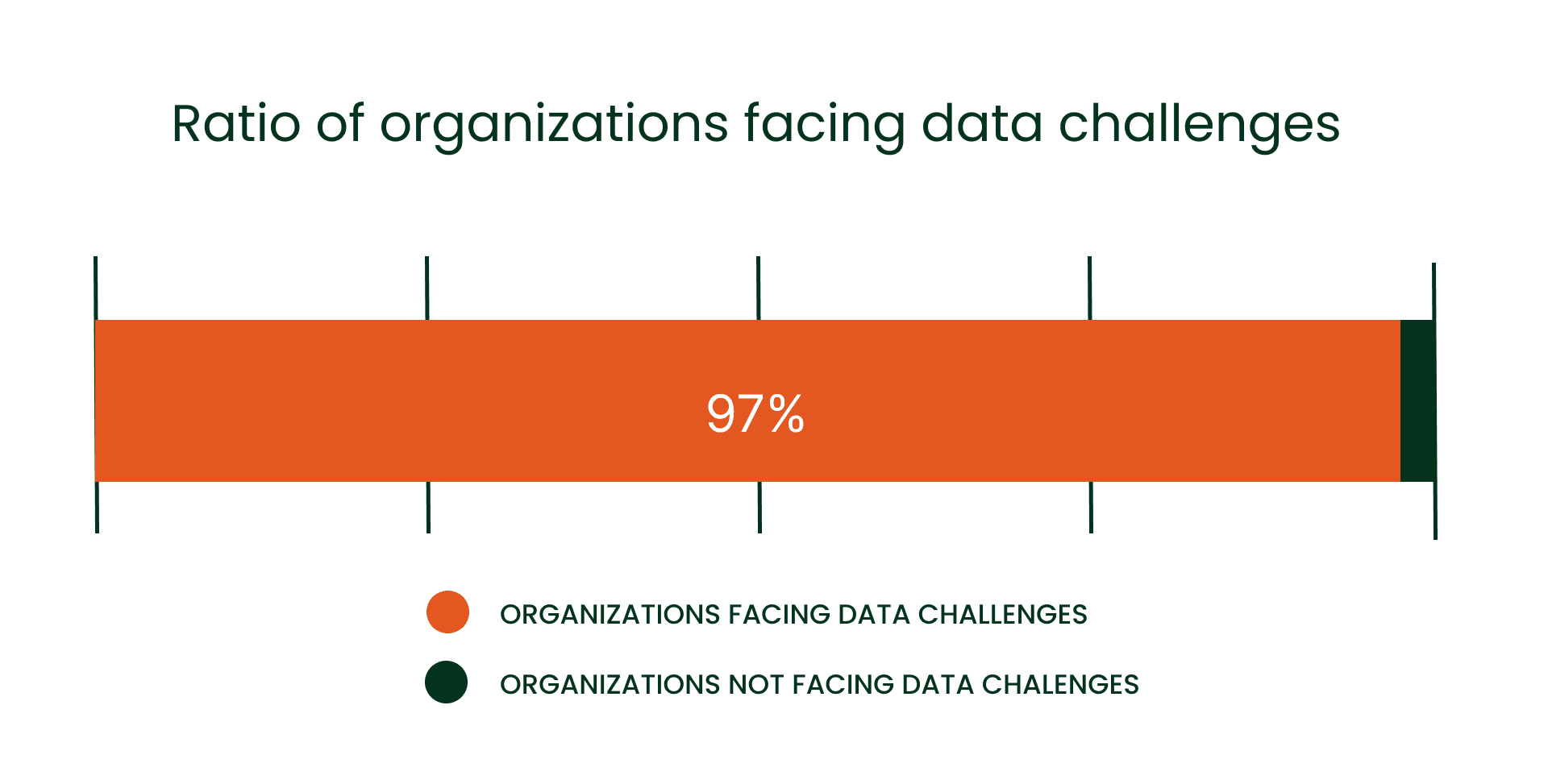
Source: Data and Analytics Leadership Annual Executive Survey 2023
Business leaders have voiced a common grievance. Their significant investments in data have not manifested in tangible results. Why is that?
Reality is much more complex and multifaceted than the digital footprints we leave, or any models we can create. And even if this wasn’t the case, investing in data will mostly yield indirect returns.
So let's take a step back and rethink whether your hopes for insights from big data are realistic. Then, let's look at the pace of tech changes your business needs to keep up with. After that, think about how your company is currently sourcing and collecting data. In this context, discerning whether a Data Mesh would serve you better than traditional solutions might be a point of consideration.
Data Mesh emerges as a potential solution to some predicaments, particularly in addressing challenges such as:
- Preventing data silos and bottlenecks
- Ensuring data is only shared with appropriate parties
- Compliance adherence
- Democratisation of data control
- Rapid data access
The Future of Data: A Layman's Perspective
Picture this. In 2021, the world churned out roughly 79 zettabytes of data; by 2025, this number is predicted to double. This year alone, we will generate nearly three times the data generated in 2019.
Given these staggering stats, it's not surprising that 43% of tech decision-makers are losing sleep over whether their IT setup can handle the data demands of the future.
It’s not that today’s data solutions were not designed to handle such vast quantities of data effectively. It's not just about "data architectures," but also "organisational architectures" and "people's competencies."
If there are no usable roads and people can't drive, then you’re practically stuck—regardless of the quality of the car.
The Sticky Situation with Current Data Architectures
Businesses get how valuable data is. But sometimes the way things are set up doesn't let them get the most out of their data. Here's why:
- Old-school models are centralised and bulky, relying heavily on IT and tech teams.
- Data quality gets murky because the people wrangling the data aren't as clued in on it as the folks who created it.
- Scaling data can be a headache because of tech limitations.
- Today’s data platforms are usually massive systems built on a large scale, using complex data pipelines to store information in centralised storage.
A Data Mesh shakes things up by swapping pipeline complexity for system complexity. Now, there are times when this could work, but it's far from a walk in the park to design and manage these distributed systems.
Having all your data in one spot isn't necessarily a bad thing (depending on what you mean by "one spot," of course). For instance, a company-wide data lake might be centralised storage, and it's probably a smart move to let every team run their own slice of this storage solution. But when organisations are set up in a way that causes data logjams, and when data sharing between organisations gets sticky, that's when centralised storage can trip you up.
So, when should you consider moving to a Data Mesh setup? When your data team keeps complaining about bottlenecks and they're struggling to keep up with the barrage of questions from managers and product owners.
Often, data teams burn most of their time wrestling with the convoluted infrastructure of data pipelines. This leaves little time to actually mine insights from the data.
Plus, to answer questions, like "What price should we set for our products on Black Friday?" or "How will increasing our stock affect our supply chain?", the data team needs to have a deep understanding of the business.
The tricky part is that some data is hoarded by business teams and not shared with data engineers—so it doesn't make it to the central data centre.
For example, the marketing team can share some key measurements that are distributed to the data centre. Still, at the same time, they keep specific marketing information, like website visitors at a particular period, that is not distributed to the data centre. So, some information remains siloed while other information is distributed - this way, there is no reliable way to make effective data-driven decisions.
And the larger the organisation, the messier data handling gets.
Data 101: Data Warehouse vs. Data Lake
Before we delve into the Data Mesh, let's get a handle on how current data setups work - how data is gathered, stored, used and shared.
When it comes to collecting data, Data Warehouse and Data Lake are pretty much on the same page. But what happens after that is a different ballgame.
Data Warehouse
Think of a data warehouse as a giant library of business data that helps a company make decisions. It's like a warehouse full of organised, processed data that's been set aside for specific use cases. Because this data has been sorted and structured, it's easier to analyse and pull information from.
The key benefits of a data warehouse include:
- Speed: They're built for fast access and handling complex queries, so they can quickly cough up results for business analysis and analytics.
- Trustworthiness: They often have systems in place to ensure the data is top-notch.
- Integration: They can merge data from different sources in a consistent way to support well-rounded business analysis.
But data warehouses can cost a pretty penny to keep running. Plus, because they're structured, they might struggle with unstructured data.
Data Lake
A data lake, on the other hand, is like a giant pool of raw data that's waiting for a purpose. It can store any kind of data—structured, semi-structured, or unstructured —from various sources in their original formats. The idea of a data lake is tied to big data and is usually set up using technologies like Hadoop.
The key benefits of a data lake include:
- Scalability: designed to store loads of data, they can grow with your data needs.
- Flexibility: Because they store raw data, you can use different types of analytics to pull insights as business needs change.
- Low Cost: Technologies like Hadoop make it cheaper to store data in data lakes.
But the downside is that because the data in data lakes is raw, there could be issues with data quality and governance. If not managed properly, a data lake could turn into a "data swamp" - a jumbled mess of poor-quality data that's hard to use effectively.
Data Mesh – A Viable Solution?
The Data Mesh isn't a piece of software or an application; it's a concept that originated from the need to address the challenges and inefficiencies of existing data architectures. This solution decentralises responsibility for data, moving it from a central data team to various domain teams. These smaller data centres are then interconnected, enabling communication amongst each other.
In this model, the pathway between person and information based on which one they need to make decisions is as short as possible.
Imagine an organisation collecting vast amounts of data from various departments, like sales, marketing, finance, and customer support. Traditionally, this data might be stored in a single, central system, such as a large database, managed entirely by your IT department.
With the Data Mesh architecture, the approach changes. Data is distributed across multiple systems or units within your organisation, with each unit responsible for managing its own specific area of data. It's as if each department had its own mini-database. For instance, the sales department can manage sales statistics, finance can handle financial data, and so forth. This empowers each department with ownership and responsibility for their own data. Each node in the network maintains control over its own data, even in deciding who can access it.
When to Implement a Data Mesh
One key advantage of Data Mesh is its flexibility: there's no need to restructure the entire data architecture at once, as it can be implemented gradually. It's also an excellent fit for companies with constantly changing and evolving data sources and landscapes, often due to shifts or growth.
Data Mesh is also an ideal solution for companies whose data sources and landscape are constantly changing and evolving, either due to shift or growth.
The application of a data mesh should be considered when certain conditions are met within your organisation.
Firstly, when your business is suffering from issues of data silos, slow data delivery, or poor data quality. These issues often arise as the business scales and the volume and complexity of data grow. These issues can be mitigated by decentralising the management of data and distributing the ownership and accountability to various business domains.
Secondly, if your organisation has adopted a microservices architecture or Domain-Driven Design (DDD) for software development, then a data mesh is the most suitable solution.
Lastly, consider applying a data mesh when your organisation has moved or is moving towards a culture of autonomy and accountability. A data mesh demands a strong culture of data ownership and an understanding of the value of it as a product. If your teams are ready to take responsibility, then a data mesh can significantly enhance your data infrastructure, data quality and the speed at which insights can be gained from your data.
Why is Data Mesh Controversial Among Data Experts?
The Data Mesh is an evolving concept that presents a new framework, reshaping the way we approach data management. However, the shift brings both challenges and concerns.
One of the prominent hurdles lies in the cultural shift needed for implementation. A transition from a centralised team to distributed control demands each department to take charge of their data, which can be a difficult adjustment. This can only escalate if data literacy within teams is not strong, leading to potential misunderstandings or resistance.
Additionally, the data mesh approach poses significant technical challenges. The need for extensive infrastructure alterations, the demand for consistency across all data products in decentralised storage and processing environments, can be daunting. The possibility of inconsistent definitions and models arises, further complicating the process.
For this reason, many experts criticise the data mesh model for its requirements of a strict framework, which is the most effective way to avoid inconsistencies between departmental data nodes. Some data professionals find this solution to be limiting beyond reason, compared to a centralised data infrastructure where data teams can tailor their architecture to their hearts’ desire.
The data mesh also introduces an added layer of complexity in governance and management. Detailed governance policies and comprehensive data catalogues become a necessity to ensure data usage compliance with regulations and the above mentioned consistency between nodes. Harmonising data management practices across various departments and reaching consensus on data products and use cases can be intricate and, if not addressed, can cause confusion or a fallback to older, less efficient methods.
Critics argue that for these reasons the benefits of a data mesh are sometimes overstated and that the value of robust data governance frameworks is underestimated. Yet, the data mesh model, which promotes interoperability and consistency based on domain-driven design, self-describing data, federated computational models and dynamic schemas, has been successfully adopted by several companies. Despite the controversy, it's more than just a passing trend.
Adopting data mesh requires either high technical maturity within your teams or a well-educated data team to guide departments through the transition. It calls for a significant cultural and organisational shift to embrace a product mindset and a decentralised governance model. The distributed nature of data introduces complexity and overhead in terms of data integration, orchestration and coordination across domains. Additionally, it potentially poses risks related to security, privacy and compliance.
Despite these complexities, the data mesh represents an innovative approach to data management and scalability that could revolutionise your data strategy, provided it's implemented thoughtfully and meticulously.
The Fundamental Principles of Data Mesh
Introduced by Zhamak Dehghani in 2019, Data Mesh is based on four principles that aim to shift from the current system-oriented paradigm. These principles are domain and data ownership, treating data as a product, a self-service data platform and federated governance. Collectively, these principles foster an environment where data is logical, clean, usable and, most importantly, accessible to the entire organisation.
- Domain and Data Ownership: This principle asserts that the domain team should manage its own data, ensuring that the data entering the system is logical, clean and usable. This means the data remains close to its original owners. These domain-specific databases can be linked via APIs, making them accessible to various company areas and usable in conjunction with other data sources to generate new business insights.
- Data as a Product: Treating data as a product within companies isn't new. It implies the data needs to be "purchased" and used within the organisation, necessitating care and maintenance similar to a new car. Data needs to be clean, logical and useful, not just for the data owner but for the whole organisation.
- Self-Service Data Platform: A central data-infrastructure team should deliver the necessary technology for data owners to effectively input, use, interact with and export data products.
- Federated Governance: This term means all data within the data ecosystem needs to work together, facilitating analysis of multiple datasets under multiple data owners. This should be managed by a governance group ensuring datasets are interoperable, leading to new insights and actions.
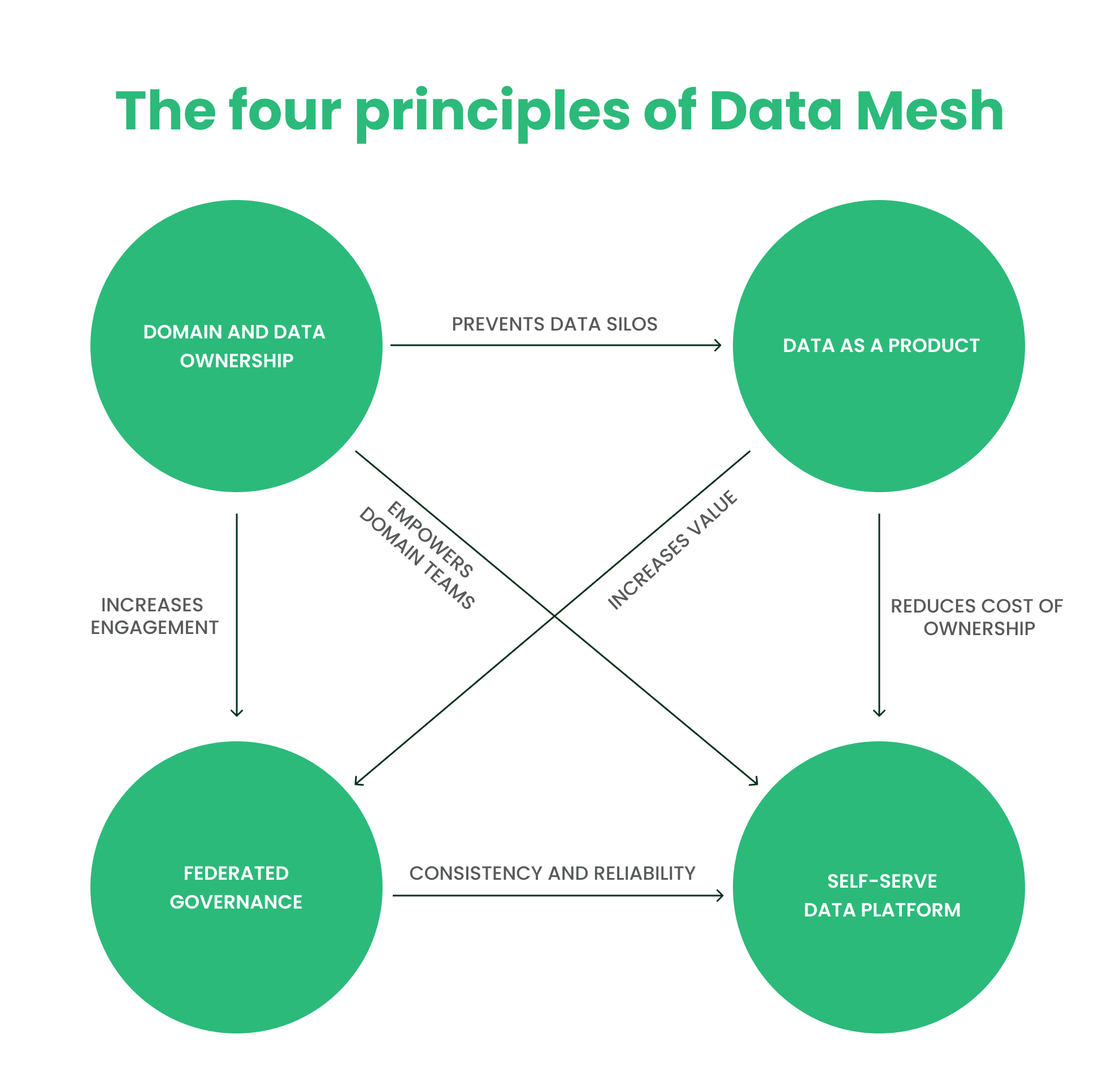
This chart summarises these four fundamental principles of Data Mesh well.
From SMEs to Large Enterprises
The paradigm shift represented by the Data Mesh approach is especially useful in larger, more complex organisations. However, it is just as valuable in small to medium-sized enterprises (SME) as in enterprise-level environments.
For SMEs, where teams are more intimate and cross-functional, a data mesh can simplify data accessibility and accountability. With data distributed across different domains, each team becomes responsible for its own data, reducing the burden on a centralised data team and promoting a faster, more effective data-driven decision-making process. Additionally, a data mesh can enable SMEs to scale their data architecture as they grow, preventing potential issues with data silos and quality.
The mesh model can be downright transformative in an enterprise-level environment, where sources of data are significantly more complex. Larger organisations often grapple with maintaining the quality and accessibility of their data due to siloed structures. Here, the mesh model enables each business domain to function as a distinct data product, managed by its own product owner, ensuring quality, availability and utility. The product owner takes responsibility for their respective department, enhancing reliability and data quality. The decentralised architecture also fosters democratisation within large organisations, allowing more teams to access useful, high-quality information, ultimately stimulating innovation and boosting overall operational efficiency.
Nonetheless, implementing a data mesh does come with its challenges. Culturally, the shift from a centralised to a distributed data model could be substantial and may be met with initial resistance or misunderstanding. Technologically, the decentralisation of data storage and processing necessitates considerable infrastructural adjustments. And from a governance perspective, the data mesh model implies increased complexity, requiring well-defined data governance policies and comprehensive data catalogues.
How We Can Help With the Implementation
Embarking on the Data Mesh journey may seem daunting, given the potential challenges. However, it's important to remember that this doesn't require new technologies or a complete shift in current tasks. Rather, it changes the way data teams handle and think about data. Starting small and setting up your first self-service domain will enable scalable solutions across your company, setting a standard for a data-driven culture where data can reach its full potential as a product.
During such a transformation, data consultancies can provide invaluable assistance. As seasoned consultants in data management, we understand the complexities and challenges of transitioning to a different data architecture. We can offer expert advice on managing the cultural change associated with implementing a data mesh, enhancing data literacy across your teams and fostering a culture of data ownership.
With a little help, your transition to a Data Mesh can be smoother and more effective, enhancing your organisation's ability to leverage data for cost efficiency and growth.


