


Understanding the concept of time is a relatively deep and deeply relative topic in any field of science. It’s not different regarding the standard principles of data warehousing either since we have to describe our own dimensions and decide when facts actually happen. Even more, as analytics and data science build on historical data, we must make our own rules when a record reaches its final state (if there is one at all), and if we have to consider temporal data validity management.
In this post, I try to expose the most important connection between time and validity in data architecture; the needs and reasoning behind them, their consequences (both good and bad), and why and how we should avoid the so-called butterfly effect in data warehouses by properly handling late-arriving data.
Note that some of the concepts in this post are intentionally simplified to make the topic more approachable. For further reading, I suggest that you consult some of the references.
Just a usual Point in Time
For most people, the first kind of data that comes to mind (that has time association) is some kind of “event”. It can be a payment transaction or a telemetry data point, or when a user loads a webpage, etc.
These are mostly captured with a timestamp when the event happens.
These timestamps get loaded into the data platform with the actual data itself.
It’s conceptually trivial what it means and how to use it – from aggregating events into time ranges (“buckets”), through driving the incremental loading of tables, all the way to partitioning data for more optimal access.
In the data world, we often refer to records that hold values that can be “summed up” as facts (or measures).
In "fact" tables, monitoring data flow in the aspect of time is essential.
Hence, timestamping is nearly ubiquitous in these data models.
Dimensions, the keystones of our star-shaped world
The other elements of the most widespread star(like) data warehouse structure are what’s called “dimensions”. Dimensions describe the entities involved in the fact “transactions”. These are users, products, etc.
They are the nouns in sentences that describe what’s happening, whereas fact records represent verbs.
In the simplest case, dimensions have no temporal elements. Most often, only their latest attributes are stored and used. If we learn that they have changed (e.g. a user’s email or a product’s weight), we simply overwrite them.
(The other sensible choice is to use their original attributes, i.e. never update them. While it’s easier to handle for modern analytics technology, it’s usually so inferior for business use, that it is hardly ever used.)
From the Beginning to the End
We often want and/or need a more thorough history that enables us to reconstruct past constellations.
Imagine that you need to tell how your revenue is composed by the clients’ location.
We can join the payment transaction history (fact) with the clients (dimension), and we can easily aggregate revenue by client state (supposing that you have this data for clients).
If you only have their current headquarter though, then – for clients that moved headquarters – you’ll have all (past) revenue appearing as if it came from their current state. This may be what you need – but often, it isn’t. (For example, if we also do it by month, the new report will show different values for past month-state combinations than it did when we pulled it before the clients moved states.) Long story short, we may need historical records for dimensions to keep everything in place in your reports.
There are two basic ways to go about it. One can store the dimension records with all attributes (clients with state, etc.) at each load period (perhaps daily), with a daily timestamp created internally. In this case, it’s trivial to join it to the facts by each date day to learn any attribute on any date. But the same data will often be stored several times in a redundant form. In today’s world, it is not necessarily a problem. Still, even daily loads will multiply your dimension table size 1000-fold in three years.
Slowly Changing Dimensions is the golden middle-ways
However, most dimensions' attributes change rarely, if ever. This is the point where the so-called “Slowly Changing Dimensions” (or SCDs) come into the picture as an alternative approach. In a nutshell, SCDs store dimension records with a validity time range.
For that, two timestamps are stored within each record: when it became valid and when it became invalid. When any attribute value changes in the record, the last record gets updated (i.e. its “expiration”, or “valid to” timestamp is set to when it changed). Then the new record gets appended with the new values, and validity set to “indefinitely from when it changed”.
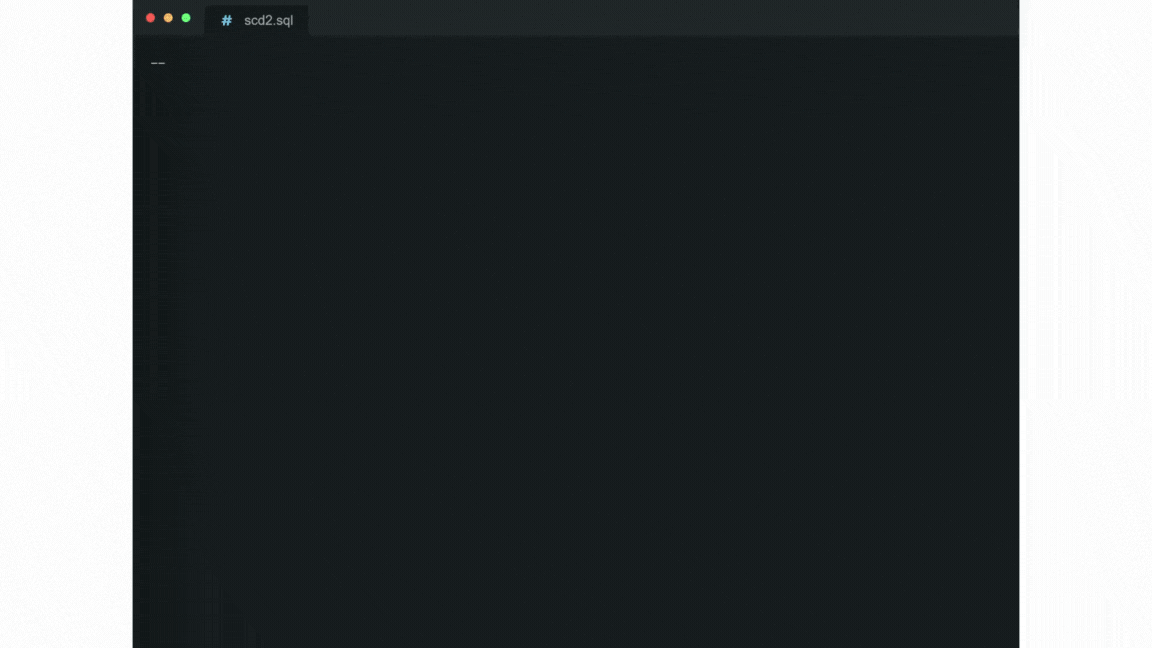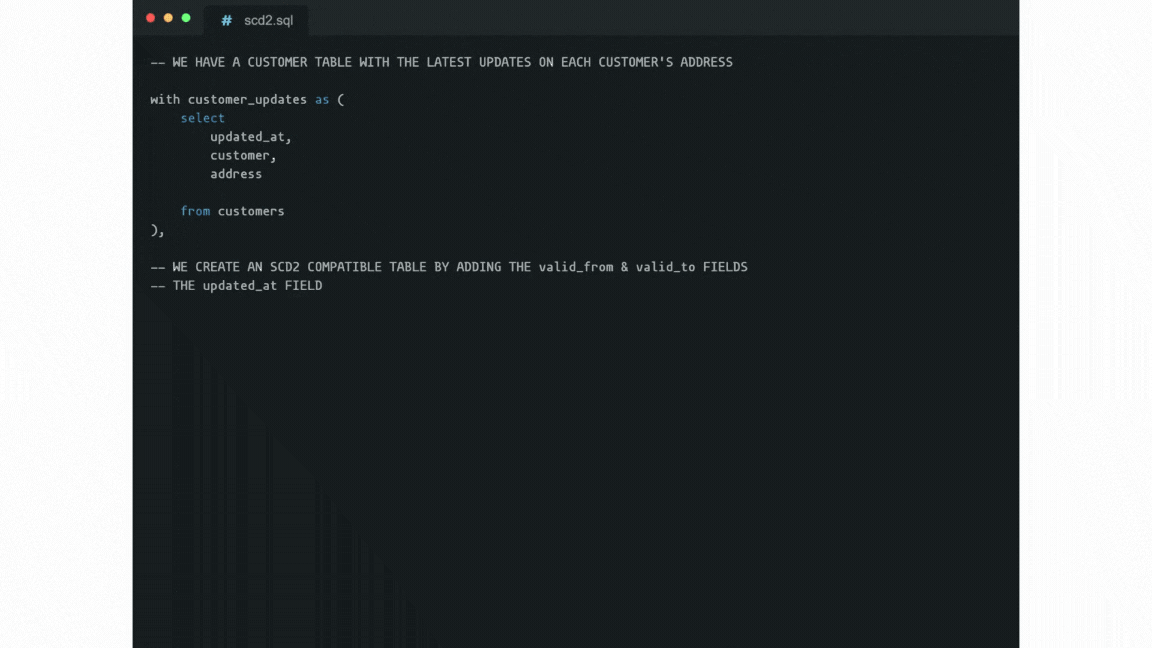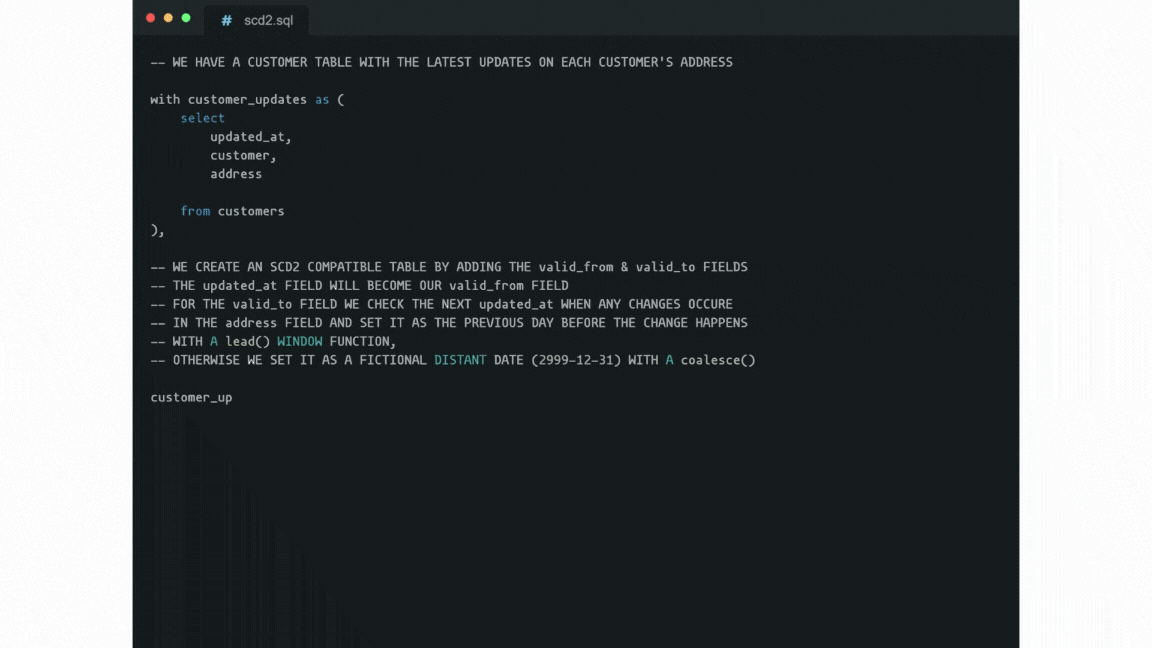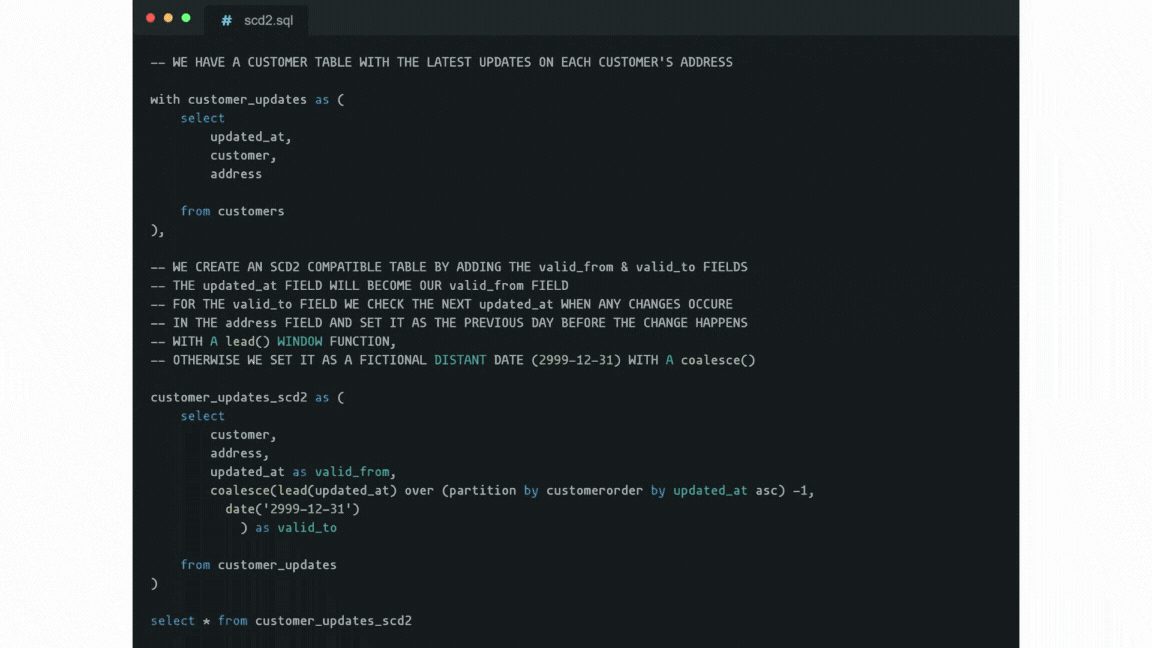
Fetching the value that was valid at a given date then needs a WHERE condition with a BETWEEN clause. This aligns naturally with fact records having a “happened at” timestamp.
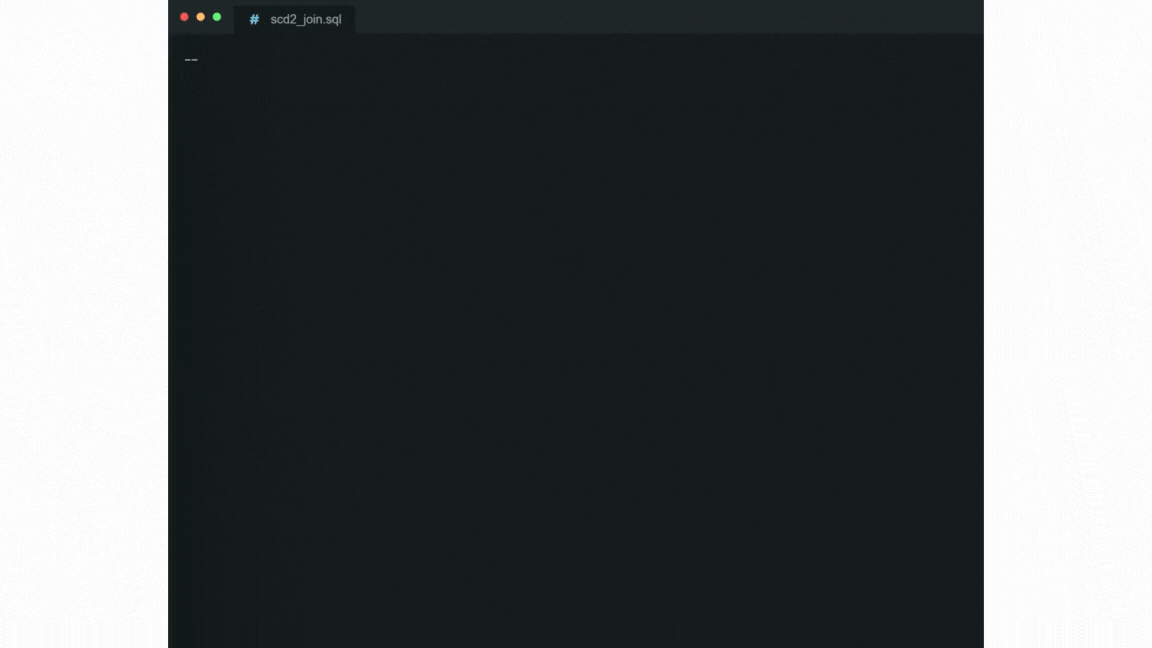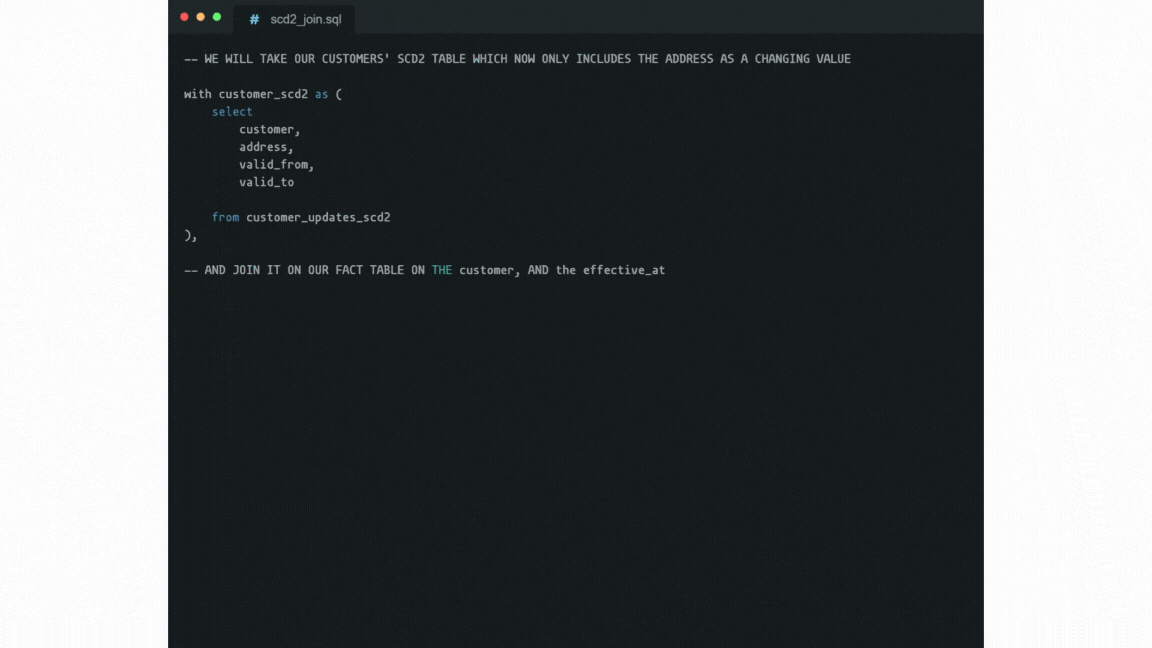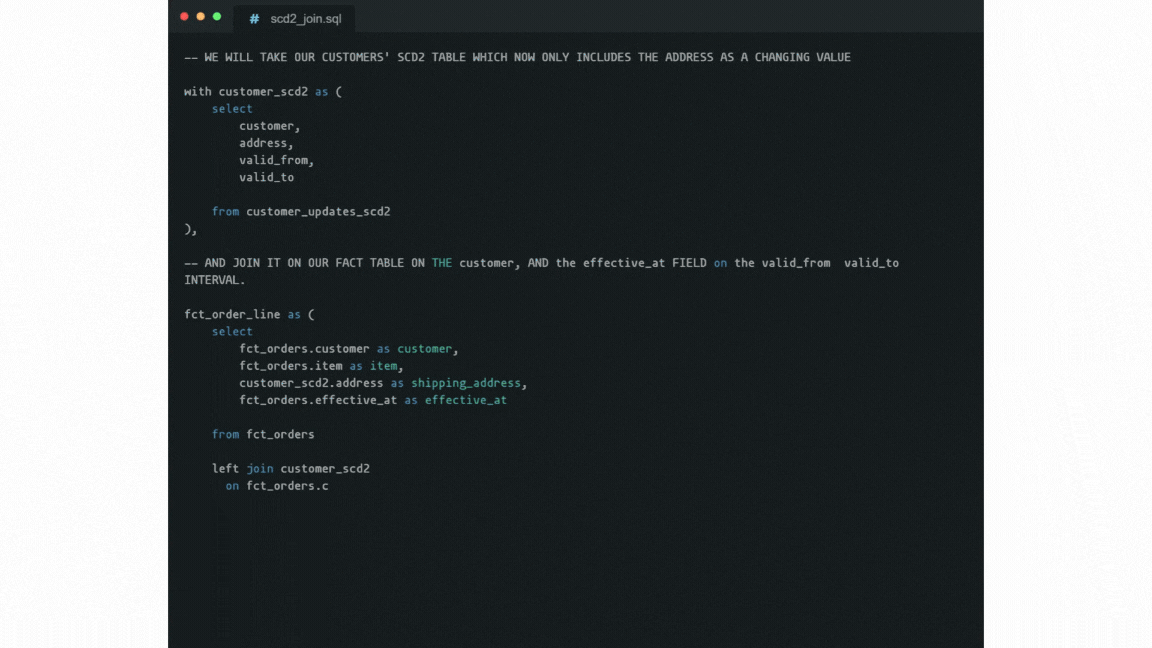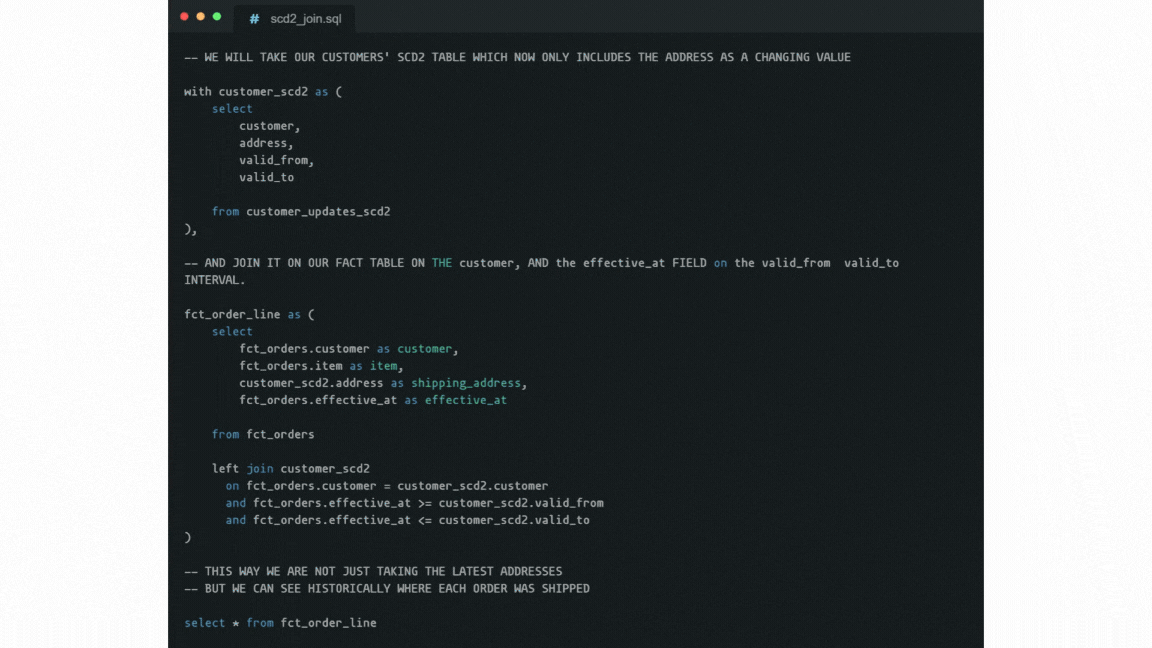
This approach can often substantially compress the space needed to store dimensions.
It, however, requires updating an existing record – and that’s something modern analytical tools don’t really like.
On top of that, each load requires that the selected attributes in our current record version in the data warehouse get compared to the freshly loaded ones. This might be quite some work both on the system’s and the developers’ side.
When Facts Don’t “Happen”
It is worth noting that in the matter of time, some of the fact entities tend to behave as dimensions. These are the facts that represent some kind of state. (While the previously described business transactions represent a “flow”.)
In this case, changes in a record may hold unignorable business meaning. Therefore, it’s essential to properly capture what is going on as time goes by because for most analytic purposes the current state won’t hold the required business meanings.
One of the easiest-to-grasp examples of this is inventory levels. For many use cases, one is interested in the inventory level at a particular point in time, regardless of the transactions that happened before.
The Good Practice, The Bad Practice, and the Actual Inventory Level
While it is (theoretically) possible to construct the inventory level at any given point in time by aggregating all transactions before that point, it is most often rather impractical. (There are too many events, and, in reality, inventory levels tend to deviate from the sum of the preceding transactions.)
Therefore, they are handled largely the same way as dimensions – with very similar tradeoffs. One notable difference however, is that stateful facts typically change much more frequently than dimension attributes, and therefore the compression that the validity range provides is often much less.
“A butterfly can flap its wings…”
There are cases when something happens that “changes the past”. These are the so-called “late-arriving events”.
A “late-arriving event” is some record that, most often for technical reasons, arrives after we have loaded the data for that time window. (Imagine for example telemetry data from mobile devices. It may happen that a device has no connectivity for a while and only sends data several days later.)
A rule-based exception we have come across was tax form corrections. In the given jurisdiction taxpayers were allowed to resubmit their tax forms even years after the deadline for the given period to correct mistakes.
What is “proper” history in these cases and how can we handle it?
Sometimes one can brush it off. A noncritical late-arriving telemetry data used for statistical purposes can, perhaps, be dropped, as if it had never arrived at all. And it is so much simpler than anything else that there has to be a very compelling business case to decide otherwise.
Such as with re-submitted tax forms. Obviously, we can not simply drop them.
It turns out that there are two questions we need to answer: what the current value is and what the value was on some past date. In a way it is a very similar situation that we handled for dimensions with validity ranges and with stateful facts; and, indeed, the solution is similar, but the consequences are quite drastic.
Points in time… points in time everywhere!
We have to realize that there are at least two (or maybe even three) different time references for an event:
- “Event time”: When the event happens in reality. This is (or at least should be) recorded in the event.
- “Effective date”: When the data warehouse learns about the event. It is always later than when it happens; and the how much later and if that’s material are questions to consider.
- “Reference time”: In addition, facts sometimes inherently have a time reference of their values, such as a tax or forecast period, a due date, etc.
In the previous chapters, we covered “event time”. “Reference time” is only an issue here because it is yet another date field users have to handle; otherwise it doesn’t interfere with the logic.
Play it Again – Unless you lost your note
However, in order to be able to properly handle “changing past”, we have to introduce an “effective date”, which is to be filled automatically when loading the data.
It is possible (and often practical) to mark the most up-to-date record as well – but it comes with the same performance tradeoffs we discussed above (and, since fact tables tend to be huge, scanning them to find/update earlier versions is often not very efficient).
Now we can ask what the report looked like before the late event arrived and generate it for the most current data.
(What did the tax form for a given year look like when the fine was levied, when did it change, and what does it look like now?)
From this point on, however, querying becomes more complicated, because for all queries one has to define the effective date as well. This is difficult for the people querying the database and also typically difficult for the engines to optimize for.
When, What, Who, but mostly, Why?
But that’s peanuts to handling dimensions, especially when stored with validity ranges.
If a dimension can change retrospectively, it will also have to have an effective date (range) – in addition to its validity date range. So, there has to be a record for every (overlapping) validity range and effective date range combination, which the loader needs to generate. But the killer piece is that the effective date range has to also be taken into account when joining the dimensions to facts…
Theoretically, it’s not that hard. In practice, though, it is. We have built large systems with these constraints, and I can tell you that neither the developers nor your users want it. It’s brutal.
For nearly all use cases we had to generate a lot more simplified versions of the tables for people to be able to work at all. Avoid this pattern if there is any way you can.
… and we have still not finished yet
There is a somewhat separate aspect of validity, that’s not in the data, and it’s very difficult to handle there. Namely that of the code that generated it.
Imagine, you have a set of key performance indicators (KPIs), going back for many years, stored in a table to which you append the KPI values each week.
Let’s be permissive and suppose you have all the base data, properly timestamped and all, since the beginning of time. Can you tell how the KPIs for a given week 4 years ago were calculated? Could you recalculate them, should the table get lost?
Can you even tell what data (tables, records) were involved in those calculations?
In most real-world scenarios, the answer is: no. To reproduce old calculations we need all the related historical data that have been used in the given time. But, to make things even more complicated you must also obtain the exact codes that were used. And it’s still not the end of the story. The data and code must be deployed without any errors and return the same results they used to do. Honestly, in practice, this isn’t likely to work.
In a nutshell, to be able to handle late-arriving or reproduce legacy analytics you must prepare for this occasion the time you actually manage the data as it is, and leave some instructions to your future self.
Temporal Data Validity Management Must Be a Permanent Solution
In many business settings, the mentioned repeatability of the recalculation of old values [1] isn’t a really important question, and we should not build the systems to meet these requirements.
However, when these are serious considerations (e.g. for regulatory reporting or security audits), it takes a ton of architecture design and implementation effort, in addition to the operation rigor to meet them.
Diving deeper would stretch the boundaries of this already too-long post, so let’s keep that for another one.
Conclusion
Temporal data validity management and well-described time are essential components of data warehouses. They are very helpful in making use of the data but also pose challenges. These challenges mostly stem from how time “works” in the real world, and how our processes align with them.
We need to adapt our solutions to this reality. There are known, tried and tested ways to manage temporal data validity. Which one is the most applicable to your case is an important design decision.
Many business data marts can get away with timestamped facts and no dimension history. They are quick to develop and simple to use, which most often trump some sophistication.
On the other end of the spectrum, there are a few systems that genuinely require bitemporal validity management and beyond. They are complex beasts that take a lot of mental effort both on the developers’ and on the users’ ends.
So, if there is one piece of advice you take from me, then be it “make it only as sophisticated as you absolutely must and not a bit more”.


