


Here's the deal: Databricks wants to be the go-to place for every flavor of data nerd out there. And trust me, there are a lot of us:
- You've got your data analysts who just want their SQL and pretty charts.
- Then there's the ML buff, tinkering on model pipelines and praying for a clearer data lake.
- Plus the shiny new Generative AI stuff popping up everywhere.
- And of course, the data engineers and app devs who need to poke around in the backend.
Managing all these needs is a governance challenge.
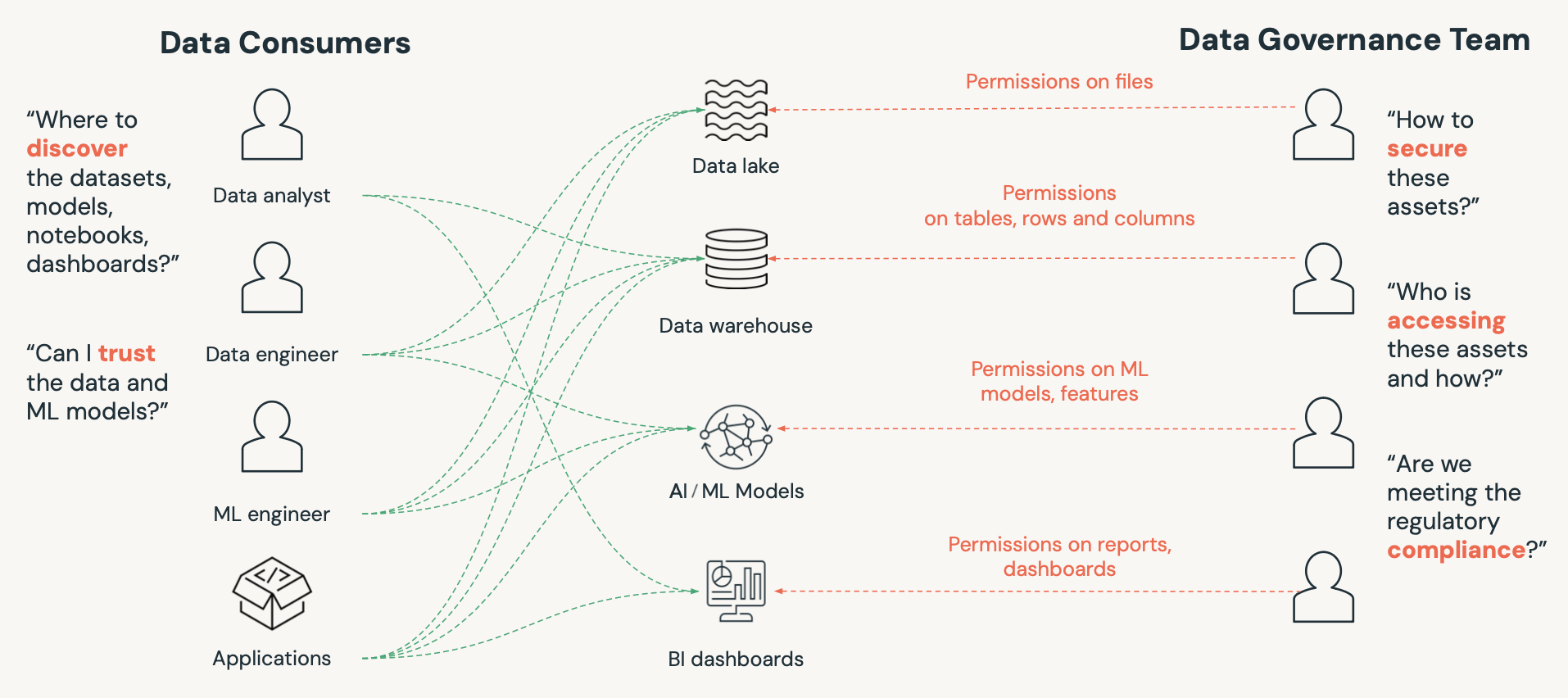
Enter new era of data governance with Unity Catalog, Databricks' solution to these challenges.
Since its announcement as open-source at the Data+AI Summit 2024, Unity Catalog has repositioned itself as a cornerstone of data governance not only in the Databricks ecosystem, but for the whole world to use.
At its core, Unity Catalog serves as a unified data governance layer. It consolidates previously isolated metastores, centralizing both metadata and access management into a single platform.
This single metastore can be used by all workspaces in the given cloud region and tenant, which means that there is no need for rights and roles synchronizations. Unity Catalog can be controlled by both command scripts (ANSI SQL) or via an intuitive Graphical User Interface.
There are a lot of things to consider when taking such a step and Unity Catalog covers all essential functionality and also enables the use of various additional features. As Unity Catalog is now open source, data stored and governed by it is portable so vendor lock-in is not a possibility any more. Should someone decide to migrate to a different platform for whatever reason, the open source Unity Catalog is there to enable this migration without additional cost.
This also means that other platforms may end up natively supporting UC further enhancing interoperability.
This article discusses the version built into Databricks. Some features may or may not be available, but Databricks promised to gradually remove dependency on proprietary code, so it is expected that the OSS version will eventually catch up and shall become the norm.
Unity Catalog has been in development for quite some time now, and it has matured to become the centerpiece of all data governance in Databricks. Besides the typical objects that one would expect from a piece of software like this to control (such as data objects like schemas, tables, views, etc.), Unity Catalog also handles both ML and AI models, enables a bunch of additional features and helps with discovering and understanding the flow of data.
Key features of Unity Catalog
1. Data separation
Unity Catalog enhances data security through logical separation without sacrificing centralized management.
Separation of data is key. Everyone should only have access to data that is meant to be used by them. As Unity Catalog aims to centralize management and governance of all workspaces of an organization, this might seem counterintuitive, but Unity Catalog introduces a new layer on top of databases called catalogs.
The role of the catalog is to organize databases into logical units. Each workspace can be assigned to one or more catalogs. A per user access control to databases and tables enables finer grain control over who can see and use what on the platform. Even though data is managed centrally in this scheme, with the introduction of the catalog layer above databases, the same level of data separation is achievable as long as the underlying data storage solutions have their permissions set up according to the guidelines of the matter.
Unity Catalog replaces the Hive metastore entirely With Unity Catalog enabled on a workspace, direct access to the underlying storage has to be disabled for all users. This way, only UC and designated members of the users are allowed to look under the hood and access the raw data of the tables. This makes sure that there is no possibility for anyone to access data that they were never supposed to access.
Unity Catalog goes even further with its security scheme with views. A complete security layer can be defined on top of the data tables and users may only need access to these views and not the tables themselves. Accessing data through these views with whatever masking and filtering will work normally without the user being granted access to the underlying tables, making sure that everyone only has access to data they are allowed to access.
2. Row and column level access control
Fine-grained access control is a hallmark of Unity Catalog, allowing for precise data governance at the row and column level.
To further refine access to data Unity Catalog introduces mechanisms to implement both row and column level access controls over tables. This makes it possible for certain groups of people to only see rows in a table that their group membership permits them to, or to only see unmasked data in columns that are accessible to them. This control is implemented on a data definition level and can be applied to both tables and views.
A possible architecture of workspaces, catalogs and databases may look something like this:
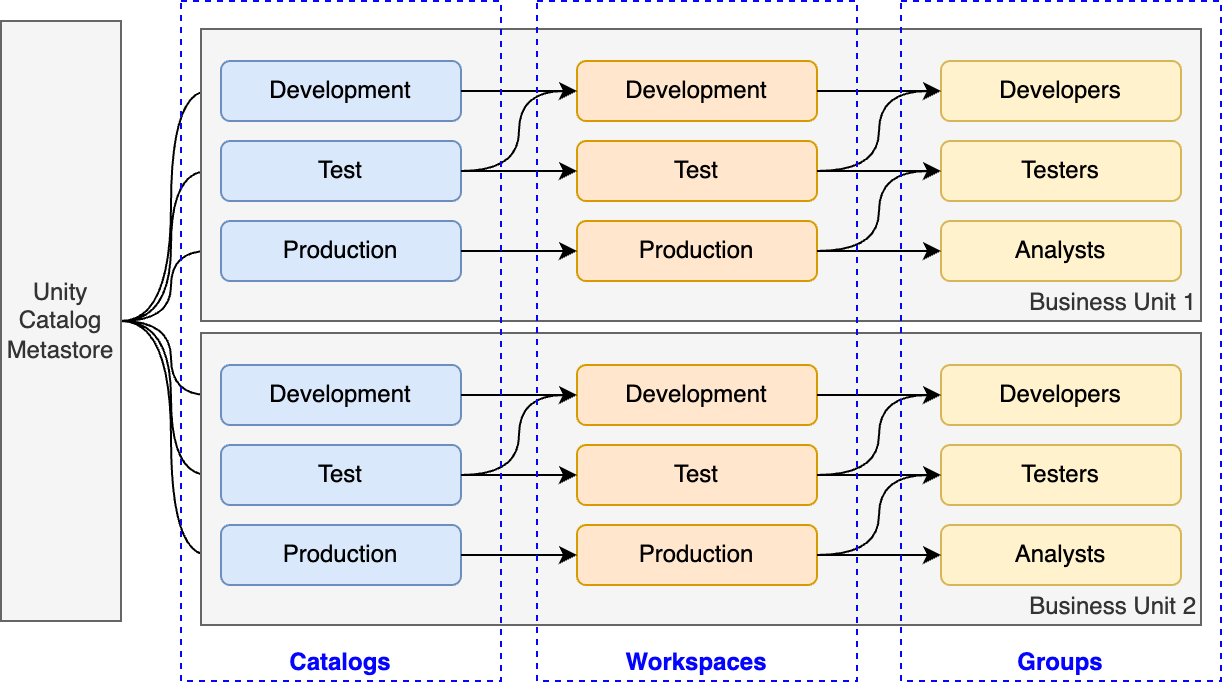
In this example the data platform is segmented by both the line of business and the software development life cycle. This has the benefit of separating different branches of the company to their own workspaces and these workspaces can be granted their own specific catalog with all the data they need. Since the number of catalogs a workspace can have access to is not limited to one, common catalogs may be shared across multiple workspaces sustaining the single source of truth paradigm without data duplication.
Based on this same principle, some specialist workspaces may even have access to most if not all of the data the organization has.
One caveat of this approach is that while workspaces themselves don’t induce any additional costs, the compute resources cannot be shared among them, so if a workspace has otherwise wasted free resources available, other workspaces are not able to take advantage of them. This however can easily be overcome through appropriately sized compute clusters with both auto-scaling and auto-termination enabled.
3. Data access auditing and data lineage
Unity Catalog provides comprehensive auditing and lineage tracking, crucial for regulatory compliance and data understanding.
With the increasing scrutiny of regulations, a modern data platform needs to be able to provide information about access to data. Unity Catalog is fully capable of doing this, as all data events are captured in a detailed event log that describes how data was created, modified and accessed.
Furthermore, Unity Catalog has built in data lineage capabilities that enable the platform to track how data is being used, how it flows from its source to its destination. Combining these two features provides a rather powerful tool that helps to understand how data is being used and by whom.
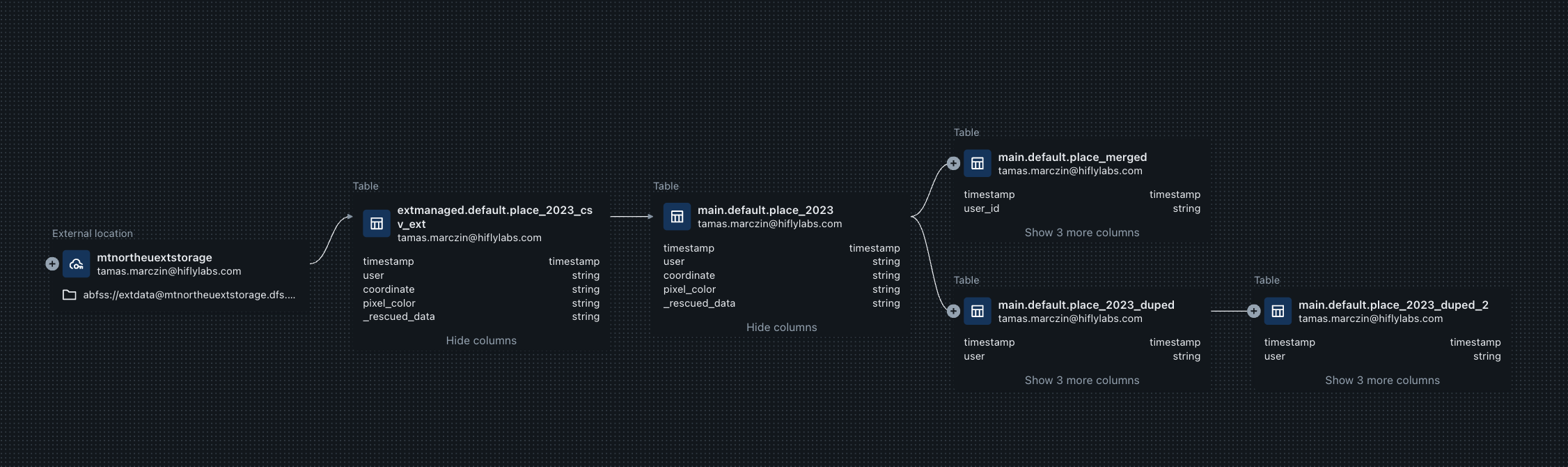
4. Data discovery
Efficient data discovery is facilitated through Unity Catalog's built-in search capabilities and semantic tagging system.
Data is only as useful as the value an organization gets from it and Databricks realizes this too. For this very reason with Unity Catalog they take a step towards a more comprehensive view of the data that is stored in the platform. UC comes with built in search capabilities that allow easy data discovery.
Since object names and the occasional comments on them are not usually adequate to fully describe meaning behind them, Databricks also introduced the discovery tags feature, which provides a semantic layer for the lakehouse. Tags can be added to columns, tables, schemas or catalog objects containing business terms without an external tool. This, combined with data lineage features of the platform provide data practitioners with a powerful set of tools that help in their day-to-day tasks without leaving the platform.
5. Integration
While powerful on its own, Unity Catalog truly shines when integrated with external data governance tools like Microsoft Purview.
Unity Catalog is powerful when it comes to data governance in itself as well, but it can be even more powerful when integrated with an external data governance tool such as Microsoft Purview. Many other tools also offer solutions to integrate with Unity Catalog. By integrating a Unity Catalog enabled workspace to an external data governance tool, users get the best of both worlds. Tools that are well integrated with Unity Catalog will gather all the available information from UC and will also have all their own capabilities at the disposal of the user. With such a setup, a complete, company wide data governance solution can be implemented encompassing not only the data within Databricks, but also integrating information from all sorts of other data sources such as source systems and other databases, and this also enables among other things the use of comprehensive data catalogs and business glossaries.
6. Delta Sharing
Delta Sharing breaks down data silos, enabling secure, live data sharing across platforms and organizations, fostering data collaboration without compromising security.
In certain situations it is necessary to share some portion of the data with other data platforms or other organizations altogether. Databricks introduced a feature called Delta Sharing that helps in situations like this. Databricks Delta Sharing enables the secure sharing of live data from your Databricks lakehouse to any computing platform, regardless of the recipient's system. This eliminates the requirement for recipients to be using Databricks services or even the same cloud platform to access the data. Providers can share data without replication, while recipients can benefit from always having the latest version and using their preferred tools for analysis. Delta Sharing even supports Microsoft Excel.
This open protocol is also the beating heart of the Databricks Marketplace, where it is possible to obtain free or paid data, tools and many other things.
7. Lakehouse Federation
Lakehouse Federation addresses the common challenge of accessing data outside the lakehouse, providing a unified access point for external data sources without the need for immediate ingestion.
At a certain point in an organization’s life it becomes important to access data residing outside the lakehouse. Databricks offers a new feature to achieve this: Lakehouse Federation. This service allows Databricks to connect and query external databases and data sources using Unity Catalog. This method of connection is done through standard APIs and the main role of this tool is for basic data discovery and querying, it is at the time of writing not a replacement for various extract and load solutions, but allows data practitioners to gain access to and use data that are not (yet) integrated into their lakehouse environment. It basically provides a single point of secure access to data living outside of the lakehouse without implementing ingestion.
Using such a solution has many advantages that help accelerating and simplifying day to day activities for both end users and administrators. With the help of Lakehouse Federation and the Unity Catalog, data sources integrated this way all fall under a unified permission control. Access to these data sources are managed within Unity Catalog, the same way data access is managed within Databricks itself. Lakehouse Federation optimizes queries with intelligent pushdown features. This means that no unnecessary data movement is introduced into the system. Additionally, should a piece of data be needed frequently, accelerated performance is easy to achieve with materialized views.
8. ML and AI features
Unity Catalog is not just for data objects.
Machine learning and Generative AI models can also be registered for all kinds of governance tasks, including various monitoring and serving capabilities. Additionally, Databricks announced just recently that tools for AI agents will also be able to be registered into Unity Catalog, thus further enhancing cooperation between various teams working on different tools and models.
9. Lakehouse Monitoring
In this day and age, data quality is a cornerstone of all AI, BI and ML workloads. Built with misleading data, no application can live up to its task and making sure data is correct is not as straightforward as it might seem at first glance. With Lakehouse Monitoring, Unity Catalog automates some of these common tasks by providing an easy to use framework that can be enabled on any delta table, including inference tables of ML models. Lakehouse Monitoring automatically handles monitoring characteristics of the tables, such as data integrity, statistical distribution, model performance or even drift.
Status of these metrics can be displayed using dashboards and since Unity Catalog precisely knows when changes happen to tables, the updates are automatic and only happen when needed. The metrics are also accessible in their respective tables for pragmatic analysis.
Limitations of Unity Catalog
While Unity Catalog is versatile, it does have some current limitations. However, these are soft limits that Databricks may adjust as the product evolves.
As with many things in life, Unity Catalog also has its limitations. While the system is as versatile as possible, some soft limitations have been set. These limitations are valid at the time of writing, but it is important to note that Databricks may raise or lift them any time in the future. With special exceptions, these limitations can even be raised right now.
As of now there can only exist a single Metastore for each Cloud Region for the Databricks Account. This means that all Unity Catalog enabled workspaces within a region must use the same Metastore. Some of the capabilities of the Metastores also have limits imposed on them, such as the maximum number of tables allowed in a Metastore, but as mentioned above, these limitations are not hard limits and are prone to increase without notice. The best approach is to keep an eye out for changes in the official documentation.
Compatibility across ecosystem
Unity Catalog maintains compatibility with Databricks' core data handling capabilities, supporting both managed and external tables across various file formats.
The system still supports managed tables, in which case both the delta format data files and the metadata are directly managed by UC. External tables are also available. These tables are only managed on metadata level and their data files can either be delta, CSV, JSON, avro, parquet, ORC, or text. At the time of writing, all regions are supported in Azure, AWS and GCP and a migration path for already existing Hive Metastore based workspaces and organizations is available.
As of time of writing, many exciting features such as Metrics have also been announced. We will explore these features when they become available for wider use and report back in a followup post.
Pre-existing workspaces are not left behind either. It is completely possible to upgrade a Hive metastore based workspace to a Unity Catalog enabled workspace. This, however, is not a two-click, trivial task and involves some planning and manual work. Stay tuned for an upcoming post where we'll delve into the upgrade process too!
All in all, Unity Catalog streamlines data governance on Databricks and beyond, offering centralized management, enhanced security, and improved discovery. As an open-source solution, it empowers organizations to unlock their data's full potential securely and efficiently—making it a highly recommendable solution for centralized data governance, as well as enterprise AI governance and security.
Curious to see use cases? Check our Databricks application development brief with two AI applications in production built entirely on Databricks and governed under Unity Catalog (free resource, no forms).


