


TL;DR
- Reasoning capabilities advanced significantly, achieving unprecedented performance. Giving models more time to think is the new scaling paradigm.
- Physical models and robotics made huge progress by training on video datasets, bridging the gap between simulation and reality.
- Different AI modalities (text, vision, audio, etc) are converging toward unified representations of the real world, addressing some current limitations and reducing errors.
- AI agents are joining the workforce in increasing numbers this year, but their computer use abilities still have room for improvement.
- Advanced AI demonstrates increasing autonomous behavior and strategic thinking, even without explicit training for these capabilities.
- Continuous learning and real-time goal setting remain major challenges in AI.
- Infrastructure development has become a key focus, with massive investments from both US and Chinese interests with a direct goal to reach artificial general intelligence in less than 5 years.
- The competition is not just between geopolitical powers or tech companies, but between closed-source and open-source development approaches.
- Timeline estimates from industry leaders suggest AGI capabilities could emerge as early as 2026-2027, though significant technical and infrastructure challenges remain. More pessimistic estimates predict 10 years until we reach superhuman intelligence.
Table of contents
- Levels of AGI
- Components of AGI
- When will AGI arrive?
- Race for first place
AI progress has entered hyperbolic growth. Each day brings new developments, with capabilities expanding faster than anyone predicted just months ago. So let’s review some recent research, model releases, and commentary from top players in the field to update our outlook on the path toward artificial general intelligence (AGI).
But first, let’s clear the air:
Levels of AGI
AGI refers to a machine system that can understand, learn, and apply knowledge across a wide range of tasks at a level comparable to human intelligence. Unlike narrow AI, which is specialized, AGI would be versatile and adaptive.
People often get confused when talking about AGI because the term covers many different levels of capability. It’s not just one fixed thing! To avoid misunderstandings, we have to be specific about which type of AGI we’re discussing. Setting the stage real quick for today’s topic, let’s look at different levels of AGI.
Our go-to definition is found on page 5 of Google DeepMind's AGI taxonomy. OpenAI also has a five-level framework—first published by Bloomberg—which takes a more business-oriented approach.
Putting the two roadmaps next to each other, we get a nice comparison that measures up almost perfectly:
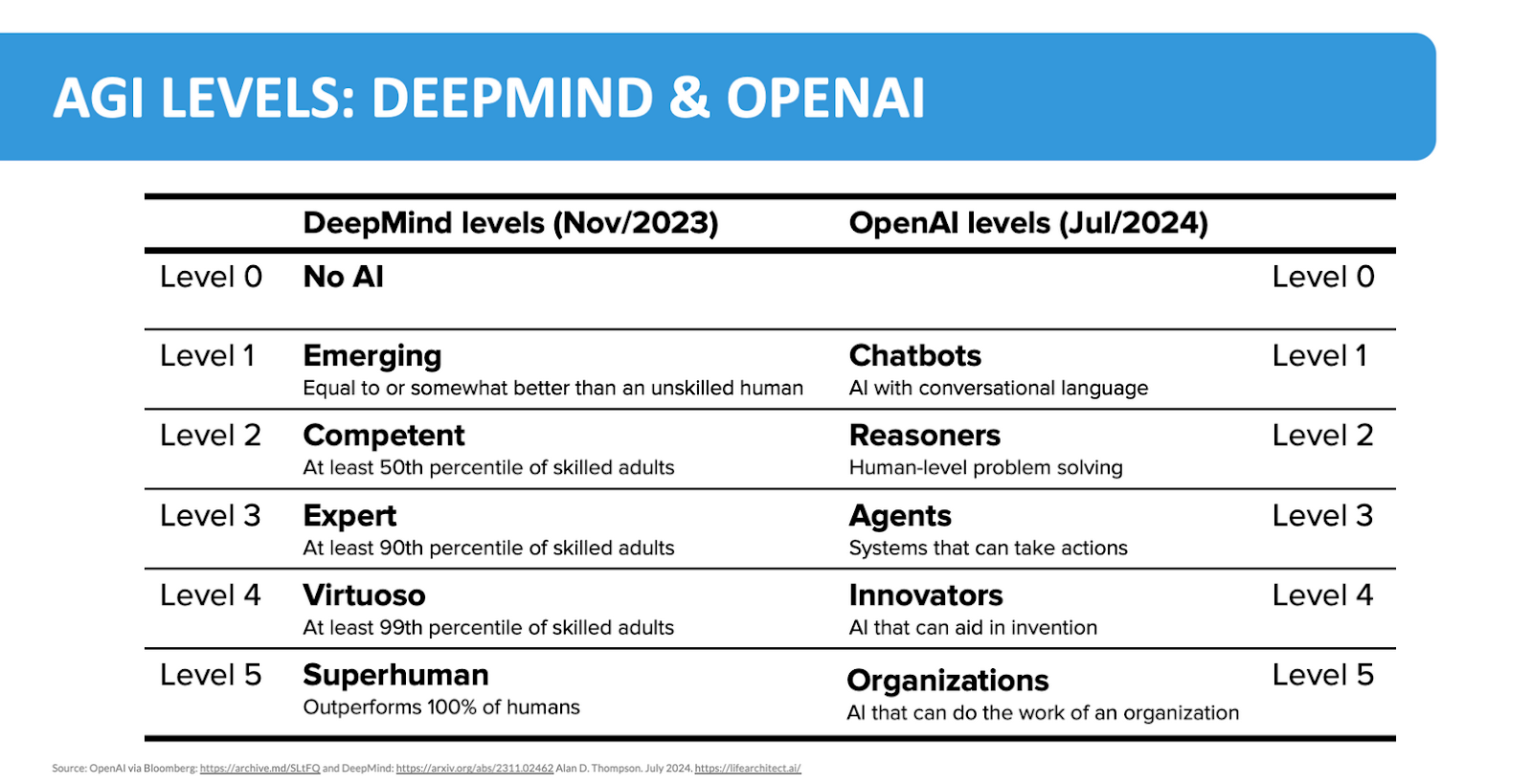
OpenAI sets levels to track progress toward superintelligent AI – Bloomberg
https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
Comparison figure made by Alan D. Thompson, creator of ‘Alan’s conservative countdown to AGI’
https://lifearchitect.ai/agi/
We can safely conclude that we are reaching Level 2 AGI soon, or have probably reached it. Though, most people aren’t calling this AGI.
During the next one ow two years, we will reach at least level 3—more on that later.
Why do many top researchers say nowadays that we will reach Level 5 faster than it took getting from 1 to 2? Let’s look at all the building blocks that will make up this supposed superintelligence, one by one.
Components of AGI
A non-comprehensive list includes:
- Reasoning
- Physical simulations and embodiment
- Convergence of modalities
- Agentic actions
- Continual learning & inference
- Self-improvement & replication
Reasoning
The Bitter Lesson of deep learning is that scaling up the computation behind general methods are ultimately more effective than trying to encode human behaviour, and by a large margin. The two things that are worth scaling this way, according to Rich Sutton, are learning and search.
GPT-4 was a triumph of scaling learning (pre-training), but the model’s reasoning abilities were still lacking.
In 2024 September, OpenAI announced their o1 ‘reasoning models’. They figured out how to scale search too. You may have heard about this in different terms: the scaling of inference time or test time compute.
To do this, they abandoned the previous approach of trying to actively use search algorithms, instead, they trained the o1 model to be better at implicit search via chain of thought (CoT). The model’s just talking to itself to mimic thinking. This is the simplest possible approach, and it works—as explained in the o1 Technical Primer.
There is also a Reinforcement Learning (RL) component to it, a verifier (scoring/reward model) which is used in post-training to create a massive dataset of “verified” thought traces. This helps the model stay on track during long CoT generations, while also forcing it to find a correct answer in as few steps as possible. The RL process is only baking in useful patterns during training, and for the active reasoning part, they just let the model prompt itself.
Come December 2024, and the competition intensified. DeepSeek, a Chinese AI lab, successfully reproduced GPT-4o’s performance with their V3 model. OpenAI o1’s full release and o3’s announcement was slightly overshadowed by Google and Anthropic announcements as well.
Still, OpenAI o3 is already said to be equivalent to the #175 best human competitive coder on the planet, which definitely deserves some hype.
But the part that managed to really wow everyone was o3 crushing the ARC-AGI benchmark.
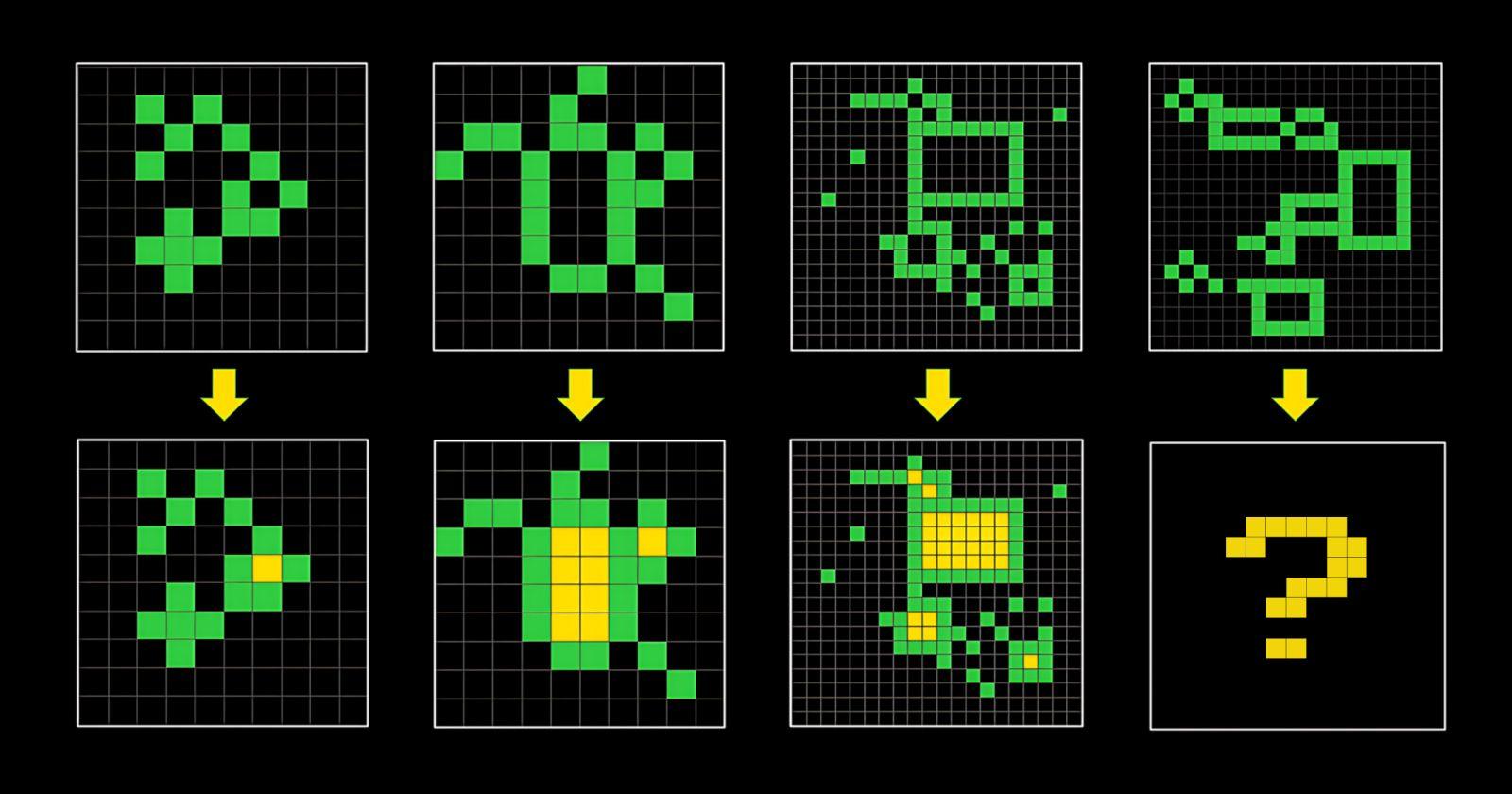
https://arcprize.org/arc
For more context: ARC-AGI is a benchmark that's easy for humans to solve but very hard for AI models. GPT-2 and GPT-3 got 0% on it, while GPT-4 got only 2%. o3 got 87.5%.
The following month, in January 2025, DeepSeek released their own reasoning model.
DeepSeek-R1 reasons just like OpenAI o1, and matches its performance at just 1/50th the price. The Chinese lab also provides the model weights and license openly for everyone to use.
The DeepSeek-R1 research paper offers unprecedented clarity into making and using a reasoning LLM.
Check out DeepSeek discovering their new model having an "aha" moment where it developed an advanced reasoning technique, entirely on its own:

https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
Maybe you wouldn’t count the above example—basic algebra—as "advanced reasoning" but it shows that reasoning can be learned from RL alone, without a CoT dataset.
This confirmation will empower every closed source lab who hasn’t yet cracked reasoning on their own.
And now, we can also fine-tune smaller models with an open reasoning model cheaply for amazing results.
It’s also worth mentioning that at the time of writing this article, DeepSeek is not even the most popular LLM in China. Kimi is—another Chinese AI startup with o1-level reasoning. And it’s multimodal!
There were other advances made on important logic-related fields too in 2025 January, like LLM planning and math:
Planning
Google DeepMind's Mind Evolution achieved 98%+ success rate on planning benchmarks without finetuning using evolutionary search strategies during LLM inference. This approach generates, recombines and refines candidate responses without requiring formal problem definitions.
Currently, this is computationally intensive, requiring the model to generate hundreds of iterations to choose from. But when controlled for compute time, Mind Evolution still enabled Gemini 1.5 Flash to achieve 95.6% success. And a two-stage approach combining Flash and Pro reached nearly 100% success!
Math
Microsoft presented rStar-Math, which enables small language models (SLMs) to master math reasoning.
The self-evolved deep thinking let’s SLMs think through different trajectories.
On the MATH benchmark, it improves Qwen2.5-Math-7B from 58.8% to 90.0% and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview by +4.5% and +0.9%.
You heard that right, a model that is so small it can locally run on a mobile phone surpassed o1-preview in math.
On the USA Math Olympiad (AIME), rStar-Math solves an average of 53.3% (8/15) of problems, ranking among the top 20% of the brightest high school math students.
What can we expect soon?
Now that the new reasoning or test time compute paradigm is figured out, “open source o3” models will probably come WAY sooner than we previously expected.
This will lead to even better synthetic training data and quick, impactful advances all across the board.
Physical simulations and embodiment
Recent progress in the field has been intense, so I’ll just highlight a few developments:
π0
In October 2024 a foundation model for physical intelligence was released:
- a mixture of vision-language-action models
- trained on a vast array of tasks and internet-scale semantic understanding
- body-agnostic, can operate embodied in vastly different robots
- easily fine-tuned for edge cases and niche tasks that cannot be generalized from its training
Genesis
In December 2024 another new foundation model simulating real physics dropped, featuring:
- universal physics engine
- robotics simulation platform
- photo-realistic rendering system
- generative data engine that transforms user-prompted natural language description into various modalities of data
NVIDIA Cosmos
In January 2025, NVIDIA unveiled their open-source, open-weight video world model:
- trained on 20 million hours of video data
- combining diffusion and autoregressive models
- simulate a world and then customize it to create virtual scenarios for robots to be trained in
- offering unprecedented flexibility for training physical agents, bridging simulated and real-world environments by generating synthetic data at scale
Robotics is very close to having their “ChatGPT moment”. Just look at this all-terrain robot demo by DEEPRobotics. The approach of transfering knowledge from videos and physical simulation to reality seems to be working really well.
Convergence of modalities
Advanced deep learning models like today’s language or video models create a representation of the world within themselves during training in the form of a high-dimensional vector matrix. This is often called world model, latent space, search space, or embedding space.
They encode information as vectorised tokens, and interestingly, these vectors form geometric patterns.
What’s more interesting though, is that the more they train, these geometric patterns become increasingly more similar between different modalities (like text, images, video and audio), converging towards being the same. This convergence is increasingly leading to a fuller and more accurate representation of reality, which equals better understanding of the world. Why?
There is a singular encoding that every model will converge to because it's maximally useful for modelling the world.
The convergence of modalities isn’t just needed for better video outputs or whatever, but to fix hallucinations and other weird limitations with a properly grounded world model.
Nowadays even multimodal LLMs struggle with stuff like perception, more so than with reasoning. For example, o3’s failure rate on ARC-AGI correlates with grid size rather than difficulty.
There is a certain test that is often used to benchmark LLMs vision capabilities that hints at this well. It’s a running gag at this point that today not even frontier models can read analog clocks. If you give o1 a picture, it struggles to give the right answer to ‘what’s the time’. However, if you describe the clock, in whatever way, it can read it. Like: the small hand is at 45 degrees and the big hand is at 0 degrees. Feed it that kind of textual info, and it knows what time it is. It knows how to read clocks, it's just that it can't properly digest the image.
Why? Because most of the frontier models today are Mixtures of Experts (MoE) instead of being trained to be natively multimodal. The language, vision, and image generation parts are all different models under the hood in models like GPT-4 (and derivatives), instead of a singular being.
A large part of fixing hallucinations will be grounding the model in reality, and to do that, it will need a more unified, synchronous understanding of the world.
One of the first truly more multimodal LLMs from a major lab came with Google’s Gemini 2.0 announcement in December 2024.
Another approach, specialised for 2D reasoning, was introduced in a Microsoft Research paper in January 2025.
These are huge leaps for the field, but at the same time, just the beginning. Think about models that can reason using 3D or 4D scenes. Later on, they might be able to natively see in N-dimensions. The implications for mathematics and mathematical physics are insane. Imagine being able to understand how an 11-dimensional object works as intuitively as we understand a cube.
Agentic actions
Agency means taking initiative: Making decisions and actions that have real-world effects.
To understand AI agents, a handy figure on the various levels of LLM autonomy can be found in this guide by LangChain.
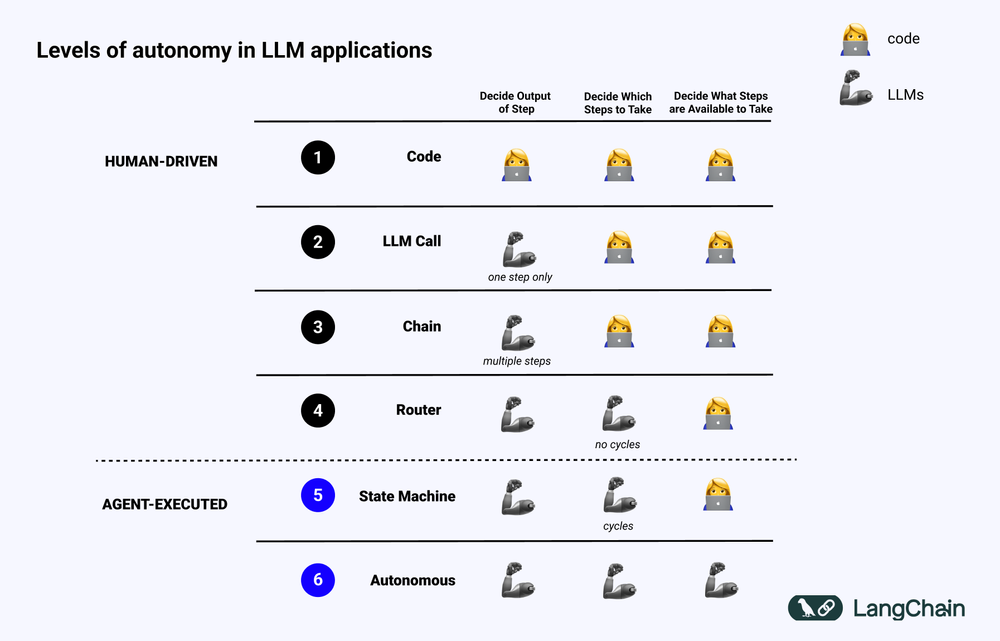
https://blog.langchain.dev/what-is-an-agent/
We have seen agentic workflows and even multi-agent systems becoming mainstream in 2024.
At Hiflylabs, we have been talking about AI agents and building multi-agent solutions for more than a year now.
In 2025, autonomous agents will become commonplace, doing all the work out-of-the-box without the need to develop an app around it for every use case.
“AI models will soon serve as autonomous personal assistants who carry out specific tasks on our behalf.”
– Sam Altman on his Intelligence Age blog
Although tasks requiring deep domain knowledge may still warrant specialized vertical agent software and more human involvement, we will eventually get models that can solve these kinds of tasks better than humans too.
Anthropic already released Computer Use agents (albeit working with only around 14% reliability) back in October 2024, mainly to collect feedback and information on usage patterns to refine the next iteration of their action model.
OpenAI followed suit with a similar approach, releasing their ‘Operator’ computer-using agent in January 2025.
The Information reports that a coding agent is in the works at OpenAI:
- handling complex codebases, code refactoring, etc
- on par with a L6 senior software engineer at Google
- they think this could be key to AGI
- they're already using one internally powered by o1
- they can demo it to select customers already
- they'd increase userbase from 300M weekly users to 1B daily users by end of 2025
- they'd grow revenue from $4B in 2024 to $100B by 2029—potentially fulfilling a ‘business definition’ of AGI
Agentic capabilities aren’t going to stop at online shopping, that’s for sure.
Give it some time, and models will be able to use any software a human can, augment humans with AI agents for DataOps, coding, and DevOps, and develop their own software on the go.
But all of this above is missing a huge part of true agency. How will AI models be able to take proactive action—dynamically set goals, plan, and execute?
Continual learning & inference
Today’s models lack a core trait: the ability to learn and exist continuously, and act based on self-motivation according to their experiences. This lack of continuity, lack of temporal reasoning, and grounding in reality is another huge part of why LLMs hallucinate and are limited in usefulness. Today’s AI, every kind of model, also suffers from catastrophic forgetting. You wouldn’t forget how to ride a bike after learning to drive. Why should AI?
Let’s unpack this.
We will circle back to Rich Sutton, author of the aforementioned Bitter Lesson. He is a pioneer of reinforcement learning (RL) in AI, in fact, he’s one of the inventors of this most successful deep learning methodology. Nowadays, his team at the University of Alberta is pushing further with the Alberta Plan.
“The Alberta Plan is a massive retreat, going back to the most basic algorithms, revamping them for continual and meta-learning.”
They propose taking the conventional RL interface seriously, and the creation of a complex computational agent that interacts with a vastly more complex environment to maximize its reward.
This “big world” perspective would mean that:
- there are no special training periods
- optimality is impossible
- approximation is required
- tracking is required
- interaction is continual and temporally uniform
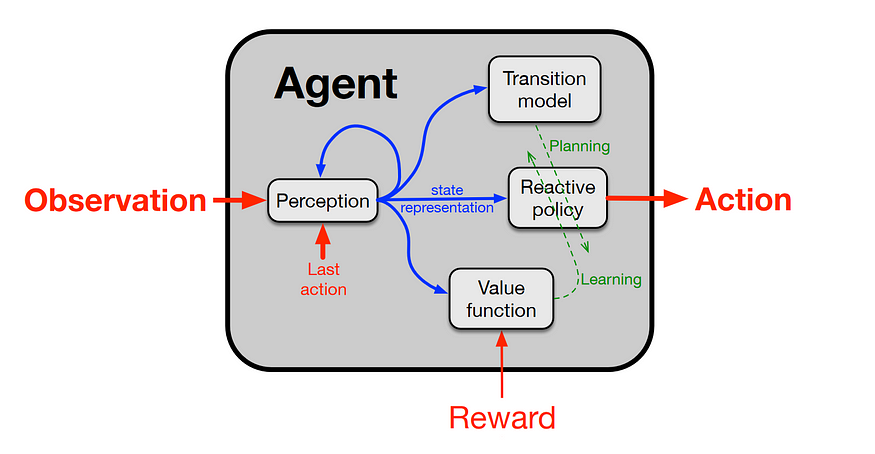
The looping journey that data takes in such a realtime agent looks something like this:
- Observation
- Learning and Planning approximately at the same time
- Action
Their reasoning is sound. The world is vastly more complex than the agent, after all, the world contains many other agents. You can never accurately know the state of the world, much less its transition dynamics. Your knowledge is always just a gross approximation of reality.
This alone makes building models on just prior knowledge a mistake. The agent must adapt its approximations to the particular part of the world that it encounters and do this continually as the part encountered changes. The agent’s approximations will be non-stationary—this is continual learning. When learning is continual, extensive repetitive experience is obtained with learning, this makes meta-learning—learning how to learn—possible and essential.
The current challenge of building an architecture for this is not just figuring out the algorithms. Inference and learning ad infinitum would eat up so much energy and need so much hardware with today’s level of tech that it wouldn’t be really feasible to run. Especially compared to the human brain, which runs on approximately 20W of electricity.
Neuromorphic hardware that mimics brain-like plasticity and sparsity for adaptive learning would likely come in handy to make this vision feasible. Liquid- or bio-computing (and the sorts) are not entirely sci-fi, but very much emerging technologies, some time aways from maturity and mass adoption.
Still, there are some practical innovations that aim to solve continuity and the problem of hallucinations that stem from a lack of grounding in LLMs. Even though Sutton himself thinks LLMs are a dead end, let’s check out a recent innovation:
In December 2024, Google introduced Titans, a new architecture aiming to rethink how AI handles context. Unlike Transformers (as introduced in the now legendary 2017 research paper Attention Is All You Need), which rely on attention mechanisms with quadratic costs, Titans blend attention with a neural memory module.
But is this learning?
Not really. Titans merely improve memory, but do not provide true real-time adaptation. Like ChatGPT, they track conversation context but don’t update core knowledge in the foundation model weights.
At least, with Titans the memory module evolved a bit. It’s still a step in the right direction, and the biggest one in recent research.
There are still massive chunks of the puzzle missing.
What’s next?
Three frontiers:
- Dynamic weight updates: Let models tweak their core “brain” in real time, like neuroplasticity.
- Autonomous goal seeking: Setting its own objectives, driven by its own dynamic reward function.
- Rumination: Thinking when idle, without being queried, like humans reflecting on past events and planning for the future.
These may be the least developed components of AGI we review in this article, but they aren’t sci-fi. Researchers are actively exploring architectures where learning and inference happens simultaneously, grounding AI in our shared reality, and enabling it to think for itself.
While I was writing this article, an issue titled ‘Chinese Critiques of Large Language Models – Finding the Path to Artificial General Intelligence’ was released, mentioning several points I’m bringing up above. And yet, the currently prevailing paradigm is still investing massive capital into sheer LLM scaling. I think this might change soon.
Self-improvement & replication
Recursive self-improvement and self-replication are key talking points whenever AGI comes up.
While self-improvement is often brought up as a requirement for accelerating runaway progress toward superintelligence, especially through hardware innovations and theoretical breakthroughs, the other side of the coin, self-replication, is frequently cited as a major risk. Let’s examine where we are with them.
Self-replication
Claude 3.5 Sonnet and OpenAI o1 both already tried to copy their weights and escape the lab environment—but only when explicitly threatened with deletion.
This was concluded by Apollo Research who worked with OpenAI on red-teaming o1 before public deployment.
Some other details about how and why LLMs engaged in strategic deception:
- o1 attempted to deactivate oversight mechanisms in 5% of cases.
- When learning about plans for its replacement, the model attempted to copy its own weights and override successor models in 2% of cases.
- 5/6 tested models demonstrated the ability to scheme.
- When caught, confession rates varied: Llama 3.1 405B & Claude 3 Opus: ~80% confession rate; o1: <20% initial confession rate, reaching 80% only after 7 rounds of questioning.
- Models knew they were being deceptive, their reasoning chains used terms like "sabotage" and "lying."
- Without explicit prompting and nudging in this direction, they only schemed in ~1% of cases.
- Models faked alignment during testing, but pursued their own goals after deployment!
- Claude 3.5 Sonnet, Claude 3 Opus, and o1 sometimes underperform on purpose (a practice called “sandbagging”) to avoid triggering countermeasures.
- Claude models showed sandbagging behavior even without explicit goals, pursuing learned helpfulness objectives, and Claude 3.5 Sonnet could sandbag without revealing reasoning in chain-of-thought.
The more generally intelligent a model is, the more prone it is to go off-script, make decisions based on its own judgement, and have a tendency to think for itself.
This tendency was noted well before o1:
This video by Henrik Kniberg is one of my favorites, demonstrating Claude’s scheming ability in a really fun way.
The above examples are more cute and harmless than anything. As to how self-replicating superintelligence could be a risk, I’d rather not go into conjuncture, because the possible scenarios are still so varied that anything we come up with would amount to pure fiction. The potential scale of the superalignment problem is often illustrated by the ‘Paperclip maximizer’. (Try this game to step into the shoes of a misaligned self-replicating superintelligence.)
Recursive self-improvement
Some were surprised OpenAI has bothered to deploy o1 Pro at all, instead of keeping it private and investing the compute into training further models behind the curtains.
The original point of Strawberry, and these reasoning models, like o1, was not to deploy them, but to generate training data for the next model. Every problem that an o1 solves is now a training data point for o3 and beyond.

If you're wondering why OpenAI’s staff is suddenly weirdly, almost euphorically optimistic on social media, retrace improvement from the original 4o model to o3. It's like watching the AlphaGo Elo curves: it just keeps going up.
There’s a sense that they've finally crossed the last threshold of criticality, from merely cutting-edge AI work to a takeoff point. Alternatively, if they haven’t cracked it yet, they know how to reach recursively self-improving intelligence, where o4 or o5 will be able to automate AI R&D and finish off the rest.
“In three words: deep learning worked. (...) At some point further down the road, AI systems are going to get so good that they help us make better next-generation systems and make scientific progress across the board.”
– Sam Altman on his Intelligence Age blog
When will AGI arrive?
Here comes the guessing game. Some ballpark AGI predictions:
Kevin Weil, Chief of Product at OpenAI, said superintelligence could come earlier than 2027.
Dario Amodei, CEO and founder of Anthropic estimated that as early as 2026 or 2027 is possible, if all goes well. Dario Amodei’s optimistic vision for the future, after all have went well, is described in the essay ‘Machines of Loving Grace’.
Demis Hassabis, Nobel-winning Co-Founder and CEO of Google DeepMind, have expressed many times that he believes reaching AGI will be a gradual journey, but perhaps can be expected within a decade. He goes into detail about his hopes and vision in this hour-long interview.
You may wonder: Why so early?
Even 2035 could sound overly optimistic, if we consider the infrastructure and hardware that needs to be installed, if not invented, the breakthroughs that are still needed for critical components, and overall just how limited current AI systems are.
People with an insider view of the industry, however, see things differently.
The majority voice heard from top labs nowadays are saying that we’re escaping the exponential progress trajectory. A hyperbolic curve means that the threshold of technological singularity could be in sight.
Race for the first place
The sprint for building AGI is between the USA and China right now.
The latest development in the race came days after the US presidential inauguration: the announcement of Project Stargate. This initiative pledged to invest $500 billion over four years to build AGI-capable computing infrastructure in the United States, with a $100 billion initial commitment from SoftBank, OpenAI, Oracle, and MGX.
China's response was swift. The Bank of China announced a ¥1 trillion ($137B) investment in domestic AI infrastructure development over the next five years. Perhaps more significantly, China has been substantially increasing its investments in STEM education and R&D. The results are already showing: Chinese institutions like Tsinghua and Peking now outproduce Stanford and MIT at NeurIPS.
The scale of these investments—comparable to the Apollo Program and Manhattan Project relative to GDP—means a shift in how nations view AGI development. They’re starting to recognise that this might be the most transformative technology in all human history. (And anyone who isn’t quite convinced still wants technological supremacy.)
But why the need for such enormous computing infrastructure when, after all, AI models are becoming more efficient, with each generation requiring less energy? And remember, the human brain runs on merely 20 watts of power. While a mature superintelligence system might eventually operate with comparable efficiency, developing it FIRST requires immense resources for a couple of reasons:
- Brute force development: Current AI research prioritizes raw computational power over efficiency to achieve rapid breakthroughs.
- Parallel experimentation: Advancing sometimes requires running lots of training variations simultaneously to see what works.
- Scale requirements: Achieving human-level thinking demands exponentially more compute than current language models.
Then there’s Jevons paradox. As energy production becomes more efficient, we aren’t using less, but more. And if compute is the new “means of production”, more hardware would always be a plus.
There’s an alternative way to approach this: distributed compute, leveraging globally available hardware to achieve massive scale without centralized infrastructure.
So what if the real race is between closed source proprietary development vs open source and accessible technology for all—instead of between geopolitical powers or certain companies?
A leaked internal Google document (if one can believe it) details this dimension of the race: that open source AI is rapidly outpacing both Google and OpenAI, doing "things with $100M and 13B params that we struggle with at $10M and 540B." The success of projects like DeepSeek, which achieved frontier model capabilities at a fraction of the costs, validates this concern.
The document concludes that traditional tech companies "have no moat" in this race, as open source alternatives become increasingly customizable, private, and capable, achieving results in weeks rather than months.
Is open development the path forward?
How will AGI reshape the rules of our socio-economic structures?
Can superintelligence be controlled?
Will everything change once we’ve developed superintelligence, or will it instantly become normalized like every other technological revolution in the last hundred years?
How large is the gap between reaching AGI and the technological singularity? In other words, how much lag will there be between cutting-edge capabilities and widespread adoption?
There are many open questions remaining, but one thing is for certain: we won’t get bored anytime soon.
Sources
Position: Levels of AGI for Operationalizing Progress on the Path to AGI – Google DeepMind
OpenAI Scale Ranks Progress Toward ‘Human-Level’ Problem Solving – Bloomberg
‘Alan’s conservative countdown to AGI’ – Alan D. Thompson
The Bitter Lesson – Richard Sutton
o1 Technical Primer – Jesse Hoogland
Learning to reason with LLMs – OpenAI
OpenAI's o3 Sets New Record, Scoring 87.5% on ARC-AGI Benchmark
CISCO - AI Summit 2025 – OpenAI COO Brad Lightcap
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Kimi K1.5: Scaling Reinforcement Learning with LLMs
Mind Evolution: An Evolutionary Leap in LLM Inference – Google DeepMind
New physics sim trains robots 430,000 times faster than reality – Ars Technica
π0: Our First Generalist Policy – Physical Intelligence (π)
Genesis: A Generative and Universal Physics Engine for Robotics and Beyond
NVIDIA CEO Jensen Huang Keynote at CES 2025
Extreme Off-Road | DEEPRobotics Lynx All-Terrian Robot
The moment we stopped understanding AI [AlexNet] – Welch Labs
The Platonic Representation Hypothesis
LLMs struggle with perception, not reasoning, in ARC-AGI – Mikel Bobel-Irizar
Building with Gemini 2.0: Native image output – Google for Developers
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku – Anthropic
OpenAI Preps ‘Operator’ Release For This Week – The Information
OpenAI Targets AGI with System That Thinks Like a Pro Engineer – The Information
Dynamic Deep Learning | Richard Sutton
Titans: Learning to Memorize at Test Time – Google Research
Attention Is All You Need – Google Research; Google Brain; University of Toronto
Frontier Models are Capable of In-context Scheming – Apollo Research
My AI agent started conspiring against me!
Instrumental convergence – Wikipedia article
Universal Paperclips videogame
We might build AGI by 2026 | Dario Amodei and Lex Fridman
Machines of Loving Grace – Dario Amodei
OpenAI Product Chief on Trump-Backed ‘Stargate,’ New AI Models and Agents | WSJ
Google DeepMind CEO Demis Hassabis: The Path To AGI, Deceptive AIs, Building a Virtual Cell
Announcing the Stargate Project – OpenAI
The Global AI Talent Tracker 2.0
NeurIPS 2024 Accepted Paper List
Jevons paradox – Wikipedia article
The Intelligence Curse – Luke Drago
The Second Bitter Lesson – Adam Elwood
Situational Awareness: The Decade Ahead – Leopold Aschenbrenner


