


The shift toward software engineering best practices in data and ML development promises faster, more reliable deployments—but only if your infrastructure can support it.
DevOps best practices, such as source control, code reviewing, test automation, and CI/CD, have always been problematic for data teams. Data engineering frameworks and technologies rarely apply these best practices really well. But since the release of Declarative Automation Bundles (DAB, formerly Databricks Asset Bundles) in 2024, Databricks has made several steps down this road.
When it comes to enterprise DevOps, several domains (such as healthcare or financial services) require software solutions to run on isolated networks. In our experience, implementing CI/CD for Databricks projects on isolated networks can present several challenges. In this post, we uncover preferred approaches to resolving these challenges on Databricks application projects.
A repository of central workflows
In production, there are usually multiple Databricks environments, and several data and ML projects in separate repositories. Implementing and maintaining the CI/CD of such projects is quite a challenge. For this purpose, we advise the architecture of:
- multiple project repositories, as needed
- a single CI/CD repository for storing and maintaining the workflows
- federated credentials, where environments are added into the managed identity or service principal as needed.
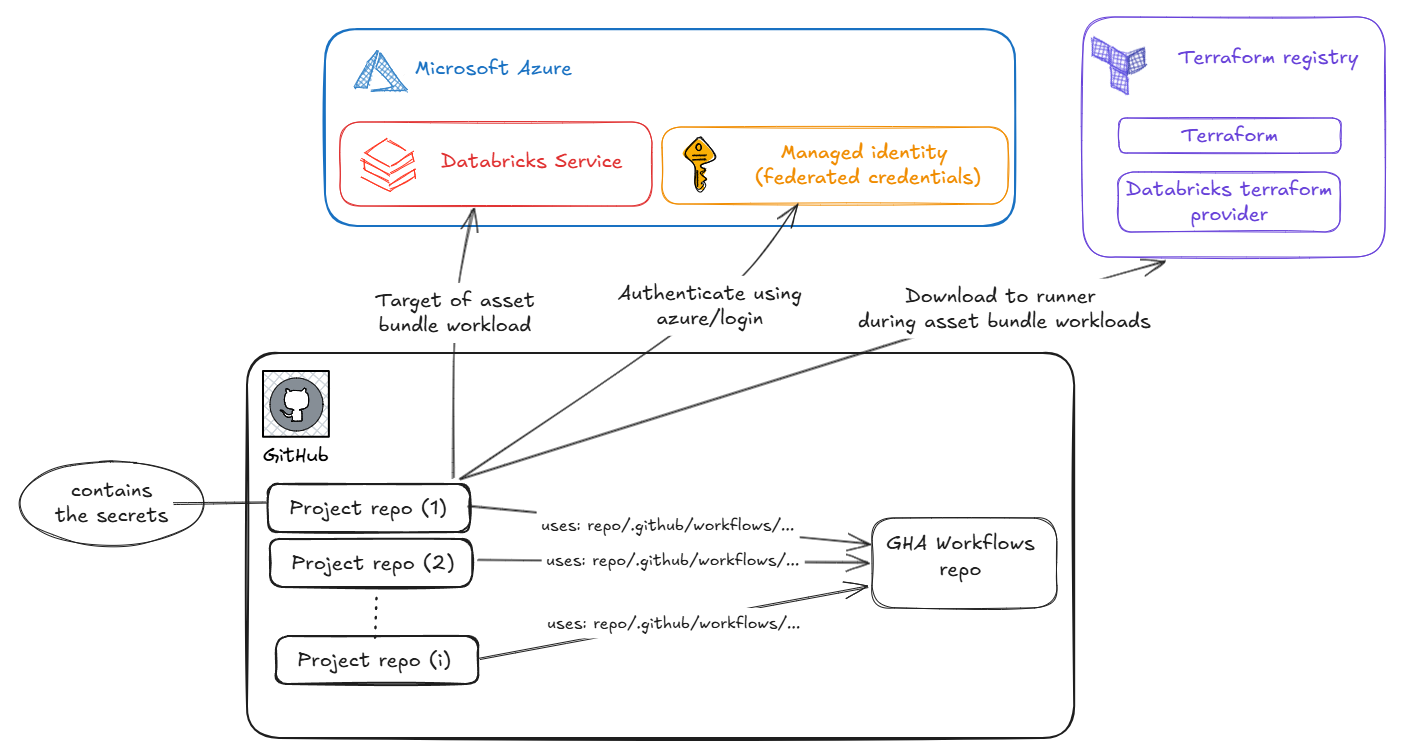
In this pattern, we have to implement two types of workflows:
- dispatcher workflows–which are placed inside the project repositories, and call into the CI/CD repository, and
- reusable workflows–which are in the CI/CD repository and contain the business logic.
One great advantage of this approach is that we only need to maintain the GHA workflows in the central repository. For example, if azure/login gets a third version, then we do not need to refactor a bunch of project pipelines. We only need to change the reusable workflow azure/login@v2 to azure/login@v3.
Another advantage is that we can produce multiple releases on the CI/CD repository, and make certain types of projects use different releases. For instance, certain domains require a higher level of isolation, and therefore, we might preload Terraform into the runners so the workflow does not need to fetch it from the registry.
We will walk through the reusable variant in this post in detail, as we introduce how to perform network isolation, but let`s also see an example dispatcher.
on:
workflow_dispatch:
jobs:
trigger-validate-code:
uses: organization/repository/.github/workflows/name-of-workflow@ref
secrets: inherit
The above example shows how simple it is to reference the reusable workflow. Setting up the path in the `uses` parameter is crucial. Every reusable workflow must be inside the .github/workflow/ path, getting this wrong is a common issue. In the @ref we may store the name of a branch or tag of a release. Secrets are also inherited, meaning that GHA passes them to the CI/CD repository.
Isolating Databricks CI/CD solutions
To isolate a DAB deployment, we need to make sure to set up the following correctly:
- usage of a proxy server to route traffic
- loading and enforcing the usage of our own terraform binary
- loading and enforcing the usage of our own terraform provider
Setting up the proxy is the easiest task, as it only requires setting the environment variables `HTTP_PROXY` and `HTTPS_PROXY` in the `env` section of all DAB commands, as
- name: Name of bundle step
run: databricks bundle {...}
env:
...
HTTP_PROXY: "http://proxyurl:port"
HTTPS_PROXY: "http://proxyurl:port"
Setting up our own Terraform and Terraform provider is more complex. Let’s start by setting up the executable.
Generally, the usage of `hashicorp/setup-terraform@v3` is considered safe. However, we may load the Terraform executable from a trusted artifactory with a composite workflow to the runner as well. We are going with the first option, so the step in the pipeline will be the following:
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
with:
terraform_version: "x.xx.x"
terraform_wrapper: false
The above step installs a specific version of Terraform. We disable the `terraform_wrapper` which GitHub Actions would add to make sure we have direct access to the Terraform binary. Once Terraform is downloaded to the runner, we echo the path to the executable for further usage in the following step:
- run: |
tf_path=$(which terraform)
echo "tf_path=$tf_path" >> "$GITHUB_OUTPUT"
id: tf_path
Now, the exact path of Terraform is stored in the `tf_path` variable, which can be accessed as `steps.tf_path.outputs.tf_path` by further steps.
The next step is to get the Databricks Provider. This creates a local filesystem mirror for the provider to enable offline deployment. Here, the directory is set up to replicate the layout of the remote registry:
.tf-mirror/providers/
└── registry.terraform.io/
└── databricks/
└── databricks/
└── x.xx.x/
└── linux_amd64/
└── terraform-provider-databricks_x.xx.x_linux_amd64.zip
This filesystem mirror is structured and populated by the following code.
- name: Setup filesystem_mirror for Databricks provider
run: |
set -euo pipefail
VER="1.85.0"
OS_ARCH="linux_amd64"
PROVIDER_REPO_URL="url-to-the-provider-repo"
# Create filesystem_mirror structure as per Databricks CLI docs
MIRROR_DIR="$GITHUB_WORKSPACE/.tf-mirror/registry.terraform.io/databricks/databricks"
mkdir -p "$MIRROR_DIR"
ZIP_NAME="terraform-provider-databricks_${VER}_${OS_ARCH}.zip"
TARGET_ZIP="$MIRROR_DIR/$ZIP_NAME"
curl -fL "${PROVIDER_REPO_URL}/${ZIP_NAME}" -o "$TARGET_ZIP"
ls -la "$MIRROR_DIR"
In this step, after fixing the Terraform version, the operating system of the runner, and the url from which the Databricks Terraform provider should be downloaded, the following steps are performed:
- using the `MIRROR_DIR` variable, the filesystem mirror path is made
- using the `curl` command, we download the provider zip from the provider repository
This step places the Databricks Terraform provider at the proper place, in a zip format, as DAB expects the provider to be in a zip file.
Once that is ready, we need to make sure that DAB is using the local provider and is not trying to fetch it from the registry. For this purpose, we are using a `.terraformrc` file in the following manner.
- name: Set terraformrc with filesystem_mirror
run: |
MIRROR_BASE="$GITHUB_WORKSPACE/.tf-mirror"
cat > $GITHUB_WORKSPACE/.terraformrc <<EOF
provider_installation {
filesystem_mirror {
path = "$MIRROR_BASE"
include = ["registry.terraform.io/databricks/databricks"]
}
direct {
exclude = ["registry.terraform.io/databricks/databricks"]
}
}
EOF
This step creates the `.terraformrc` file inside the `.tf-mirror` folder. This file has two key parts.
- The filesystem mirror, which we can see as the local version of the Hashicorp registry, containing the Databricks Terraform provider. The `include` parameter directs the solution to use the local provider.
- The direct part controls direct downloads from the registry; accordingly, we `exclude` the remote version of the provider.
Finally, we need to pass the Terraform configuration to all following steps in the pipeline.
- name: Export Terraform environment
run: |
echo "TF_CLI_CONFIG_FILE=$GITHUB_WORKSPACE/.terraformrc" >> $GITHUB_ENV
echo "TF_PLUGIN_CACHE_DIR=$GITHUB_WORKSPACE/.terraform.d/plugin-cache" >> $GITHUB_ENV
Two variables are passed into the `GITHUB_ENV`:
- `TFI_CONFIG_FILE`, which is the path to the `.terraformrc` file, and
- `TFI_PLUGIN_CACHE_DIR`, where Terraform will extract the provider binary from the provider zip file.
Bundle deployment step with isolation parameters
Once the local usage of Terraform and the Databricks Terraform provider is enforced/made possible, we can work with our Databricks bundles. Let’s deploy the bundle in an isolated manner:
- name: Databricks bundle deploy
run: databricks bundle deploy
working-directory: .
env:
DATABRICKS_BUNDLE_ENV: ${{ env.DATABRICKS_TARGET_ENV }}
HTTP_PROXY: "http://proxyurl:port"
HTTPS_PROXY: "http://proxyurl:port"
DATABRICKS_TF_EXEC_PATH: ${{ steps.tf_path.outputs.tf_path }}
DATABRICKS_TF_PROVIDER_VERSION: x.xx.x
TF_CLI_CONFIG_FILE: "${{ github.workspace }}/.terraformrc"
DATABRICKS_TF_CLI_CONFIG_FILE: "${{ github.workspace }}/.terraformrc"
DATABRICKS_TF_VERSION: x.xx.x
TF_PLUGIN_CACHE_DIR: "${{ github.workspace }}/.terraform.d/plugin-cache"
We are using the following environment variables:
- `DATABRICKS_BUNDLE_ENV`, which sets the target environment from the `databricks.yml` file, values can come from earlier steps,
- `HTTPS_PROXY` and `HTTPS_PROXY` routes traffic through the set proxy,
- `DATABRICKS_TF_EXEC_PATH` sets up the Databricks CLI to work with the Terraform executable on this path,
- `DATABRICKS_TF_PROVIDER_VERSION` forces the Databricks CLI to use a specific version of the provider,
- `TF_CLI_CONFIG_FILE` points to the custom `.terraformrc` configuration, which overrides the provider setting,
- `DATABRICKS_TF_CLI_CONFIG_FILE` ensures that the Databricks CLI is using the same `.terraformrc` configuration,
- `DATABRICKS_TF_VERSION` specifies the version which Databricks expects, and finally
- `TF_PLUGIN_CACHE_DIR` sets up a directory where Terraform caches the provider plugins.
Conclusion
Using the above solution, we successfully addressed the network isolation problem on Databricks projects through Declarative Automation Bundles. The implementation hinged on the elimination of the pipeline’s reliance on external Terraform resources, while routing the traffic through a proxy. The two key aspects are:
- Controlled traffic through a proxy server by setting `HTTP_PROXY` and `HTTPS_PROXY` variables.
- Forcing the pipeline to fetch Terraform binary, and the Databricks Terraform provider from a set registry, while enforcing the local usage through the `.terraformrc` configuration, and filesystem mirroring.
Together with the centralized/reusable workflow architecture, this approach provides a secure, auditable, and maintainable approach to Declarative Automation Bundles.
Sources
Enable workload identity federation for GitHub Actions
Terraform CLI on GitHub Actions
Want to accelerate secure Databricks deployments with proven engineering best practices? Get in touch with our Databricks consultants.


