


Ever since the first version of SAP made its way to its users, it has been no less than a treasure trove of invaluable data yet to be exploited. But, as with any extraordinary bounty in the history of treasure hunting, there was a catch. Accessing this data so far has been a real challenge for any application outside of the SAP ecosystem itself. And the business model of SAP did not help mitigate it.
When the news first hit about the SAP and Databricks partnership we knew that things were about to change, and we're about to gain real integration benefits.
SAP and Databricks: What’s the big deal?
For those unfamiliar with the subject, the SAP ecosystem is a comprehensive network of products, services, and — most importantly for the sake of data applications — data products designed to address the diverse needs of modern enterprises. The SAP suite of products include software like ERP, CRM, SCM and PLM, not to mention a whole army of smaller products that help in various business use-cases.
To put the importance of SAP into perspective, it is worth noting that SAP software is being used by approximately 90% of Fortune 500 companies, making this a cornerstone matter for anyone trying to gain valuable insight from this kind of data.
Historically, working with SAP data has been a hassle. Not only is data siloed, but the technical complexity that makes SAP perform so well also makes accessing data and most importantly data context really hard.
Without built-in support for data export and import, data practitioners were forced to come up with clever SAP integration solutions, many times requiring third party tools, additional licenses and relying on various mechanisms to get the coveted data for their use-cases. This process usually was long and cumbersome resulting in, at best, daily exports. Nowhere near the requirements of the current landscape, where every company wants to be a Data and AI company where real time data is key.
To make things even harder, such exports often lost their business context and were plagued with quality issues, making insights gained from them unreliable.
This is about to change however. With the recent announcements made jointly by SAP and Databricks we got a blink into a new, much more open future where SAP data is easy to integrate with the vast amount of Databricks data.
Integration benefits of SAP and Databricks partnership
Databricks has been pioneering various technologies, many of which have been made open source for the benefit of an ever growing community. These technologies include things like Unity Catalog, Delta Lake and Delta Sharing.
This approach to core components of the Databricks ecosystem and the undeniable leadership position in the AI and data analytics world have led to the strategic partnership between SAP and Databricks.
Something that will benefit both SAP and Databricks — but most importantly their customers who, moving forward, will be able to easily integrate data from all corners of their data landscape and will be able to do this both in near real time and without too much of a challenge. And — if promises are kept, and why shouldn’t they — without breaking the bank.
So what exactly happened and how does this affect the status quo?
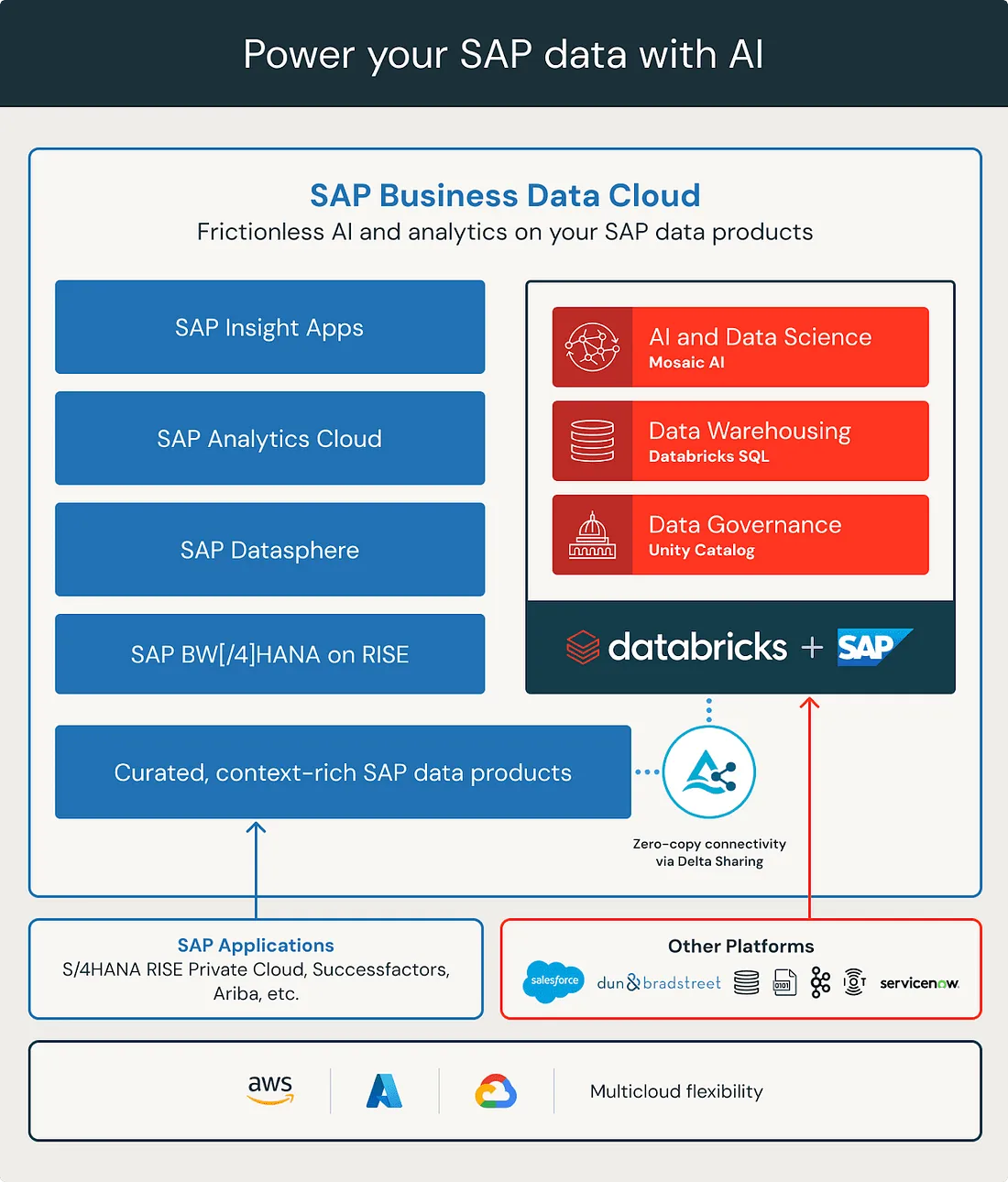
SAP just announced their next generation product line called the SAP Business Data Cloud (BDC for short) — and as its name suggests this is an offering that truly is cloud native.
One of its main benefits is that it transfers maintenance burden from the customers to SAP. With the introduction of BDC living in the cloud SAP made a huge step towards other cloud native solutions, opening the door for SAP integrations. And this is where Databricks comes into the picture.
In order to enable their customers to work with advanced AI use-cases and integrate their entire data landscape with SAP data, BDC has introduced two distinct ways to connect or use Databricks with SAP BDC.
Source: databricks.com
What is SAP Databricks?
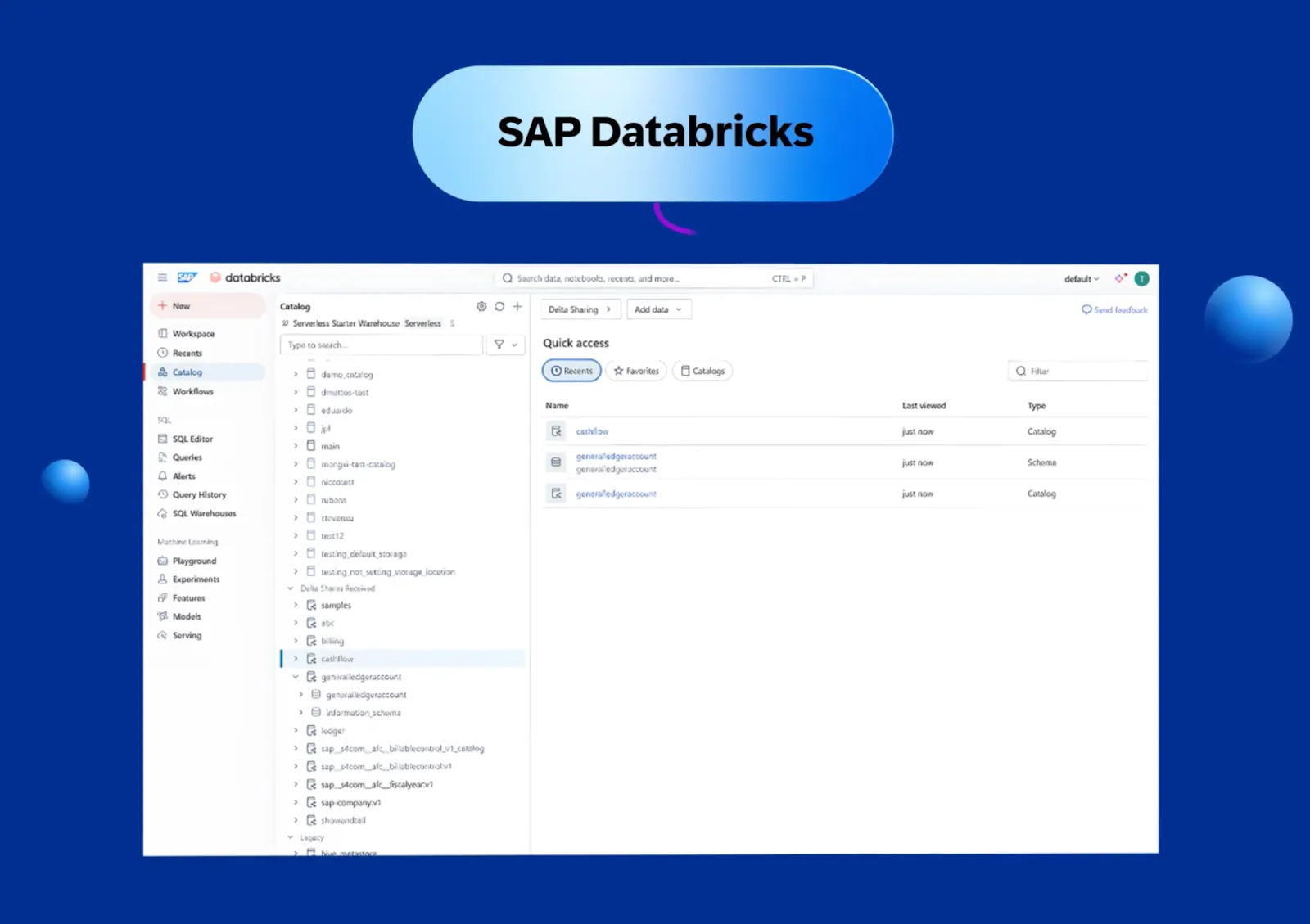
Simply put, SAP Business Data Cloud has Databricks built in, right out of the box. This version of Databricks is called SAP Databricks and is a first party data service of BDC, purpose built for SAP-centric workloads. This means that customers of BDC can use the vast analytics and AI capabilities and services of Databricks.
In addition, they can bring in their data from other systems directly to SAP Databricks making cross-platform workloads operate seamlessly–all while never requiring subscribing or contracting any other parties outside of SAP. SAP Databricks is considered an SAP product and is geared towards heavy SAP users that may be new to the world of Databricks.
Its main marketed purpose is to power SAP data-centric use cases where SAP data is blended with other structured and unstructured data to build domain specific AI products. It is also a great place for exploratory data analysis.
Capabilities of this offering, while vast and overarching, still seem to lack many things that are present in standard Databricks.
Source: sap.com
Notably missing from the menu is the option to interact with traditional, all-purpose clusters, meaning that only the serverless infrastructure is available in SAP Databricks. While this, the classic compute, is a historically important component, recently Databricks has made it clear that serverless is the main focus for the company in the future. So while the absence of the capability might seem surprising at first, it all makes sense if we dig a bit deeper into this product.
What is all-purpose compute in Databricks?
Databricks has two core compute types: serverless and all-purpose compute. To understand the difference between the two one needs to understand how Databricks is built, what its two core layers or “planes” are and most importantly where each of its components live.
Databricks is divided into two main planes, one of them traditionally called the Control Plane and the other the Data Plane. Recently, due to the direction things are being developed in, the naming and logical grouping of these planes have been changed a bit, introducing things like the Serverless Compute Plane and dividing the Data Plane into two: the Classic Compute Plane and storage.
In this case the most important distinction between the two is who manages what and who owns the subscription the cloud resources needed for day-to-day operations are provisioned in. The Control and the Serverless Compute planes are created in a subscription owned by Databricks where the other two are in subscription(s) owned by the customer.
All serverless infrastructure as well as a lot of other important resources required by Databricks to work are created in the Control Plane and the Serverless Compute Plane. This means that all resources here are managed, secured and maintained by Databricks.
As for traditional, All-Purpose Clusters, they are created in the Classic Compute Plane. When creating an All-Purpose Cluster traditional virtual machines are provisioned and an appropriate runtime environment (called DBR) is installed during cluster startup, custom networking included. These raw resources are consumed through the subscription of the customer. Working with this compute type resembles classic Spark workloads the most, even though it is supercharged by Databricks with all sorts of improvements like the Photon engine.
Since BDC is an SAP offering and, even though really similar to other cloud applications, it’s still not something that a customer installs in their own cloud subscription. This means that there is no customer cloud subscription to speak of in regards to BDC, therefore the missing APC option does make sense. It is yet to see if other features like Databricks Apps that also live in the Compute menu will make their way to SAP Databricks.
Other things seem to be missing are data engineering features like job runs and pipelines, Dashboards and Genie, Databricks’ very own all-knowing, business oriented AI assistant. Since Databricks is positioning this partnership as something aimed at AI use-cases, this shouldn’t come as a surprise.
What is external Databricks connection?
While a lot of companies currently using SAP may be new to Databricks, a lot of other companies already have their Databricks ecosystem with all other data in place, potentially with the aforementioned complex and rigid data pipeline built in to enrich their data assets with some SAP data. The second offering of SAP BDC is exactly for them.
With this option, BDC will have a built-in, native connector that can be used to achieve near-real time and robust integration between SAP BDC and the existing Databricks ecosystem. This means that gone are the days of complex, rigid and problematic SAP data loading pipelines for all future BDC subscribers. It makes upgrading to BDC more compelling for current SAP customers as well as promising a much more open environment for potential future customers.
The connector ensures a seamless integration between the two environments, providing native access to SAP data within Databricks, comparable to the smooth connectivity offered by the SAP Databricks solution. Since these external Databricks workspaces are full and complete workspaces with all the bells and whistles — including cutting edge new features that Databricks platform has to offer — it is truly a combination with the best of both worlds.
What tech powers SAP and Databricks integration?
As with everything, the devil is in the details. We’ve touched upon the existence of the open source project of Databricks called Delta Sharing at the beginning of this article. This is important in this case, as Delta Sharing seems to be powering this entire show. All of the material surfaced so far seems to be pointing at a common architecture in which a delta share is powering both the SAP Databricks and the external connection approach, underlining the assumption that from a data availability viewpoint both solutions are equal.
What is a Delta Share?
Data in Databricks usually is stored by default in a format called Delta. Delta is a clever way of storing data in parquet — thus reducing costs — while endowing it with features that were traditionally only available in classical relational databases and data warehouses. It is worth noting that Delta is not the only format doing this, Iceberg and Hudi are also great examples, but that is a topic for a different article.
Delta Sharing is an open-source, zero copy protocol that is capable of sharing terabyte scale datasets between compatible systems. It has integration with many platforms and is not something limited to Databricks only. It enables companies to use their data across multiple regions, ecosystems and projects all while remaining in their tool of choice.
The Delta Share project is a part of the Linux Foundation Projects, meaning it is not something that a single company has control over, therefore ensuring the protocol shall remain usable in the future.
The fact that Delta Sharing is used to grant access to the data also means that data falls out of the box under the governance of Databricks’ highly capable governance layer, called Unity Catalog. This offers a harmonized view of both SAP and non-SAP data as well as allowing monitoring and observability to the entire pipeline in a single view of all components. With its built-in tagging and auto classification capabilities AI system compliance is improved.
The Data Model — one of the old puzzles solved
One of the most pressing issues with working with SAP data outside of its natural habitat has been the data model.
SAP has its complex and performant way of storing data that needs “decyphering” and restructuring engineering work to serve a meaningful analytics purpose and if the source model underneath changes, the pipelines built on top break. Since the feature outlined so far is mainly an SAP offering this part also seems to be solved, as SAP offers to serve enriched and curated data.
These data products align to a highly optimized and unified “One Domain Model”, maintaining their business context and semantics. Data Products are fully managed by SAP, ensuring that no maintenance is needed. This in itself is exceptionally valuable and will make life so much easier.
There are some more pieces of the puzzle that need to be figured out in this new landscape, but one thing is for sure. Even though the main focus of this partnership is AI, there is tremendous value to be had for all kinds of other use-cases and ways to benefit with Databricks SAP integration. But today, the legions of data engineers sigh in relief in anticipation of the new, more open world of SAP to come.


