


Arguably, Model Context Protocol (MCP) has been the most impactful conceptual development in the past 6 months in the AI world. It has created a simple but effective way for GenAI models to access data, either directly or through “tools”.
On the surface (or at a high enough abstraction level) MCP is fairly simple.
Smart LLM models are given tool documentation in a specific way. Models know (i.e., learned during training) that they can use these tools in order to solve the tasks they are given. These tools can be anything that can offer data context, from CRM systems, through ETL transformations, to direct data access.
On the other “side” there are different kinds of tools: ones that want to solve problems with LLMs. Let’s call them “Business Agents” (although the word “agent” is rather overloaded in modern AI parlance). They can be, for example, AI-powered development environments, support chatbots, or custom enterprise process automation agents. These are called “MCP clients”. They interact with LLMs and–among other things–they can instruct them to use tools that are provided as MCP servers.
Making one’s system part of the AI ecosystem is, obviously, of great interest to system developers and providers. Other 3rd parties can also use the tools’ APIs to create MCP servers. And indeed, there is a “Cambrian explosion” of MCP servers available.
So MCP servers are all the rage nowadays. Agentic, AI-enabled solutions are hyped to the sky, so MCP clients also make the news. LLMs, well … they are the headlines.
It’s fair enough that many of the “modern” LLMs are MCP-capable, in that they can “call” MCP tools. But how do they do it, exactly? An LLM model is a (very large) set of weights and an algorithm that can predict what the next “word” (token) should be in a sequence. Nowhere can it “call” anything, much less converse over a proper protocol with other systems.
There is a part of this ecosystem that is talked about a lot less: the serving platforms that lay between the “Business Agents” (that “invoke” LLMs) and the models themselves.
Whenever a software solution invokes an LLM, it does so first through the SDK of the platform, which then goes through to the serving platform itself, which restructures the call and passes some of it to the LLM. The LLM may respond with special tokens that are intercepted by the serving platform. These tokens can induce that the serving platform should reach out to an MCP server and fetch some data. The platform, in turn, passes the data back to the LLM as part of the context. From there, the LLM continues as if it had the data all along: it returns the result to the "Business Agent" via the serving platform and the SDK.
This is a bit dense, so let’s break it down:
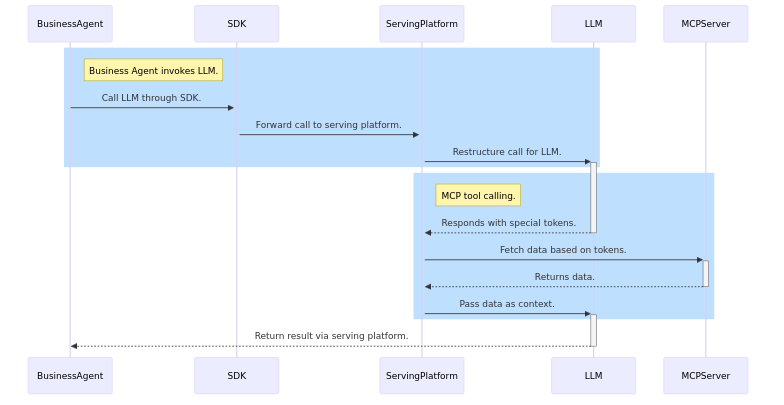
The diagram clearly shows that the LLM itself never corresponds with the MCP server: all interactions are through the “Serving Platform”.
This setup has a few interesting implications.
The first one is that the same LLM may act differently depending on the serving platform. As an extreme example, a provider may offer an MCP-capable LLM model with a serving layer that does not implement the MCP functionality. That would result in the user being able to access the LLM but would be unable to use its full functionality. (I.e., that platform may offer, say, DeepSeek-R1, but without an MCP-capable serving layer. Then users would be able to use R1 as an MCP-less, “traditional” LLM.) But obviously, no amount of MCP functionality in the serving platform can make a non-MCP-capable LLM into an MCP-capable one, as it is the model that needs to request a certain MCP tool.
Many leading models are primarily provided by their owners through their own serving platforms. These platforms natively support MCP so that model owners can expose the full functionality of their models. There are 3rd party platforms, though, that serve some of these models. For example, both AWS Bedrock and Databricks make Claude’s models available through their own SDKs and serving platforms. In these cases, AWS and Databricks have to make sure that their platforms properly support MCP–both towards MCP servers and towards the very LLMs they serve.
Another noteworthy aspect is that the interactions between serving platforms and models are model-specific. So, while MCP has standardized a protocol for MCP server discovery and calling, it is not at all standardized at model level or between models and serving layers. This is something LLM users (“Business Agent” developers) would see only in that platform SDKs are somewhat different. These SDKs, though, hide much deeper differences in the ways models interact with the serving platform.
The interactions between client tools and the underlying models are all but invisible for almost all users. Still, they play a critical role in processing MCP calls and thus they are key components of modern, agentic AI use cases.


