


When building event-based and streaming pipelines, data engineers might face a couple of challenges. You have data sources feeding into Apache Kafka, transformation requirements, and stakeholders expecting processed results. The traditional approach means designing architectures from the ground up, resulting in a time-consuming process that often delays delivery.
This is where Lakeflow Spark Declarative Pipelines (previously Delta Live Tables/DLT) enters the chat.
What is Lakeflow Spark Declarative Pipelines?
Lakeflow Spark Declarative Pipelines (SDP) is one of the most powerful tools in the Databricks ecosystem. It simplifies the creation of data pipelines by automating many aspects, which earlier meant a lot of work for data engineers, while providing a declarative approach so you can focus on the desired state of the pipeline, instead of implementing steps one by one.
There are two main methods for building pipelines, both of which utilize it for automating the DAG (directed acyclic graph) creation and task orchestration, as
- from the Databricks UI, as a series of notebooks,
- using Declarative Automation Bundles (DAB) CI/CD tool, which addresses an infrastructure-as-code approach
Additionally, Lakeflow Spark Declarative Pipelines includes data quality monitoring and expectation handling. Data that doesn't meet specifications gets flagged and processed according to your rules without disrupting the pipeline.
On the resource optimization side, the system adjusts compute resources based on data volume and processing requirements automatically.
Building the pipeline
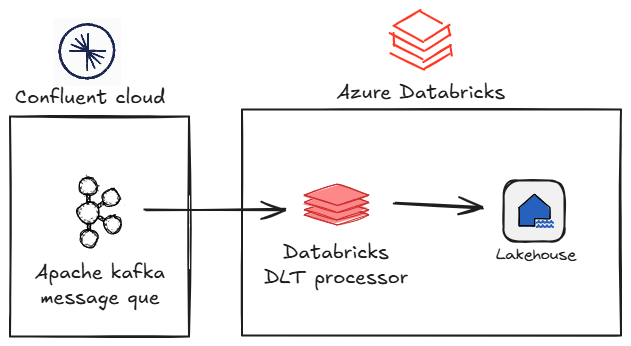
Let’s examine building a streaming pipeline through a simple example of integrating Confluent Kafka and Azure Databricks.
Integrating Databricks and Confluent Kafka with Lakeflow Spark Declarative Pipelines
The solution utilizes:
- a Confluent organization inside Apache Kafka & Apache Flink on Confluent Cloud, containing our environment and cluster for Apache Kafka,
- Databricks workspace,
- Azure Key Vaults, to hold information about our Confluent API keys,
- Azure Storage account with a Data Lake Gen2 container and an Access Connector for Azure Databricks to enable the usage of Unity Catalog.
Cofluent Kafka and Lakeflow Spark Declarative Pipelines (previously DLT)
Data ingestion
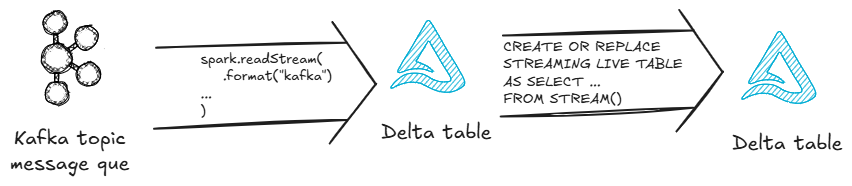
The first stage receives transaction data from Confluent Kafka, in a single notebook.
To begin with, necessary dependencies are injected.
from pyspark.sql.types import *
from pyspark.sql.functions import *
import dlt
Then, the message’s schema in the Kafka stream is defined, and using this, we define a function as well. This is later used to process the JSON data. This is optional and only an example, as this issue can be solved in many ways.
message_schema = schema
def parse_message_json(data, json_column_name):
schema = message_schema
data = data.withColumn("parsed_json", from_json(col(json_column_name).cast('string'), schema))
all_cols = data.columns + [f"parsed_json.{field.name}" for field in schema]
return data.selectExpr(*all_columns).drop(json_col_name, "parsed_json")
Then, the Kafka stream is defined with a Spark DataFrame
df = (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "...")
.option("subscribe", "...")
.option("startingOffsets", "earliest")
.option("maxOffsetsPerTrigger", 100)
.option('kafka.security.protocol', 'SASL_SSL')
.option('kafka.sasl.mechanism', 'PLAIN')
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule '
f'required username="{dbutils.secrets.get(scope="...", key="...")}" '
f'password="{dbutils.secrets.get(scope="...", key="...")}";'
)
.load()
)
This way, you can utilize Apache Kafka and Confluent clusters without deep Kafka expertise. Consumer groups, offset management, and connection handling are abstracted away, allowing you to focus on business logic rather than infrastructure details.
Quality gates
Another major thing is that Lakeflow Spark Declarative Pipelines’ expectation framework provides automated quality control:
@dlt.table(table_properties={"pipelines.reset.allowed":"false"})
def bronzeMessages_thread1():
return parse_message_value(df, json_col_name)
Note that the function parse_message_value is called at this step. Once this notebook is added to a pipeline, data can be streamed from Kafka to Databricks.
Records that fail validation are flagged, quarantined, or dropped based on business rules without custom exception handling.
Refining data
Once data enters the bronze layer (two bronze tables, which are two threads of messages, loaded from Confluent Kafka), it can be further processed. Although streaming from Confluent Kafka to Databricks requires the solution to be implemented with Python, streaming workloads on higher layers can be written using standard SQL syntax.
Lakeflow Spark Declarative Pipelines orchestrates the transformation into a single silver table:
create or replace streaming live table silver.kafkaMessages as
select
key
,topic
,cast(partition as string) as partition
,cast(offset as string) as offset
,timestamp_1 as timestamp
,cast(timestampType as string) as timestampType
,cast(amount as int) as amount
,mode
,type
,customer
,transaction_id
,timestamp as messages_timestamp
from stream(bronze.kafkaMessages_thread_1)
union all
select
key
,topic
,cast(partition as string) as partition
,cast(offset as string) as offset
,timestamp_1 as timestamp
,cast(timestampType as string) as timestampType
,cast(amount as int) as amount
,mode
,type
,customer
,transaction_id
,timestamp as messages_timestamp
from stream(bronze.kafkaMessages_thread_1)
The above code snippet can be placed in a notebook, all by itself, and dropped into the same pipeline as the streaming notebook from Confluent Kafka. Lakeflow Spark Declarative Pipelines will take care of the rest: it will implement the DAG, tables, and control flow. With the push of a button, data will start streaming.
Deploying the pipeline
This section can be applied to all Lakeflow Spark Declarative Pipelines workloads, not only streams.
When working with Confluent Kafka, the confluent-kafka PyPi library must be added to the notebook, which handles the Kafka streaming. This can be done, inside the notebook, as
%pip install confluent-kafka==2.8.0
Besides this, the deployment of the pipeline is pretty standard. Choosing between Lakeflow Spark Declarative Pipelines UI or DAB is up to you. Usage of DAB enables you to further enhance CI/CD, and apply software engineering and DevOps best practices through GitHub Actions pipelines, for example.
Lakeflow Spark Declarative Pipelines’ biggest wins
Databricks will enable you to leverage the power of Apache Kafka and Confluent clusters without the need to know how to develop with Kafka. Apache Spark and SDP simplify the tech stack and accelerate development.
One of the big selling points of Lakeflow Spark Declarative Pipelines is the usage of Spark SQL for streaming. This makes writing streaming workloads simple and approachable for most developers.
Other advantages include
- Development Efficiency: Pipeline development time is substantially reduced compared to custom implementations
- Maintenance Simplification: Declarative, version-controlled configuration makes changes predictable and testable
- Team Accessibility: SQL-proficient team members can contribute to streaming pipeline development
- Operational Benefits: Built-in monitoring, automatic retries, and Unity Catalog integration reduce operational overhead
The reality check
On the other hand, Lakeflow Spark Declarative Pipelines has practical limitations that teams should understand:
Documentation Coverage: Some integration scenarios, particularly with Kafka, lack comprehensive documentation. Authentication patterns and optimization strategies may require experimentation.
Development Environment: While development mode exists, it's constrained to specific cluster configurations with limited local IDE support. Most development occurs in Databricks notebooks.
Processing Model: Lakeflow Spark Declarative Pipelines uses micro-batch processing rather than true event-by-event streaming. For applications requiring real-time access, this may present limitations.
Learning Requirements: While SQL streaming is more accessible, teams still need an understanding of streaming concepts like watermarks and late-arriving data. The abstraction reduces but doesn't eliminate the need for streaming knowledge.
Should you make the switch?
Over the past years, both Databricks and Apache Spark have proved that they can serve as the cornerstone of data warehousing, ETL, and big data applications. With Lakeflow Spark Declarative Pipelines, Databricks made a step forward. Now with full Unity Catalog integration, developing real-time message streaming applications has never been easier.
Start with a pilot project to understand the framework's capabilities and limitations. Embrace the declarative approach rather than trying to replicate imperative patterns. Prepare for reduced infrastructure complexity, but maintain awareness of the underlying streaming concepts. And feel free to reach out to us for Databricks consulting services if you need help making the first steps.
The shift from custom-built solutions to declarative frameworks represents a broader evolution in data engineering. Tools like Lakeflow Spark Declarative Pipelines make real-time data processing accessible to wider teams while maintaining enterprise reliability.
The decision isn't whether to adopt these approaches, but how to effectively integrate them into existing workflows and team capabilities.


