


Welcome to AI Agents! This post provides an overview of agentic behavior and multi-agent structures. We'll also cover approaches to create practical, transparent, and secure automated workflows.
Update (May 2025): From High-Level Concepts to Practical Application
(Editor's Note: This section was added retroactively to guide you to our latest, more in-depth resources on AI agent development.)
When we first published this high-level overview, the world of AI agents was evolving rapidly. Since then, we’ve amassed a year worth of practical experience in building and deploying them. If you're ready to move from concept to execution, we have two fresh resources for you:
- For a look at the specific tools and standards powering modern agentic systems, our follow-up article on Frameworks, Protocols, and Practical Tips for Building AI Agents is the perfect next step.
- See how these frameworks are applied to solve real-world software development challenges in our new whitepaper, "Integrating Reliable AI Agents into the Digital Product Development Lifecycle." Download your copy here to see our coding agent blueprints in action.
What Are AI Agents?
At its core, agency means taking initiative—making decisions and actions that have real-world effects. But what does this mean in the context of AI?
AI agents, and agentic behaviors or workflows, are systems that use AI models to exert some level of control over an application's processes.
Interestingly, when we discuss agents with our clients or other data professionals, we often encounter a wide range of ideas about what the definition should entail. Some are content with existing multimodal LLM capabilities, while others won't settle for anything less than superintelligence.
But here's the thing: from a business standpoint, the technical definition is largely irrelevant. Even the simplest agentic workflow, which consists of only just API calls, can automate and optimize tasks.
That said, our current approach aims a little higher. Let's explore what that looks like.
Multi-Agent Systems – Structures Of Interaction
A multi-agent architecture consists of an ensemble of AI models. These compound systems enable you to automate complex tasks with greater efficiency and accuracy than a single agentic workflow would be capable of.
Let’s examine some dimensions with which we can categorize multi-agent systems:
Communication
- Centralized
- Decentralized
Hierarchy
- Flat (Equi-level)
- Hierarchical
- Nested
Connectivity
- Fully Connected
- Partially Connected
- Hub and Spoke
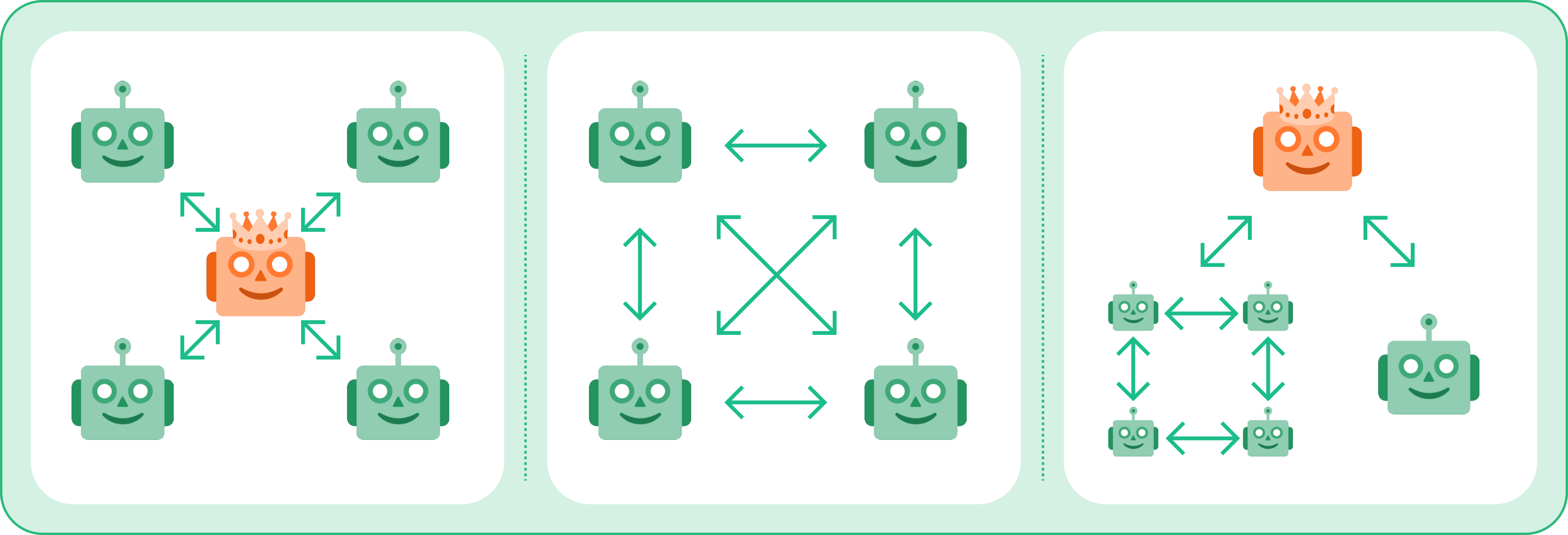
Inspirations: Han et al, 2024; Guo et al, 2024
Here we have three different multi-agent setups, from left to right:
- Centralized, Hierarchical, Hub and Spoke
- Decentralized, Equi-Level, Fully Connected
- Nested, Hybrid-Hierarchical, Partially Connected
The above illustration combines concepts from two sources:
- Structures of multi-agent systems by Han et al, 2024 in LLM Multi-Agent Systems: Challenges and Open Problems
- Agent communication structures by Guo et al, 2024 in Large Language Model based Multi-Agents: A Survey of Progress and Challenges
These categories are not mutually exclusive with each other—you can mix and match them, creating increasingly complex systems. The list of categories isn’t exhaustive either. You can come up with a myriad of ways of abstractions, and must determine the approach most useful to your project on a case-by-case basis.
Just ensure to tailor your design to your needs, otherwise overcomplication may hinder practical functionality (more on this later).
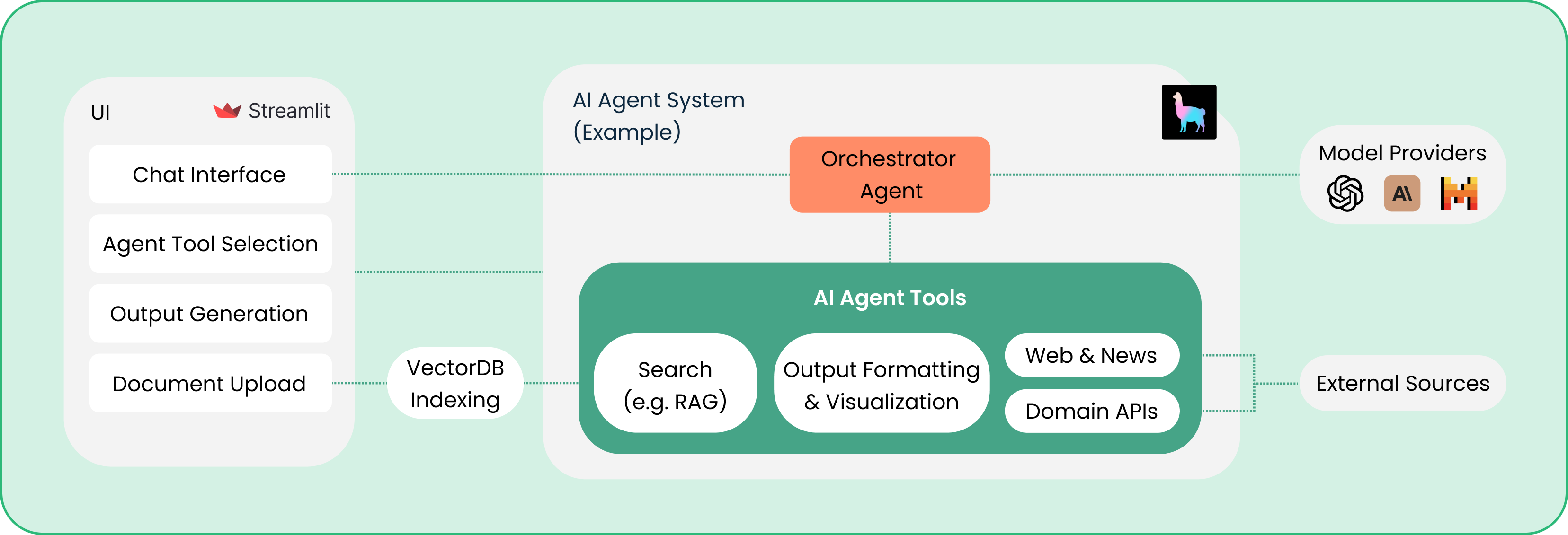
Let’s review typical components of multi-agent systems:
- Orchestrator / Leader agent:
Overseeing an ensemble of models and processes. - Follower / Executor agent:
Responsible for actions, decisions, or resources within specific areas of expertise. - Tools & scripts:
The glue that holds everything together—scripted actions and function calls tie agents to predetermined processes. Additionally, various external tools and auxiliary features can be implemented to enhance functionality and user experience. - UI elements:
A vital part of application design. (You should tailor the UI to your processes once you move into production!) - Infrastructure and Operational Ecosystem:
(Not explicitly shown on the above diagram.)
Your main goal should be to build modular components that represent specific skills or tasks, and create a system in which they interact. This way, you can:
- Define, build, and debug components individually
- Audit the steps the agents are taking to reach their goals
- Expand the toolkit and skillset of your agents as you observe failure cases
Agent Ingredients
But what goes into cooking up a single agent? Let's break it down!
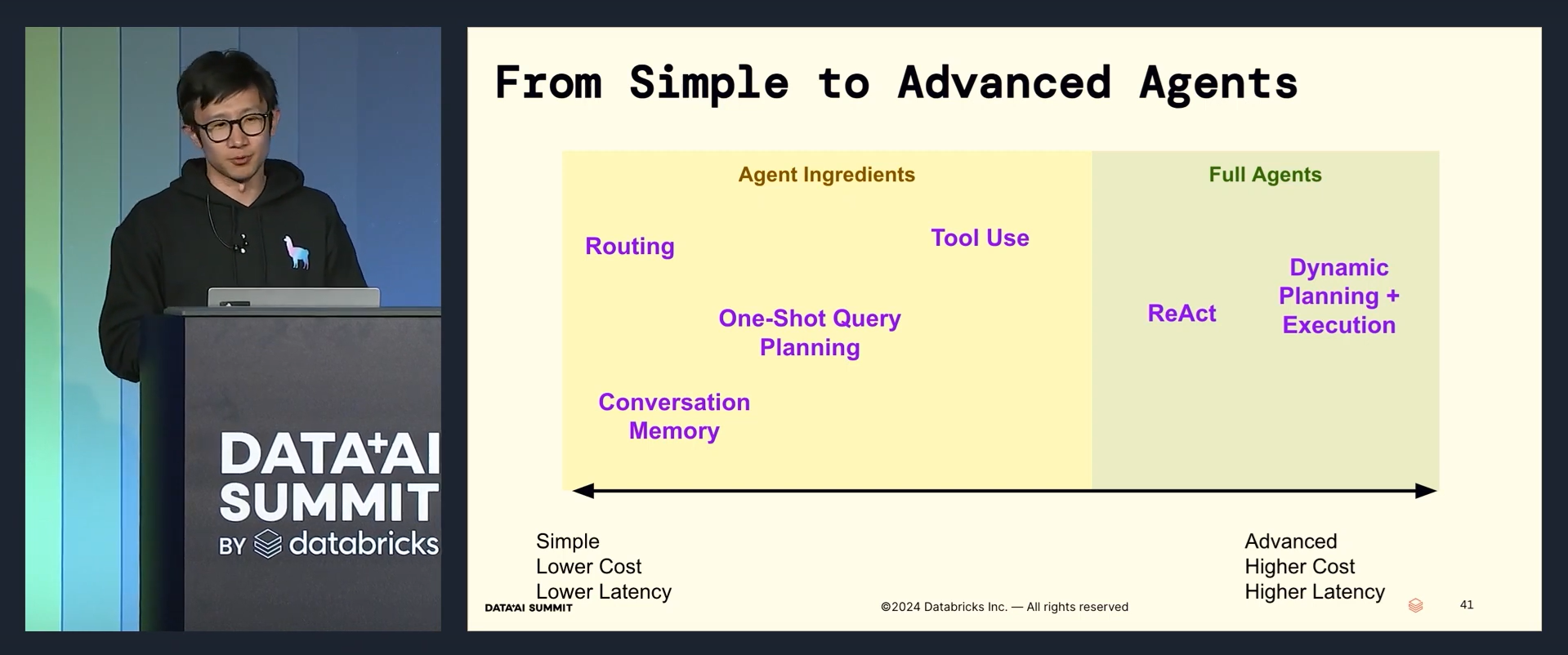
Simple, lower cost, and lower latency agent ingredients:
- Routing
- One-Shot Query Planning
- Conversation Memory
- Tool Use
Advanced, higher cost, higher latency full agents:
- ReAct (Reasoning and Action)
- Dynamic Planning + Execution
A compound multi-agent system has the benefit of combining multiples of these techniques, so that basic building blocks can boost each other’s capabilities cumulatively, or alternatively that less intelligent models can get coaching from higher level models.
Transparency – The Key of Trust
Agentic systems more often than not incorporate a flow of information, with data sources to scour, or files to be manipulated.
In all of our projects so far, end-to-end search pipelines were always part of the features list within or adjacent to the agentic solution itself. The web and search features (e.g. RAG, Text-to-SQL) are technically not a must for agents, but as highly requested quality of life additions, we felt we should dedicate a section to their transparency.
We have found that for reliability, clarity, and user trust, it's vital to see which sources the agents have used and how they arrived at their results.
Our systems provide this transparency in several ways within the user interface:
- During inference and loading, users can track the sources being utilized
- After the final output is presented, users can see the lifecycle of the data
- Questions are automatically routed to the appropriate component or level of the agentic system—and you can see each branch and component of the agentic workflow, making corrections or pivots much easier
While not as deep a concept as neural mapping interpretability, this approach of open workflow traceability is certainly great from a UX perspective.
Limitations of GenAI – Just Keep It Simple
Here's a golden rule for successful agents:
Use as little GenAI, and as many deterministic functions as possible.
Why?
These compound systems have an inherent weakness: many more points of failure than simpler setups.
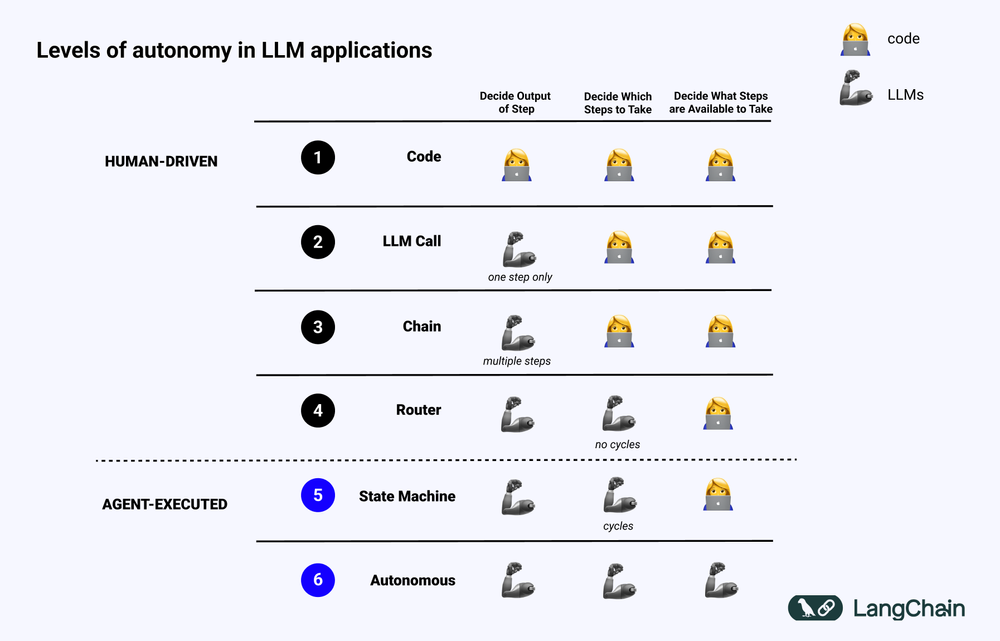
When you can use a simple method – you should! Deterministic algorithms are almost always preferred to non-deterministic generative AI. Some examples:
- When a script can do the job, you don't want a more unreliable LLM taking action
- When sequential reasoning suffices, you don't need tree-based decision making
That's why we use pre-defined tools such as py functions, code executors, chart generators, and so on—fool-proof methods in our architecture. These are essential for sending information between layers, allowing the Orchestrator to route efficiently with well-defined actions.
Addressing Common Concerns
Building agent-like systems is hard not because of their complexity, but mostly because of current LLM limitations, security risks, and reliability concerns.
Fixing these is a major focus on all of our projects. You can read our previous blog post about the most common LLM safety risks and ways to mitigate them.
As you increase the potential number of calls to LLMs, the probability of failure increases.
Another significant concern is latency: the more data sources, actions, decisions, routes, and models in a system, the longer it takes for the user to get their answer after a query.
How do we address these? Here are some basic steps everyone should follow:
- Limit the number of calls
- Implement validation steps to prevent data leaks and hallucinations
- Optimize architecture and functions to reduce latency
- Apply adequate data anonymization where necessary
- Establish monitoring and version control
- Conduct red-teaming and human-in-the-loop development
- Perform extensive user testing and education
Agent Reasoning Loops – Brains Behind The Operation
How do our agents make decisions? Each approach has its own strengths:
- Sequential: Generate the next step given previous steps (similar to chain-of-thought prompting, but automated)
- DAG-based planning (deterministic): Generate a deterministic DAG of steps. Replan if steps don't reach the desired state.
- Tree-based planning (stochastic): Sample multiple future states at each step. Run Monte-Carlo Tree Search (MCTS) to balance exploration vs. exploitation.
We'll explore agentic decision making and reasoning frameworks more deeply in a later article. Still, for the purposes of this overview, it’s beneficial to see the general options.
Towards True Agents
According to recent insights from OpenAI and Google DeepMind, we could be on the cusp of exciting developments in reasoning capabilities:
- OpenAI's roadmap suggests that out-of-the-box agent systems are beyond the scope of next-gen models, likely coming a generation later at the earliest.
- The next step towards this goal will be advanced reasoning.
- Google DeepMind's latest math-focused models, AlphaProof and AlphaGeometry, show great promise of advancing reasoning capabilities, and will be integrated into their Gemini LLM at some point in the future. Competitors are expected to use similar methods to transcend current limitations, and potentially achieve more autonomy.

So when will advanced agents arrive? We predict 2025-2026 at the earliest.
Does this mean our current cutting-edge multi-agent approach will become obsolete? Not necessarily.
The options presented above will become more streamlined, and surely easier to configure. However, we can only expect incremental updates and improvements to the current overall approach until full-blown AGI is here.
Furthermore, organizations relying on open-source, custom-built solutions (due to policy compliance or niche processes) will likely continue to prefer building their own solutions, which will continue to require the setup of a complete ecosystem in which the AI can truly thrive.
End-to-End Development – Beyond Data Science
The new standard of AI development goes well beyond the scope of data science teams. This more comprehensive approach integrates multiple domains:
- Data engineering
- Data science
- IT Infrastructure & Security
- Application development
- DevOps (AIOps)
We offer comprehensive support throughout the product lifecycle:
- Assessment (Counseling, PoC)
- Piloting (MVP)
- Production & Deployment
- Follow-up, updates, or upskilling for self-maintenance
Get free architecture blueprints from our latest projects, and boost your AI coding copilots’ reliability to enterprise-grade levels!

Ready to take your business to the next level? AI agents offer:
- Automation, augmenting the efficiency of select workflows
- Seamless blend of generative AI, machine learning, and reliable programming
- Transparency and security, especially compared to off-the-shelf language models
- Tailored solutions for your unique processes, from analysis to executive reporting


