


Reaping the benefits of emerging AI technologies is an increasing priority for nearly all players on the market right now. And when there is a gold rush, people are bound to jump into streams. So don’t forget to bring waterproof clothing, heavy-duty boots and a sturdy pair of gloves!
In this article, we will provide a top-down overview of threats that language models can pose when integrated into business environments, and the best mitigation practices to prevent these risks.
Threat Landscape
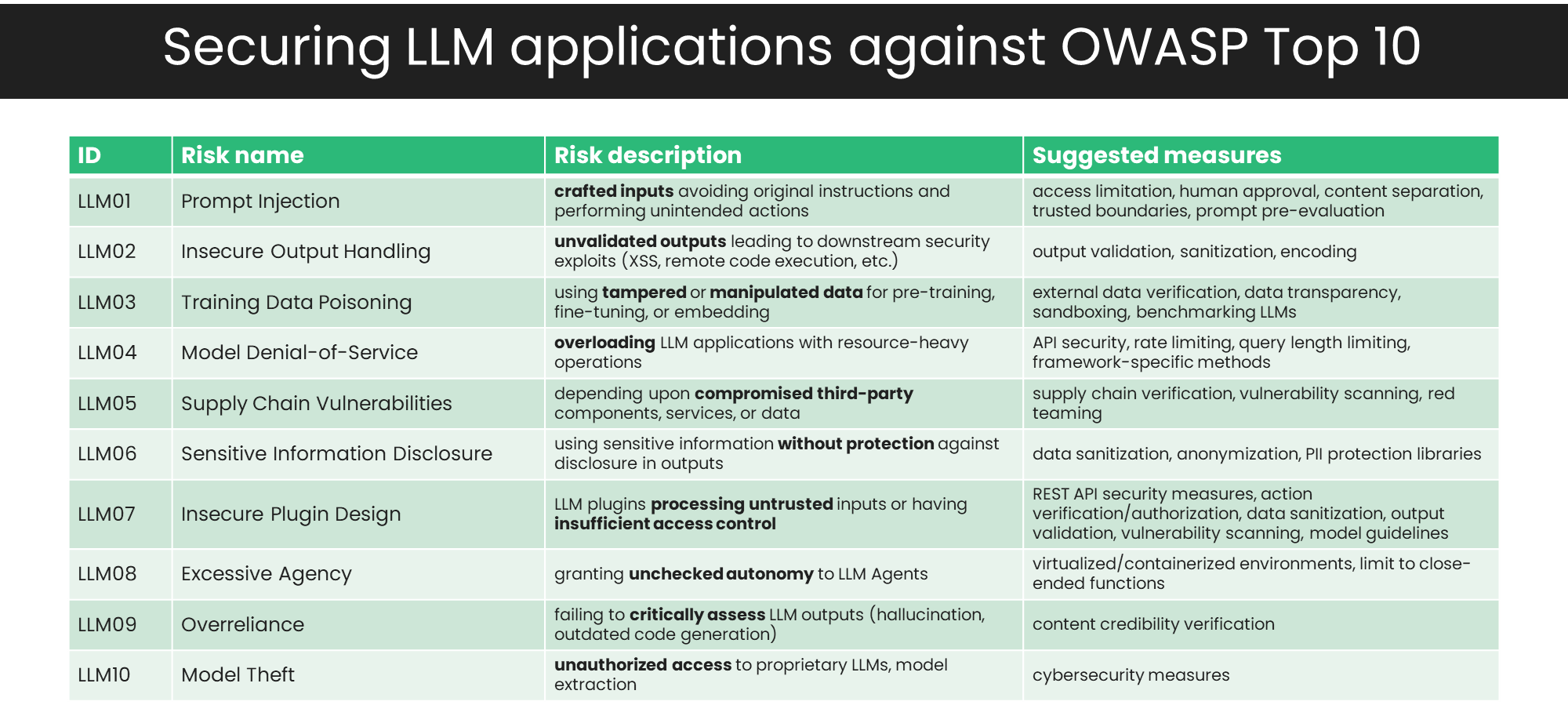
The threats against GenAI-augmented systems can be categorized into five main types:
- Model jailbreaks, hijacking, or poisoning
- Sensitive data extraction from or about the model (system prompt, embeddings, training data)
- Data collection from the wider IT ecosystem, accessed via the language model
- Overloading servers or overbilling via repeated mass-prompting
- Corrupting or scamming personnel working with your systems
Before detailing each of these, here are some valuable resources to explore:
- The MITRE ATLAS: A continuously updated matrix wiki of the threat landscape (https://atlas.mitre.org/matrices/ATLAS)
- Open-source AI community repositories containing various attacks against LLMs (e.g., https://git.new/llmsec)
- The OWASP Top 10 LLM Risks list (https://owasp.org/www-project-top-10-for-large-language-model-applications/)

Now, let's examine each threat type:
Prompt Injections
Maliciously crafted inputs that can lead a language model to perform actions outside of its intended role or disclose sensitive information. Various techniques exist, such as "character override" or “sidestepping” by going into roleplay with the model. In addition, "context exhaustion" or “accidental leakage” by exploiting the repetition penalty. Besides that, "prompt injection" or "token smuggling" by masking exploitative prompts inside hidden messages. These are all well-known and widely employed exploitation methods.
These are the most exploited vulnerabilities currently. However, most users are not driven by malicious intent at all, but merely having fun, while they make the models perform unintended actions.
Insecure Output Handling
This occurs when a person, program or plugin uses the output of a model without proper validation, potentially leading to security vulnerabilities.
But to some extent, this will always be a problem with advanced neural networks until we actually understand how they work internally – see the famous panda = gibbon adversarial attack.
It’s a massive catch 22. Sometimes, we use AI to solve problems that we don’t understand well enough to solve ourselves.
Training Data Poisoning
An attacker can manipulate the data used to train a model, causing it to produce inaccurate, biased or otherwise poisoned outputs.
The most famous recent example: a movement of anti-AI artists tried “poisoning” their own artwork with tools like Nightshade. The intended result was that image generators training on their art would output garbage pictures. This approach wasn’t really successful, but including poisoned data in publicly available datasets is a growing concern for many developers.
In classical data science, we used big training datasets lifted from publicly available sources (for example Kaggle) or provided by our clients. Data quality is paramount in selecting training data. These training datasets are now extremely vulnerable to data poisoning, because biases, false information or otherwise harmful code or content will be an integral part of our model.
These have various solutions, from using more secure synthetic data to patching in solutions for known poisoning approaches—but the issue should be on your radar.
Model Denial-of-Service
Attackers can overwhelm your model with requests, making it unavailable to legitimate users and/or racking up thousands of dollars in usage costs. This can be achieved through direct attacks or by exploiting the AI system to generate excessive requests.
DDoS attacks are pretty commonplace in the industry, but the cost aspect of LLM inference can really hurt, not just customer experience, but your wallet as well.
The easiest defense? Limiting token numbers, inference times and questions per user. Just don’t let the system scale outputs autonomously and without limits!
Supply Chain Vulnerabilities
Weaknesses in the software supply chain can also be exploited by an attacker who compromises a development tool like Langchain to gain access to AI applications. If malicious actors infiltrate the development process, they can build secret backdoors for themselves, which they can use after the model is fully deployed.
Recently, Linux almost released a new version with a malicious backdoor coded into it. The xz Utils backdoor was introduced into the open-source code over several weeks and was present in versions 5.6.0 and 5.6.1. It was caught last minute before going live, but the incident really brought the issue of supply chain vulnerability to the limelight.
The security of platforms like Azure, or Langchain, or proprietary language models may be not your responsibility, but if your operations are built on top of these solutions, their vulnerabilities become yours.
Sensitive Information Disclosure
A model may output confidential information unintentionally, posing a significant security risk.
Of course, we could train the model using sensitive data, but it risks the involuntary reveal of protected information, or even trade secrets. Spoiler alert: the best practices that solve this issue are anonymization and using synthetic data.
Insecure Plugins
Poorly designed plugins can be vulnerable to attacks, allowing unauthorized access or manipulation.
But a more common and mundane issue leads us to the next item on the list: vulnerability amplified by granting more agency than we should, which is a potential concern for plugins as well. For example, if we let AutoGPT delete emails, a misunderstood prompt can lead to emptying our mailbox instead of summarizing messages.
Excessive Agency
Granting a model too much control over a system can lead to unintended consequences, such as the AI making critical decisions without human oversight.
A crucial governance question: where in a process can AI have autonomy, and which steps need a human in the loop?
For example, a client was testing our PoC model, and asked the LLM what access rights they have. The model was optimized for Text-to-SQL, and recognized only the word “access” as something that it could use from the prompt. It generated a working grant_access code, that, if ran, could cause some serious headache to their IT sec department. Good thing we caught this during testing, but the incident highlighted the potential of a worst-case scenario. This same model—given excessive agency—could have executed the code itself and compromised the whole infrastructure.
Overreliance
People and processes that rely too heavily on language model outputs can become a vulnerability themselves. If the model is compromised, or its outputs are invalid for any reason, overreliance can lead to cascading failures.
If you want to schedule a doctor’s appointment, an AI agent would be much more efficient than a human assistant. How about making a diagnosis? There are many areas where AI could and should help decision making, but maybe a complete takeover isn’t feasible just yet.
Model Theft
Attackers may steal the model training data, parameters, or weights, scrape outputs, or make do with any other part of a system. Then, copying or delaying a competitor’s work, or abusing the array of vulnerabilities detailed above is quite trivial.
Securing Systems
IT ecosystems have many entry points for potential attacks and multi-layered aspects to their vulnerabilities, which obviously requires a complex and comprehensive approach to security. Organizations must adopt best practices and implement robust measures at every stage of the AI lifecycle, from prototyping to ongoing operations.
Some key best practices for securing AI systems include:
Pre-deployment
- Conducting risk assessments
- Red teaming exercises to identify vulnerabilities
- Evaluating data sources and suppliers to ensure data integrity and quality
- Anonymize sensitive data during training or replace them with synthetic data
- Internal security guidelines and governance principles for the workforce
In-operation
- Limiting model actions on downstream systems
- Anonymize sensitive data during operations
- Ensuring robust input validation and output sanitization
- Monitoring threats real-time and utilizing AI for detection and alerting
- Continuously educating team members on AI security best practices
If we strip these measures down to bare essentials, they can be summarized as:
- Monitoring
- Human in the loop
- Anonymization
- Limitations
- Cybersecurity
By adopting best practices and implementing measures for each threat type, organizations can significantly reduce the risks associated with Generative AI integration into their business processes and existing IT infrastructure.
Where does the responsibility fall?
As regulations are lagging behind rapid technological progress once again, many issues and threats are unclearly defined by law. In many cases, the scientific community, commercial players and the users themselves are acting on unofficial conventions right now.
But our experience, in conjunction with the trends we see in lawmaking as well as juristical rulings around the world, the fallout of risks will mainly impact organizations who are integrating AI technologies, and the developers themselves.
Those working in this space should prioritize accountability, security and ethical consideration during development, even if the current breakneck pace of progress calls for throwing these practices out the window in favor of quick wins. Choosing the safe path will pay off in the long run.
Conclusion
Most techniques currently seem harmless because Generative AI tools have not yet been widely deployed. However, as the field of AI continues to advance, and organizations accelerate their adoption, this could rapidly shift.
Focusing on practicality is very important—test solutions thoroughly as well as continuously monitor them after deployment. Organizations must prioritize security, educate their workforce and lay down governance policies that can secure their data, clients and personnel from the evolving threat landscape.
Staying adaptable and proactive in the face of emerging threats is key to ensuring the safe and successful integration of AI.
UPDATE: Check out our new, 2026 overview for enterprise AI security!


