


A new paradigm is now mainstream: reasoning models. This advanced form of language models represent a significant leap forward in AI capabilities, offering more than just text generation: they provide structured, logical thinking that mimics human reasoning processes. Let's explore what makes these models special and how they're changing the AI paradigm today.
What is AI reasoning?
Reasoning is the cognitive process through which we draw conclusions from available information, encompassing logical thinking and problem-solving. In AI terms, reasoning involves:
- Deductive reasoning: Drawing specific conclusions from general principles.
- Inductive reasoning: Forming generalizations based on specific observations.
- Abductive reasoning: Inferring the most likely explanation from incomplete data.
The significance of reasoning in AI is profound: it enables machines to simulate human decision-making and problem-solving abilities.
Unassailable logic
- Starting point #1: Witches burn.
- Starting point #2: Wood burns.
- Conclusion: Witches are made of wood.
- Starting point #3: Wood floats on water.
- Starting point #4: Ducks float on water.
- Conclusion: Therefore, if a woman weighs the same as a duck, she is made of wood, and thus a witch.

Witch scene https://www.youtube.com/watch?v=yp_l5ntikaU
The limitations of current LLMs
Large language models have already achieved impressive capabilities:
- Natural language understanding: Processing and generating human-like text
- Retrieval capabilities: Accessing vast information to provide relevant answers
- Basic reasoning: Solving simple logical tasks
However, they still struggle with complex reasoning challenges. When faced with multi-step problems requiring deep logical analysis, traditional LLMs often falter, producing plausible-sounding but incorrect results.

Example of a faulty output, demonstrated by the infamous “strawberry problem.”
Chain-of-Thought: the first step forward
One of the earliest approaches to improve reasoning was Chain-of-Thought (CoT) prompting: a technique that encourages models to generate intermediate reasoning steps before providing a final answer.

Advantages of Chain-of-Thought
- Increases transparency and accuracy in the model's reasoning process.
- Makes the "thinking" visible and verifiable.
Disadvantages of Chain-of-Thought
- Significantly more tokens used, increasing costs.
- Still relies on the model's inherent capabilities.
The birth of true AI reasoning models
Reasoning models take this concept to the next level. Unlike standard LLMs with Chain-of-Thought prompting bolted on, these are models specifically trained to:
- Think before answering, using dedicated <think> phases.
- Structure their reasoning explicitly.
- Verify and correct their own thought processes.

As DeepSeek researchers observed in their groundbreaking paper on the R1 model:
"These models first think about the reasoning process in their mind and then provide the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively."

The key insight is that by increasing inference compute—specifically by extending the thinking phase—accuracy improves dramatically. This seems to contradict traditional understanding of autoregressive processes, where generating longer outputs typically increases the probability of errors.
The paradox of reasoning models
This brings us to a fascinating contradiction. According to traditional understanding of autoregressive models (as highlighted by researchers like Yann LeCun), the error probability in large language models should increase with output length—a phenomenon known as "compounding error."

https://www.youtube.com/watch?v=OKkEdTchsiE
Yet reasoning models demonstrate the opposite effect. When given more "thinking time" (more tokens dedicated to reasoning), these models become significantly more accurate. This challenges fundamental assumptions about how large language models function and learn.
How reasoning models are trained
Creating a reasoning model involves several key stages that differ from traditional LLM development:
The complete pipeline (DeepSeek-R1 Example)
- Cold Start Phase: Begin with an existing pretrained model and fine-tune it on cleaned Chain-of-Thought outputs
- Reasoning Reinforcement Learning: Apply specialized RL techniques (like GRPO - Group Relative Policy Optimization) to reward sound reasoning
- Rejection Sampling SFT: Further fine-tune using only the best reasoning examples
- Diverse RL: Apply RLAIF (Reinforcement Learning from AI Feedback) to increase versatility
The key innovation: rule-based reinforcement learning
Unlike traditional supervised fine-tuning (which teaches models to imitate specific reasoning patterns), reasoning models employ reinforcement learning in easily verifiable domains:
- They let the model attempt to solve problems using its own Chain-of-Thought approach.
- The model receives rewards based on reaching correct conclusions, not following prescribed reasoning paths.
- This encourages exploration of diverse reasoning strategies.

This approach is particularly effective because:
- Verification is simpler than generation: It's often much easier to check if an answer is correct than to produce the correct reasoning path
- Binary feedback promotes learning: Clear right/wrong signals in domains like mathematics provide strong learning signals
- Format consistency is enforced: Models learn to maintain proper <think> and <answer> structures
The Aha Moment: emergent capabilities
Perhaps the most fascinating aspect of reasoning models is what DeepSeek researchers call the "aha moment"—when the model, trained with reinforcement learning, spontaneously develops self-correction mechanisms:
- Backtracking: Recognizing dead-end reasoning paths.
- Self-reflection: Questioning its own assumptions.
- Re-evaluation: Reconsidering earlier approaches.
- Exploring alternative solutions: Testing different problem-solving strategies.

These capabilities emerged without explicit training, demonstrating how reinforcement learning can yield behaviors beyond what was directly programmed.
Generalization: the true test
The million-dollar question for reasoning models is generalization: can reasoning skills learned in closed, reward-rich domains (like mathematics) transfer to open-ended problems?
Research shows a stark contrast between supervised fine-tuning and reinforcement learning approaches:
- SFT models: Perform well on in-distribution problems but fail catastrophically on out-of-distribution challenges.
- RL-trained reasoning models: Maintain reasonable performance even on novel problem types.
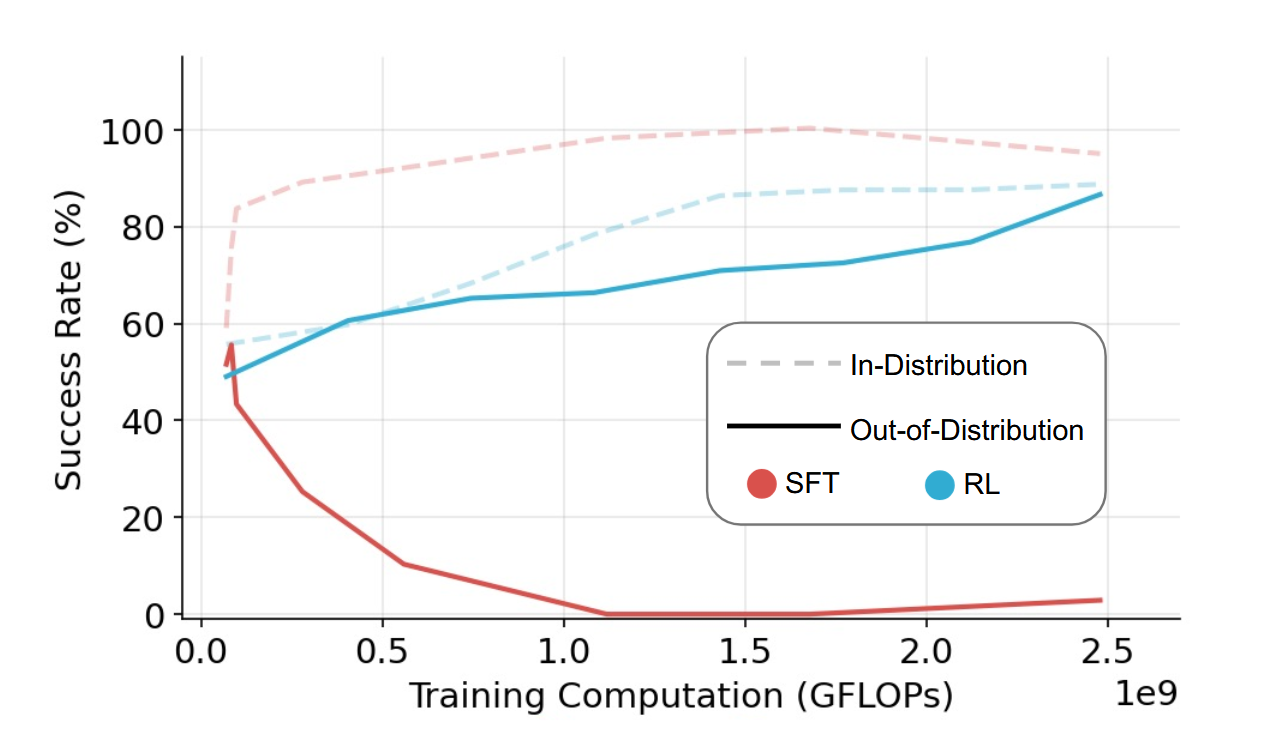
https://arxiv.org/pdf/2501.17161
This transfer learning capability is critical for the real-world utility of reasoning models. As Andrej Karpathy noted, the success of reasoning models depends heavily on whether "knowledge acquired in closed reward-rich domains can transfer to open-ended problems."
The current state of play: available AI reasoning models
Several leading reasoning models are now available, each with different capabilities:
| Model Provider | Model | Public Access | Math Performance (AIME) | Science (GPQA) | General Reasoning (ARC) |
| OpenAI | o1-mini | Chat only | 63.6% | 60% | 9.5% |
| OpenAI | o1 | Chat only | 83.3% | 78.8% | 25-32% |
| OpenAI | o3-mini | Chat & API | 60-87.3% | 70.6-79.7% | 11-35% |
| OpenAI | o3 | Through products | 96.7% | 87.7% | 76-87% |
| DeepSeek | R1 | Chat & API/Weights | 79.8% | 71.5% | 15.8% |
| Gemini 2.0 (Flash Thinking) | Chat & API | 73.3% | 74.2% | - |
Notably, these models also show impressive performance on coding tasks, with most achieving high scores on platforms like Codeforces and SWE-bench verified challenges.
How to prompt reasoning models
Prompting reasoning models differs significantly from working with traditional LLMs:
| Technique | Traditional LLMs | Reasoning Models |
| Zero-shot prompting | Weak performance | Good performance |
| Few-shot prompting | Significantly improves accuracy | Can actually harm reasoning performance |
| RAG (Retrieval-Augmented Generation) | Recommended | Minimally helpful |
| Structured prompts (XML tags) | Helpful | Essential |
| Chain-of-Thought prompting | Very beneficial | Not recommended, may interfere with built-in reasoning |
| Ensemble methods | Improves performance | Minimal improvement |
As the team at PromptHub notes: "Reasoning models work best when given clean, direct instructions without examples that might constrain their thinking process."
What's next: the future of AI reasoning models
Looking ahead, several key developments seem imminent:
- Product-focused delivery: As OpenAI has demonstrated with Deep Research, advanced reasoning capabilities may increasingly be packaged as complete products rather than raw API access.
- The rise of agents: 2025 is shaping up to be the year of AI agents, with offerings like OpenAI's Operator, Claude's Computer Use, and Claude Code leveraging reasoning capabilities.
- Model distillation: Making reasoning abilities available in smaller, locally-runnable models.

What's still missing?
Despite their impressive capabilities, reasoning models still have significant limitations:
- They remain fundamentally language models with statistical foundations.
- They lack true multimodality (beyond text).
- They don't have grounded knowledge in physical reality.
- They can't learn in real-time during inference like humans.
- They lack environment-adaptive capabilities.
You can read more about solving these shortcomings in our previous blog: Path to AGI.
Potential applications and impact of reasoning models
The practical applications of reasoning models are vast.
In daily work
- Tackling complex reasoning-intensive workplace problems.
- Reducing the need for extensive prompt engineering.
In development workflows
- Enabling truly agentic systems rather than static workflows.
- Making high-quality models available for on-premises deployment.
In software development
- Raising the abstraction level of programming with tools like Cursor and Replit.
- Supporting privacy-preserving local model usage through tools like Continue and Cline.
Broader implications
The rise of reasoning models signals several important shifts in AI development:
- A new scaling paradigm: pretraining data + pretraining compute + inference-time compute.
- Accelerated release cycles and innovation.
- Superhuman capabilities becoming accessible.
- Full task automation becoming feasible.
- Initially decreasing LLM development costs.
- Increasing value of specialized AI chips (Jevons paradox).

Conclusion
Reasoning models represent a significant evolutionary step for artificial intelligence. By incorporating explicit reasoning processes and leveraging the power of reinforcement learning, these models are pushing the boundaries of what AI can accomplish.
While we're still in the early days of this technology, the trajectory is clear: AI systems that can think through problems step by step, evaluate their own reasoning, and arrive at solutions through logical deduction are becoming reality. The implications for industries, knowledge work, and software development are profound and far-reaching.
On the one hand, a challenge arises as we figure out ways to avoid runaway LLM costs. On the other hand, though, as these technologies continue to develop, we're likely to see an increasing shift toward agentic systems that can operate with greater autonomy and tackle increasingly complex reasoning challenges.

Sources
Language Models are Few-Shot Learners
Instruction Tuning for Large Language Models: A Survey
Training language models to follow instructions with human feedback
Deep reinforcement learning from human preferences
Constitutional AI: Harmlessness from AI Feedback
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Model distillation – Improve smaller models with distillation techniques
DeepSeek R1 Distill Now Available in Private LLM for iOS and macOS
Reward Hacking in Reinforcement Learning
OpenAI o3 and o3-mini—12 Days of OpenAI: Day 12
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
Introducing SWE-bench Verified
OpenAI o3 Model Is a Message From the Future: Update All You Think You Know About AI
Prompt Engineering with Reasoning Models
Reasoning models – Explore advanced reasoning and problem-solving models
OpenAI Scale Ranks Progress Toward ‘Human-Level’ Problem Solving


