


The scope of migration projects: code is only the beginning
Data platform migrations are deceptively simple in goal, but complex in execution.
They are simple because the ultimate objective is clear: produce the same output from the same input as the current system. They are hard because you expend significant energy and take on risk for "no change" in the immediate business result.
While the core task of pipeline transformation often dominates effort, a successful migration requires taking care of the entire data ecosystem. This is about building a new, future-proof system that works (preferably at least as well as the original), not just a ported one.
The scope of a data platform migration must include all supporting elements as well. If these are missed, the new platform will fail, regardless of how perfectly the core code was translated:
- Source and downstream connections: Establishing and managing the links to data inputs and consumers.
- Orchestration: Devising the mechanics of running the individual pieces, composing the new pipelines, and handling triggers. This often requires significant groundwork, as the platforms often use rather different plumbing.
- Data Catalog: More often than not, modern migrations prompt for (if not outright require) that a comprehensive component inventory is created in the project. The more legacy the source platform is, usually the less it is readily available at the outset.
- Data environment management: Setting up non-processing components like access control, the data catalog, and ensuring proper logging and auditing, and monitoring and alerting.
- Data backfilling: Managing the safe and validated process of loading historical data into the new platform to ensure business continuity.
- Performance optimization: Once functional, the project shifts to measuring performance and optimizing the code, the overall Directed Acyclic Graph (DAG), and the right-sizing of the infrastructure to balance run times, data latency, and costs.
Migration methodology to reduce risk and cut time by 70%
Complexity drives the key project factors: cost, duration (deadline), and risk. To control these, an established, rigorous, and repeatable migration methodology is non-negotiable.
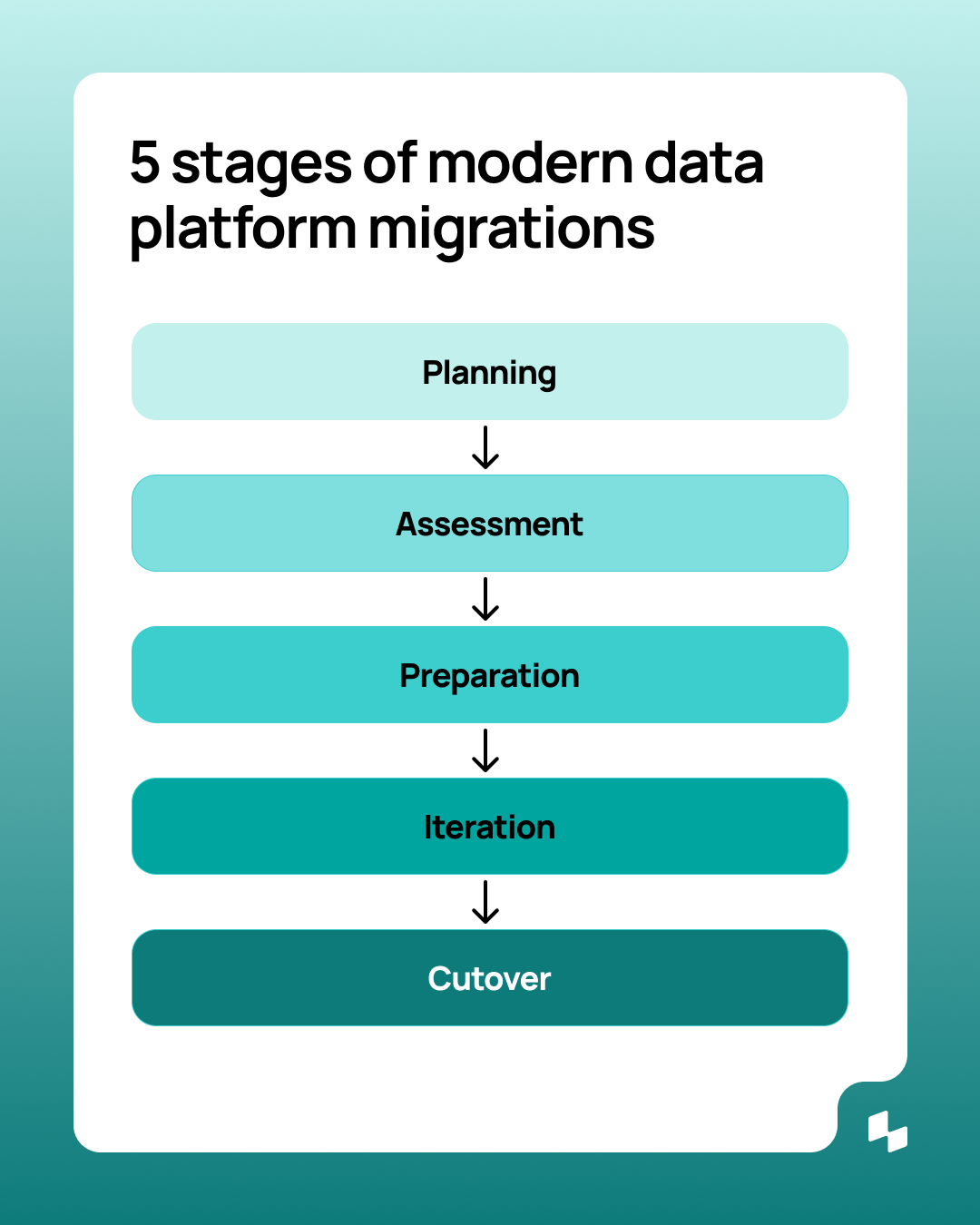
We break down the migration journey into five non-linear phases designed to de-risk the process:
5 phases to migrate data platform effectively
1. High-level planning
Define the overall situation, technical and business goals, and known constraints. This yields a ballpark project size.
2. Detailed assessment and planning
This is the deep dive. Technical assessment determines the extent of the migration (artifacts, complexity), technical environments, external dependencies, and local specialties (e.g., custom frameworks). This information is crucial for accurate resource and time estimation and determines the optimal migration strategy (e.g., whether to lift-and-shift or rewrite).
3. Preparation
The readiness phase includes onboarding resources, setting up the target environment, and defining a known baseline of test data. Crucially, this stage involves Mini-PoCs (Proofs-of-Concept) on the most complex or repeated steps to confirm that mass migration efforts will be efficient and that all tooling is set up.
4. The iterate loop: migrate, test, correct
The workhorse phase, where each pipeline component is processed and immediately tested. Progress is continuously monitored and plans refined based on real-time feedback. In later stages, usually some optimizations are introduced: either through tuning the resulting code, or through tuning the target platform (different indexing, clustering, etc.), or even through structural changes (i.e., splitting certain transformations).
5. Finalization and cut-over
Data gets backfilled from the source system. The final test involves a Parallel Run, where both the old and new systems process the same input and outputs are automatically cross-checked. The project concludes with planning the Cut Over Process (phased or "Big Bang"), coordination with stakeholders, and "Go Live".
How to automate data platform migration with AI
Modern data migration projects rely heavily on automation to shift from a manual, error-prone effort to controlled, repeatable processes. This is especially true when leveraging specialized AI in three key areas:
Discovery and assessment (limited scope)
AI can be used here to support the human analyst by analyzing code complexity, suggesting dependencies, and calculating the structure of the DAG. Automation here nicely supports the human expert, cutting both work and duration significantly.
Code conversion (maximum impact)
This is where AI delivers its biggest win.
Translating between highly similar source and target languages in a lift-and-shift approach can be near-perfect with AI.
For complex language-to-language transformations (like SAS to PySpark or SQL), a dedicated AI translation engine can cut the conversion time by as much as 70%.
By doing the heavy lifting, the human task shifts from writing new code to reviewing, correcting, and optimizing high-quality, auto-generated code, drastically accelerating the project timeline.
There are two more major refactoring steps many migrations demand:
- Code standardization: Unifying disparate coding styles into a single, standardized format.
- Structural implementation: Applying required architectural patterns, like inserting logging mechanisms or security calls, into every piece of ported code automatically.
Both of these need bespoke prompting and context engineering, but can be hugely automated via LLMs.
Automated validation and testing (focused scope)
Testing is the most tedious and critical step, and automation is essential. However, the role of AI is very limited in the core of lift-and-shift migrations.
The fundamental requirement in a lift-and-shift is functional equivalence: the new system must produce the exact same output as the old one for the same inputs. This means table-for-table, row-for-row, cell-for-cell exact matches must be compared.
Automation is key to running these comparisons quickly and repeatedly. But the core logic of the diffing process is procedural. AI may help in cases when matches are not exact but functionally equivalent (e.g., the number of decimal places in the source and target system differ beyond significance).
The use of automation here is primarily for:
- Structural comparison: Automated checks for table/view structure (preventing missing columns or incorrect data types).
- Content comparison: The automated diffing of data output between the two systems, reporting variances for human review.
From reactive to proactive: Governing the new data stack
A migration to a modern data platform is the ideal time to bake in strong operational cadence and governance. This shift has become a strategic necessity, not a nice-to-have, to manage risk.
The rush to deploy often treats governance as "pointless fussing" (as we noted in our post on AI agent governance). The solution is governance that is effective, heavily streamlined, and automated.
Key pillars of proactive data governance include:
- Establishing identity and ownership: Tracking every data asset's purpose, capabilities, and access scope, along with technical and business ownership.
- Maintenance of entity metadata: AI thrives on metadata (like description/business definition, lineage, value sets, relationships, usage patterns, etc.); a migration is a great opportunity to create or review and enrich these. Fortunately, many of these can be very well automated or augmented by AI.
- Strict access and permissions: Enforcing the least-privilege principle for all connections. Sloppiness in the name of speed is a security risk that is rarely fixed later.
- Observability and auditability: Logging every decision, action, and data source touched to support audits and human review. This requires automatic monitoring with a keen eye for suspicious activity.
Conclusion
Data platform migrations may seem like they deliver "no change," but that is a dangerously narrow view. By implementing a robust methodology and leveraging automation (especially where AI can deliver massive gains), you build a faster, more governed, and more resilient foundation.


