


It's 9 a.m. You open Slack. Overnight, a scheduled dbt job failed: three tests red. One is a uniqueness constraint on SKU codes. Another is a null check on order line items. The third is something downstream that probably cascaded from one of the first two.
You pull up the run results. You dig into the SQL. You check if the data looks wrong or the test logic is wrong, you go upstream... You cross-reference with that one Notion doc your teammate wrote six months ago about how SKU mapping works. You realize it's a new SKU that needs to be added to a config file. Twenty minutes for a one-line fix.
The other two failures? One is a source data issue, a vendor system sending duplicates. Nothing you can do in code. You draft an email to ops. The other resolves itself once you fix the SKU mapping.
Total elapsed time: maybe an hour. The fix itself took two minutes. The other fifty-eight were spent gathering context for work that required none of your expertise. Adding a value to a list. Updating a filter. Chasing down a source system issue for the third time this month.
It's not hard work. It's tedious work. And it compounds: every hour spent on routine triage is an hour not spent on the work that actually moves the business forward.
This happens every week. Sometimes multiple days in a week.
We decided to stop doing it manually.
How it started
Our client is a technologist, genuinely open to AI adoption, not just in the "we should leverage AI" corporate-speak sense. We'd been using AI coding agents like Cursor for some time already, and it's highly encouraged for the engineers to do so. Sometime in the second half of 2025, he said something that stuck with me:
"I wish that some day I'll wake up in the morning and there will be a PR ready to be reviewed about the dbt job failure."
At the time, I thought it was a nice vision but not realistic. The models weren't there yet. You could ask an LLM to explain a dbt test failure and get a plausible answer. But asking it to actually fix the code, verify the fix, and open a PR? That would produce hallucinated SQL, phantom column references, and commits that broke more than they fixed.
Then, toward the end of 2025, a new generation of models dropped, specifically GPT 5.2 Codex and Claude Opus 4.5. Something clearly shifted. The models didn't just get incrementally better at code. They got better at following structured instructions reliably. They could hold a multi-step workflow in context, use tools correctly, and produce code that actually ran.
Right before the new year, I went back to him and proposed we try building it. That's how it started.
It took a couple of months. Initially, I tried to build a custom agent from scratch: my own orchestration loop, tools, calls, retry logic. I quickly realized I was reinventing what products like Claude Code, Cursor CLI, and Codex already do in headless mode, and doing it worse. So I pivoted: use an existing AI coding agent as the engine, and focus my effort on everything around it: the context preparation, the guardrails, the workflow structure.
That turned out to be the right call.
What we built: an agentic system for data pipeline ops
We built a system that sits between our dbt Cloud jobs and our engineering team. When a scheduled dbt job fails, a webhook fires. Our system catches it, downloads the failure logs, consults an internal knowledge base, spins up an AI coding agent in a sandboxed environment, and asks it to diagnose and fix the problem.
If the fix is a code change (add a SKU to a mapping, update a filter, adjust a macro), the agent applies it, verifies it passes in a dev environment, and opens a pull request. If the problem is in the source data, the agent documents the root cause along with diagnostic queries, drafts a plain-English summary for the relevant stakeholder, and files a report.
The engineer wakes up to one of two things: a PR ready for review, or a report explaining what happened and who needs to act on it.
The agent only does the thinking
One design decision shaped everything: the AI agent only handles diagnosis and fixes. Everything else is done programmatically.
Downloading run logs, fetching the knowledge base, cloning production data to a dev sandbox, extracting failures into a compact summary, creating the git branch, posting to Slack, opening the PR: all plain Python and shell scripts. No AI involved (except of course in the creation of said scripts).
The agent could have done all of these things. Modern AI coding agents can make API calls, run shell commands, parse JSON. But every task you give the agent is a task where it can hallucinate, take a wrong turn, or waste context tokens figuring out something that's deterministic.
Context is still scarce. Every token the agent spends on boilerplate (parsing API responses, figuring out auth, handling edge cases in data fetching) is a token not spent on the actual problem: understanding why a test failed and how to fix it.
So we pre-compute everything. By the time the agent starts, it has a clean JSON file with just the failures, a markdown file with the full knowledge base, a cloned dev environment ready for testing, and a structured runbook telling it exactly how to proceed. What it does get is a dbt MCP server, which gives it clean, high-level tools for running models, executing tests, and exploring lineage, without needing to figure out CLI syntax or parse raw output. The agent's world is small and well-defined.
The knowledge base makes it predictable
Our team maintains a Notion knowledge base documenting known test failures and their remediation steps. Things like: "If unique_dim_sku_sku_code fails, add the new SKU to sku_map in dbt_project.yml." Step by step, explicit, deterministic.
We pre-fetch this entire knowledge base and hand it to the agent as context before it starts diagnosing. The agent searches it first, before doing anything else. When there's a match, it follows the documented fix exactly. When there isn't, it investigates from scratch and documents its findings.
This might sound like a minor implementation detail but it's not. It's one of the most important design decisions in the system. LLMs are non-deterministic by nature. Given the same input twice, they might take different diagnostic paths, try different fixes, or reach different conclusions.
The knowledge base tames this. When a KB entry exists for a failing test, the agent isn't reasoning from first principles. It's executing a documented procedure. The success rate for KB-matched failures is much higher than for novel ones. It's the difference between asking someone to "figure out what's wrong" and handing them a checklist that says "do steps 1 through 4."
The system also gets better over time in a way that's transparent and controllable. When we encounter a new failure pattern, we don't retrain a model or tweak prompt engineering. We add an entry to Notion. A human writes down the fix in plain language. Next time that test fails, the agent follows the new entry. The feedback loop is a wiki edit, not a machine learning pipeline.
Tribal knowledge, the kind that lives in one person's head and gets shared over Slack DMs, becomes executable. The Notion page isn't documentation. It's a decision tree that runs automatically.
How this agentic system actually works
The system has two components: a lightweight webhook receiver and a heavier analysis job.
The webhook receiver is a small service that catches dbt Cloud webhook events. It validates the request, checks whether the failure is from a scheduled run, and if so, triggers the analysis job asynchronously. It responds in under a second.
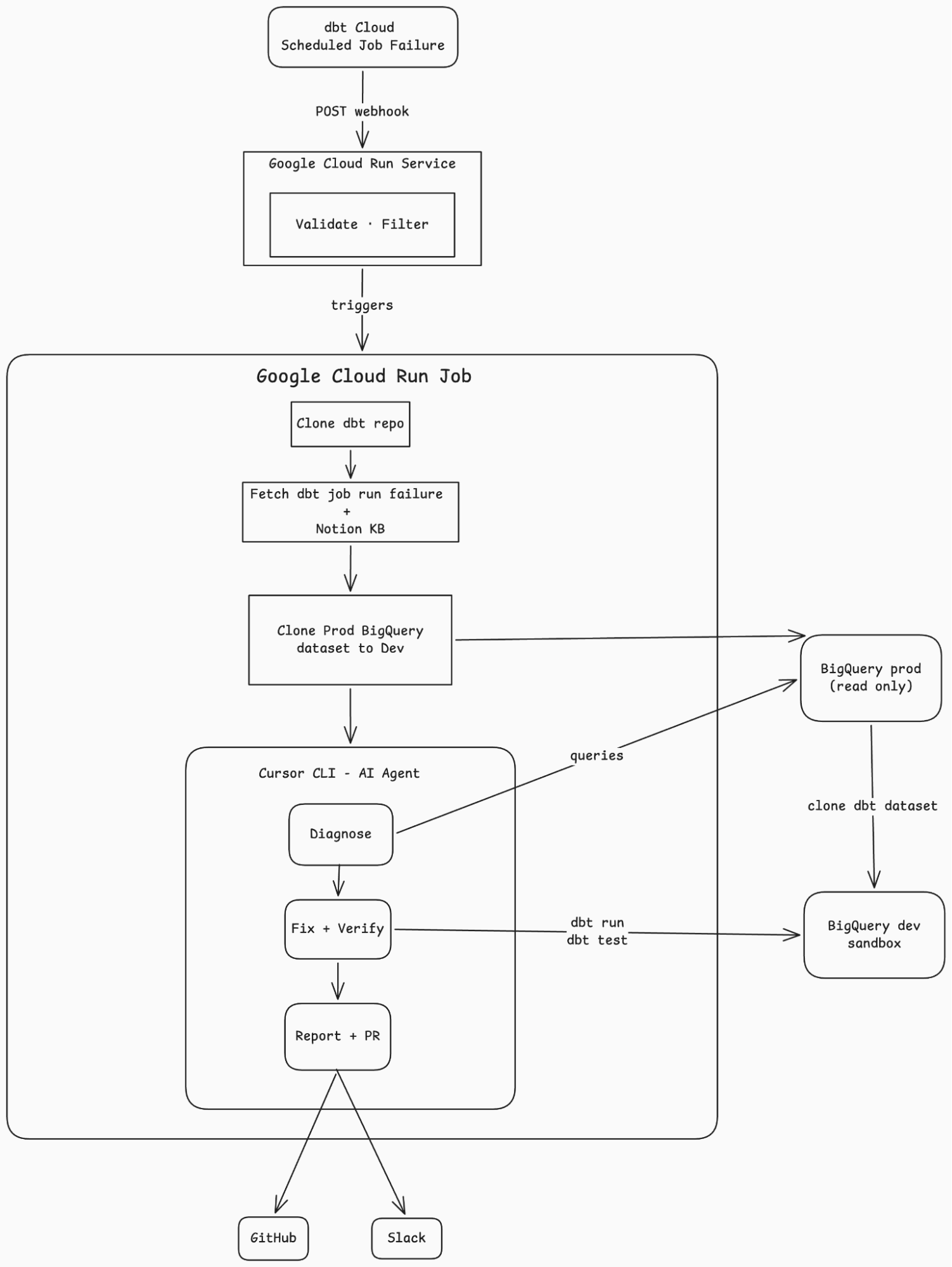
The analysis job is a containerized process that does the real work:
- Clones the dbt repository
- Downloads the run artifacts from dbt Cloud
- Extracts just the failures into a compact summary (the full run results can be massive; the agent only needs the failed tests)
- Fetches the Notion knowledge base and renders it to markdown
- Clones production data into a sandboxed dev environment
- Hands all of this context to an AI coding agent with a structured runbook
The agent then works through an eight-step workflow: read the failures, search the knowledge base, analyze dependencies in the DAG, investigate the data if needed, apply and verify fixes, generate a report, and for code fixes, open a pull request.
Every failure gets classified as one of two types:
CODE means something the agent can fix in the dbt project. A missing SKU in a mapping variable. A filter that needs updating. A macro that needs adjustment. The agent applies the fix, runs the test in the dev sandbox to verify it passes, and includes it in the PR.
SOURCE means something that requires action outside the dbt project. Bad source data. A vendor system sending duplicates. An integration dropping records. The agent can't fix these in code, so it documents the root cause, suggests next steps, and drafts a non-technical email for whoever owns the source system.
This classification happens early and it's deliberate. It prevents the agent from papering over data quality issues with code workarounds. If the data is wrong, the right fix isn't a more creative WHERE clause. It's a conversation with the team that owns the data.
Why guardrails matter more than the AI
Agents can improve operational efficiency in data ops, but only with the right guardrails in place.
So the most important design decision wasn't choosing which AI model to use. It was deciding what the agent is not allowed to do.
Production is read-only (enforced by BigQuery roles). The agent can query production data for diagnostics, but all execution, every dbt run, every dbt test, happens in a sandboxed dev environment with cloned data. The agent cannot modify production.
The knowledge base takes precedence over creativity. If the Notion KB has a documented fix for a specific test, the agent follows it. It doesn't get creative. It doesn't try a different approach. It does what the team said to do. You know exactly why it made the fix it did.
Fix upstream, not downstream. When multiple tests fail, the agent is prompted to find the root cause and fix it there. A single upstream fix often resolves several downstream failures at once. Without this, the agent's instinct is to patch each failing test individually, which means more code changes, more noise in the PR, and fixes that mask the actual problem.
Source issues are report-only. When the agent classifies something as SOURCE, it documents and escalates. It never applies interim mitigations in code. No temporary filters. No workarounds. The failure stays visible until the root cause is addressed. Sweeping source data issues under code fixes is how data quality erodes silently.
An AI agent with full access and no constraints is a liability. An AI agent with structured inputs, sandboxed execution, and clear boundaries is a tool.
What we learned
Most recurring dbt failures are boring
A new value that needs to be added to a list. A filter that needs to include a new category. A macro that doesn't handle an edge case. Five-minute fixes that require thirty minutes of context-gathering. That's the profile of work worth automating.
The knowledge base matters more than the model
Anyone can wire up an AI agent to a codebase. What makes this system work is the curated knowledge base that encodes how our specific team handles our specific failures. The AI is interchangeable. The knowledge base is not.
Classification is the hardest part
Deciding whether a failure is CODE or SOURCE requires judgment. The agent gets this right most of the time when given enough context, but it's not perfect. That's why the output is a PR for human review, not an auto-merged commit.
What's next
The architecture pattern here (structured prompt, pre-computed context, sandboxed execution, human review) is not specific to fixing dbt test failures. It works for any bounded code transformation task.
The obvious extension is feature development. The trigger becomes a spec document instead of a webhook. The context becomes the spec, and the output becomes a feature PR with implementation notes instead of a fix PR with a report.
That's probably where we're going next. The biggest lesson from this project is that the AI agent performs well for data pipeline ops when the problem is well-defined. For test remediation, the "spec" is the failing test itself: a clear error, compiled SQL, a pass/fail outcome. The agent knows exactly what success looks like because the test tells it.
Feature development doesn't come with that for free. You have to build it in. The spec document has to be tight: no ambiguity in what needs to happen, a clear definition of done, and an explicit description of how to validate the result. If the agent can't verify its own work, you're back to hoping for the best. The same principle applies: constrain the problem, pre-compute the context, define what "correct" looks like. The less room you leave for interpretation, the more reliable the output.


