


Databricks AI Dev Kit: From Prompt to Deployed App in 15 Minutes
Databricks AI Dev Kit gives your coding agents the skills and tools to build full apps on your workspace fast. Here's what's inside and how to get started.

This article is part of the short series. Part I. deals with demonstrating the strengths of Superset and how it’s situated in the diverse dataviz market, while the upcoming Part II. will discuss our experience in implementing and testing Superset on the pipeline illustrated with the figure below.
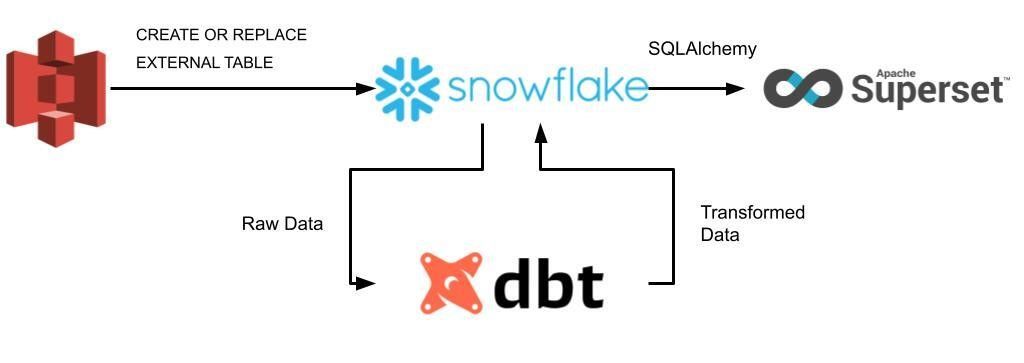
How we set up our infrastructure
When we talk about interactive data visualization, especially in the context of modern data stacks (e.g. data streamer (Stitch, Fivetran, Airbyte) + centralized cloud storage (AWS, Azure, GCP, Snowflake, Databricks) + transformation tool (dbt) + BI platforms), proprietary tools pop into our head such as Tableau, Power BI, and more recently Looker. These were considered as the mainstream solutions for quite a while, but now, emerging open-source alternatives are hungry enough to beat the market with their simplicity and cost-friendly approach. Among these promising technologies, Apache Superset is set to challenge its competitors in many ways, therefore, Hiflylabs closely monitors the roadmap of the project.
Given the maturity and dynamism of the BI market, consolidations are more frequent than ever. Over the past few years, other commercial tools were acquired by companies such as Tableau by Salesforce, Looker by Google Cloud, or Periscope by Sisense, which can infer the risk of vendor lock-ins forcing customers to migrate and rebuild their assets (e.g. Chart.io was downsized and shut down by Atlassian). Conversely, open-source platforms such as Superset avoid vendor lock-ins since you can both switch between commercial open source (COSS) vendors, and host it yourself on-premise. A good example for the former would be Preset (founded by the creator of Superset, Max Beauchemin), who offers a hassle-free and fully-managed cloud SaaS service to the platform.
Well, as the name indicates, Superset started in the Apache incubator back in 2016 and quickly became one of its top priority projects coinciding with the recent stable release at the beginning of 2021. It’s a modern, lightweight, cloud-native, free, and open-source BI web application with an advantageous SQLAlchemy python backend, making it scalable and compatible with almost any database technology speaking SQL. To reflect its increasing popularity, Airbnb, Twitter, Netflix, Amex, and many other companies have already started incubating Superset in their workflows, while Dropbox managed to successfully exploit its advantages at an enterprise level. In addition, the growing community behind Superset further strengthens the argument that there is an undeniable potential in our sight.
Superset essentially stands on three main layers:
We have seen many instances for pairing Looker with dbt, but the following arguments made us advocate for Superset:
Let’s see a case study on how Superset was chosen to be implemented into enterprise-level production!
The table below was retrieved from a Dropbox article on Jan 19, 2021. Long story short, they desired to find one particular BI tool to replace multiple other solutions. The main emphasis was on the security, user-friendliness, maintainability, flexibility, and extensibility of the platform. Their choice also landed on Superset as it was the best match for their specific internal needs. As a part of their decision-making process, they provided a comparison table that shows that Superset is superior compared to its peers in terms of the number of features and compatibility.
Dropbox explained ditching Metabase with the argument that it's developed in Clojure rather than Python, while to their knowledge, it has shortcomings from many additional aspects compared to Superset, for example, it has less authentication and data backend support. Since Dropbox has many strong Python developers, they decided to pursue Superset instead of Metabase.
Just as other tools, Superset also has its limitations.
Did Superset spark some interest in you or it still falls short of being a credible solution to your pipeline? What are the missing features which would elevate the product to a day-to-day alternative for you? Make sure that your voice is heard in the comment section below! Also, stay tuned for the second part of the series!
Son N. Nguyen - Data Engineer
Explore more stories
Databricks AI Dev Kit: From Prompt to Deployed App in 15 Minutes
Databricks AI Dev Kit gives your coding agents the skills and tools to build full apps on your workspace fast. Here's what's inside and how to get started.

Why B2B UX is a Security Strategy
Every time a user leaves your B2B product to complement their work with other tools is a risk. Let’s explore why data leaks happen due to bad UX practices and how you can avoid them.

Agentic System for DataOps: Building Self-Healing dbt Pipelines
Engineers spend hours resolving job failures, most of it is gathering context. We built an AI agent for data ops to cut this waste. Currently in production, with guardrails and grounded in KB.